DALL-E, DALL-E2 and StoryDALL-E
[story-dalle multimodality clip dalle2 diffusion text-image glide dall-e2 deep-learning storydall-e story-telling image-synthesize unclip dall-e This my reading note on Zero-Shot Text-to-Image Generation (aka, DALL-E), its extension Hierarchical Text-Conditional Image Generation with CLIP Latents (aka, DALLE-2 or unCLIP) and StoryDALL-E: Adapting Pretrained Text-to-Image Transformers for Story Continuation. DALL-E is a transformer generating image given captions, by autoregressively modeling the text and image tokens as a single stream of data. StoryDALL-E extends DALL-E by generating a sequence of images for a sequence of caption to complete a story.
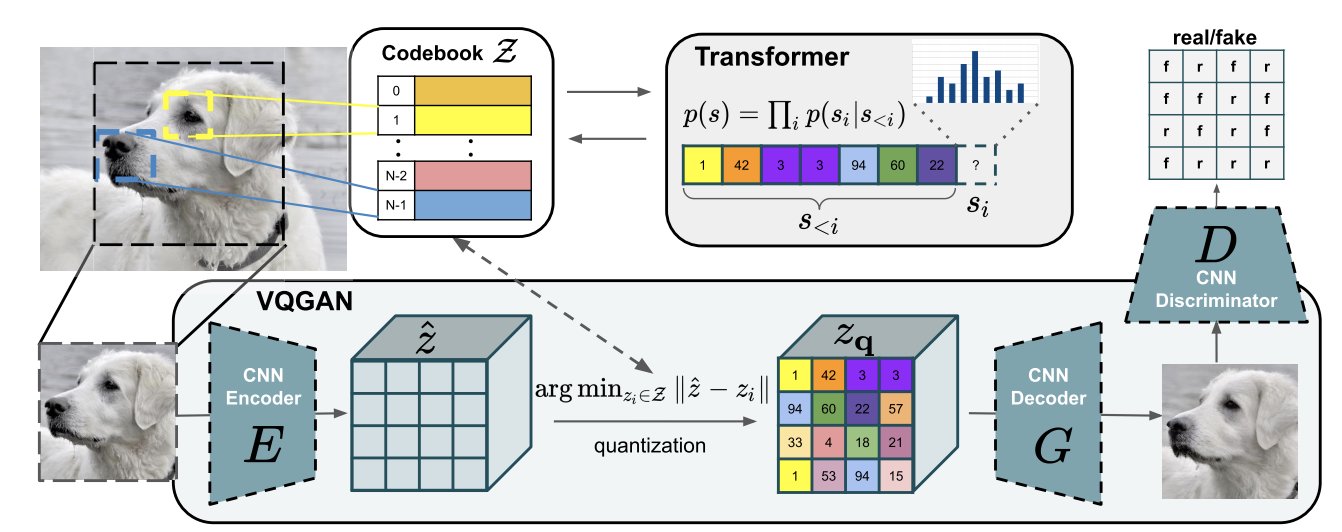
The overview of DALL-E could be illustrated as below. It contains two components: for image, VQGAN (vector quantized GAN) is used to map the 256x256 image to a 32x32 grid of image token and each token has 8192 possible values; then this token is combined with 256 BPE=encoded text token is fed into to train the autoregressive transformer. The text token is set to 256 by maximal.
Byte Pair Encoding
With Byte Pair Encoding (BPE) BPE, the frequently occurring subword pairs are merged together instead of being replaced by another byte to enable compression. This would basically lead the rare word athazagoraphobia to be split up into more frequent subwords such as ['▁ath', 'az', 'agor', 'aphobia'].
Check this article for more details.
The image result is shown as blow:

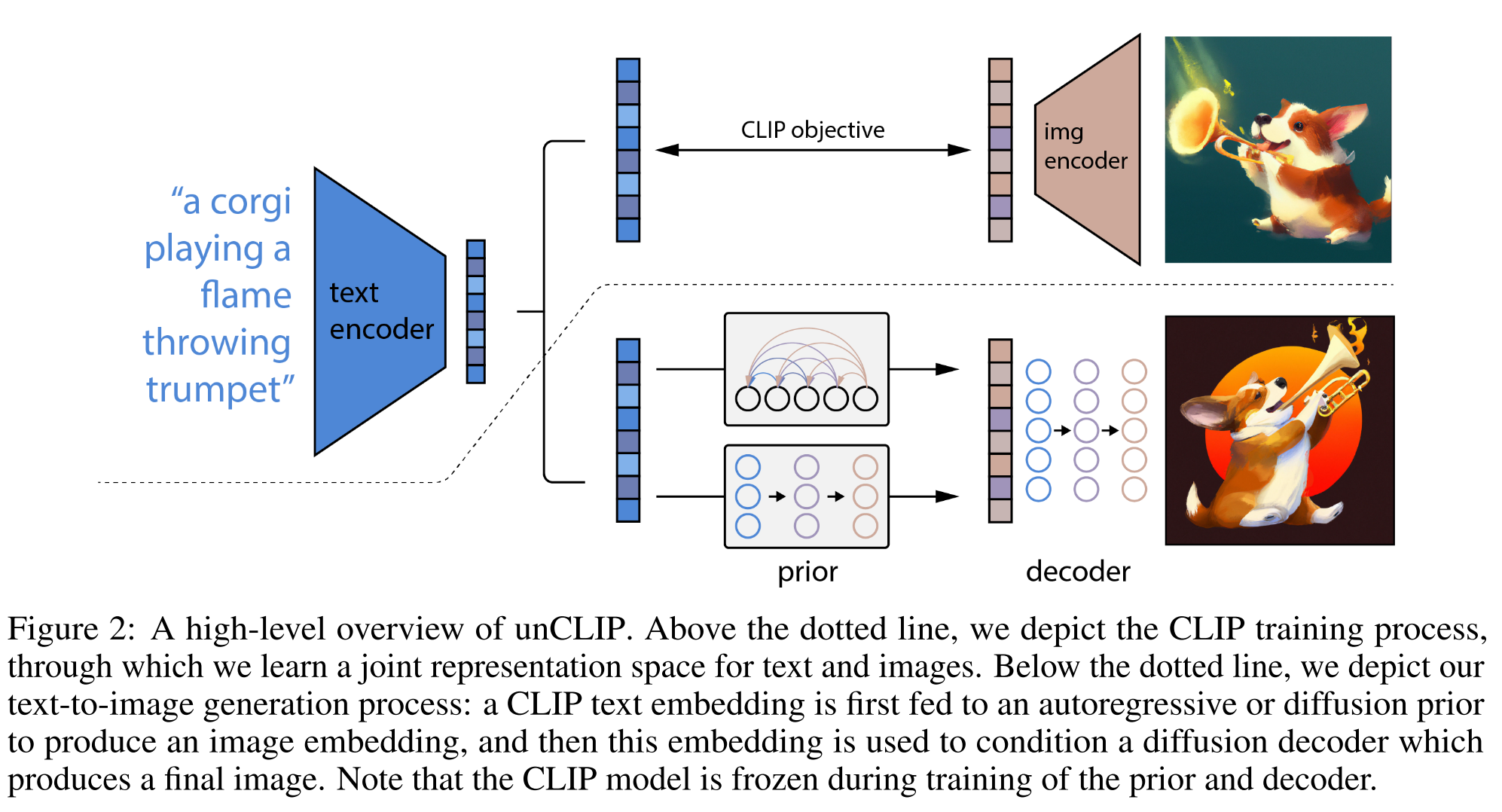
DALL-E2
DALL-E2 or unCLIP leverages CLIP to provide more robust representations of images that capture both semantics and style to enable text image generation. For details, please refer to my previous note in unCLIP
StoryDALL-E
StoryDALL-E extend DALL-E from generating a single image from a sentence to producing a sequence of images given a corresponding sequence of captions, forming a narrative. the major contributions of StoryDALL-E are:
- a retro Cross-Attention block to condition the image generation on a source image to ensure appearance/background consistency. The model is limited to the fixed set of characters, settings, and events on which it is trained and has no way of knowing how to depict a new character that appears in a caption during test time; captions do not contain enough information to fully describe the character’s appearance. Therefore, in order to generalize to new story elements, the model must have a mechanism for obtaining additional information about how these elements should be visually represented.
- introduce a self-attention block for generating story embeddings that provide global semantic context of the story during generation of each frame.
Figure 2 shows an overview of StoryDALL-E, source frame and retro cross-attention blocks provides the appearance and background context for all the frames; self-attention block provides global context of the story for each of the frames.
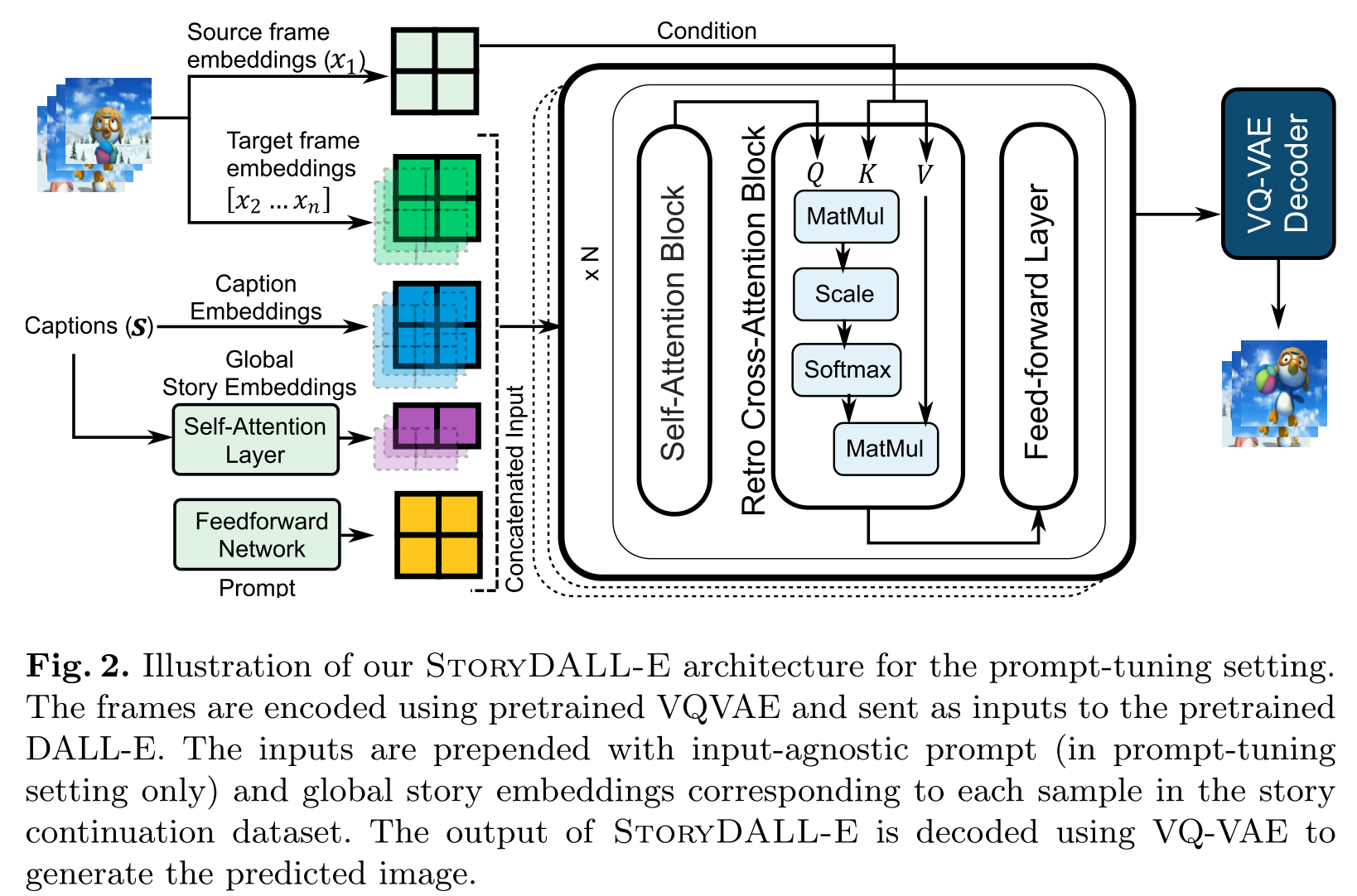
Figure 4 shows visual examples of the results.

Global Story Encoder
we propose to use a self-attention (\(f_{self}\)) based global story encoder, which takes the sentence embeddings for all captions as input and generates contextualized story embeddings for each time-step using parallel processing (see Figure 2). Additionally, we initialize sinusoid positional embeddings (\(S_{pos}\)). to provide information about the position of the target frame within the story, and add those to the story embeddings: \(S_{global} = f_{self}(S+S_{pos})\). These embeddings are prepended to the word embeddings for the caption at that timestep and sent as input to the generative model.
Retro-fitted Cross-Attention Blocks
Next, we want to ‘retro-fit’ the DALL-E model with the ability to copy relevant elements from the source image, in or- der to promote generalizability to unseen visual attributes. This will allow the model to generate visual stories with completely new characters, as long as they are present in the source frame. Hence, we adapt the model to ‘condition’ the generation of target frame on the source frame by adding a cross-attention block to each self-attention block of the native DALL-E architecture. The image em- beddings of the source frame are used in the cross-attention layer as key (K) and value (V), while the output from the preceding self-attention layer is used as query (Q). As
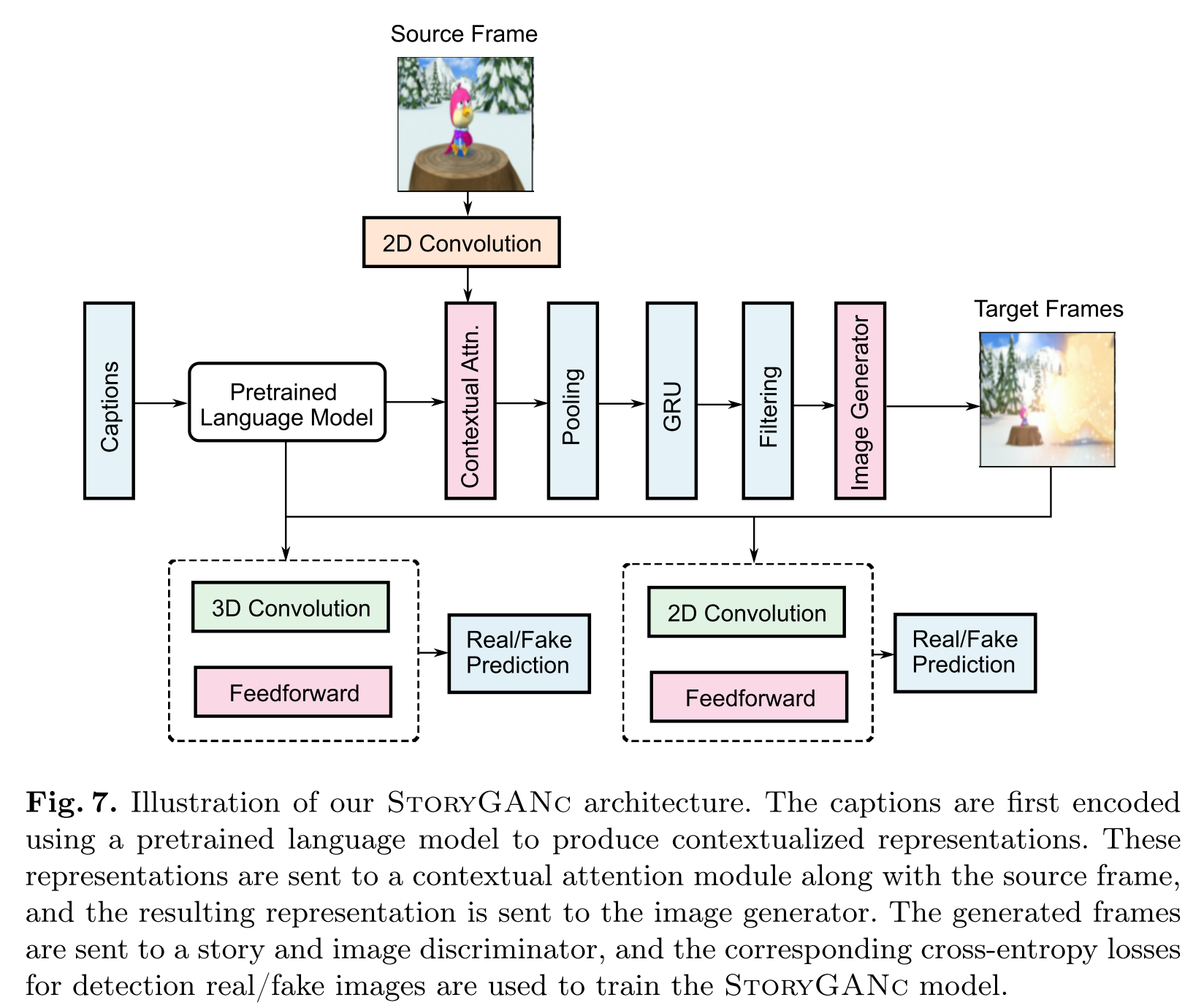
StoryGANc
StoryGANc follows the general framework of the StoryGAN model [27] i.e., it is composed of a recurrent text encoder, an image generation module, and two discriminators - image and story discriminator. We modify this frame-work to accept the source frame as input for the story continuation task, and use it for improving the generation of target frames.
We use a pretrained language model (such as RoBERTa [29] or CLIP text encoder [37]) as the caption encoder. To ensure that the model has access to all captions, we append the captions together and use a special token to denote which caption is currently being generated.
The story representation from the encoder is combined with the image embeddings of the first frame of the image sequence using contextual attention [52] between the two inputs. First, we reshape the story representation as a 2D matrix and extract 3 × 3 patches \(\{t_{x,y}\}\) as convolutional filters. Then, we match them against potential patches from the source frame \(\{s_{x′,y′}\}\) by measuring the cosine similarity. We compute the similarity score for all dimensions along (x′, y′) for the patch in target frame (x, y) and find the best match from the softmax-scaled similarity scores. [52] implement this efficiently using convolution and channel-wise softmax; we use their implementation in our StoryGANc model. The extracted patches are used as deconvolutional filters and added to the target frame s. The resulting representation is fed through a generator module which processes each caption and produces an image.
The story discriminator takes all of the generated images and uses 3D convolution to create a single representation and then makes a pre- diction as to whether the generated story is real or fake. The image discriminator performs the same function but only focuses on individual images. The KL-Divergence loss enforces gaussian distribution on the latent representations learnt by GAN.
Check Figure 7 for an overview of StoryGANc