An Empirical Study of Training End-to-End Vision-and-Language Transformers
[simvlm multimodal masked-image-modeling review encoder vision-transformer meter masked-language-modeling vit deep-learning vilt image-text-matching vq-vae vibert clip blip visualbert deit co-attention decoder swin-transformer roberta merged-attention bert constrastive-loss attenion vinvl transformer albef This is my reading note for An Empirical Study of Training End-to-End Vision-and-Language Transformers. This paper provides a good review and comparison of multi modality (video and text) model’s design choice.
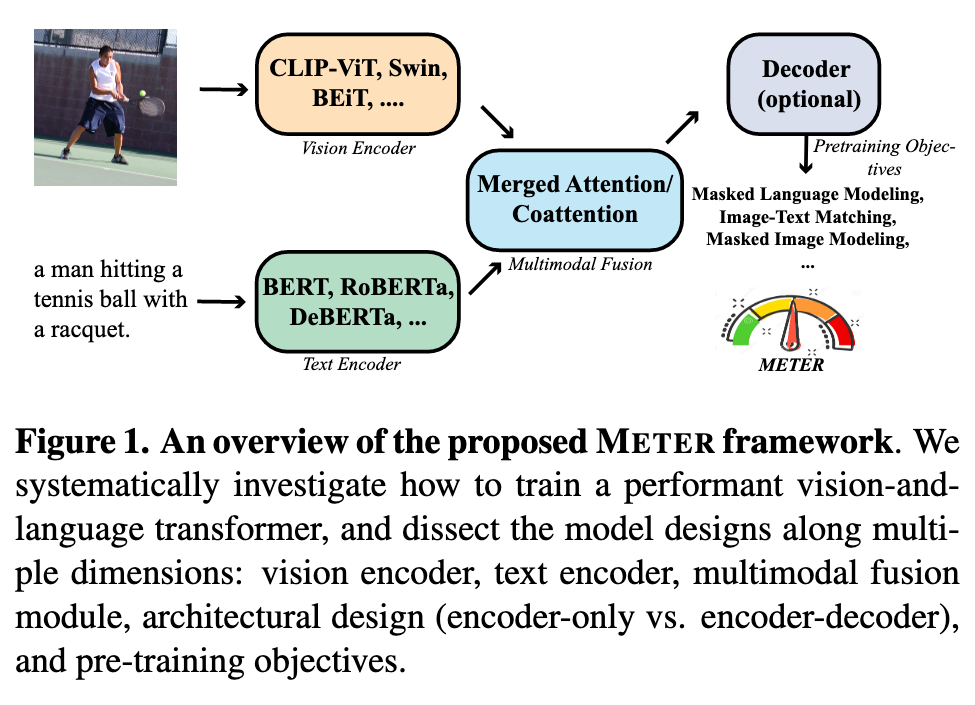
Introduction
Vision-and-language (VL) pre-training has proven to be highly effective on various VL downstream tasks. While recent work has shown that fully transformer-based VL models can be more efficient than previous region-featurebased methods, their performance on downstream tasks often degrades significantly. (p. 1)
Recent works [25,29,60] that tried to adopt vision transformers have not shown satisfactory performance and typically underperform state-of-the-art region-feature-based VLP models (e.g., VinVL [65]). (p. 1)
- Vision transformer (ViT) plays a more vital role than language transformer in VLP, and the performance of transformers on pure vision or language tasks is not a good indicator for its performance on VL tasks.
- The inclusion of cross-attention benefits multimodal fusion, which results in better downstream performance than using self-attention alone.
- Under a fair comparison setup, the encoder-only VLP model performs better than the encoder-decoder model for VQA and zero-shot image-text retrieval tasks.
- Adding the masked image modeling loss in VLP will not improve downstream task performance in our settings. (p. 2)
Proposed Method
Overview. Given a text sentence l and an image v, a VLP model first extracts both text features l = <l_1, · · · , l_N> and visual features v = <v_1, · · · , v_M> via a text encoder and a vision encoder. The text and visual features are then fed into a multimodal fusion module to produce cross-modal representations, which are then optionally fed into a decoder before generating the final outputs. (p. 3)
Model Architecture
Text Encoder
Following BERT [11] and RoBERTa [35], VLP models [6, 30, 32, 38, 49, 51] first segment the input sentence into a sequence of subwords [46], then insert two special tokens at the beginning and the end of the sentence to generate the input text sequence. (p. 3)
Multimodal Fusion
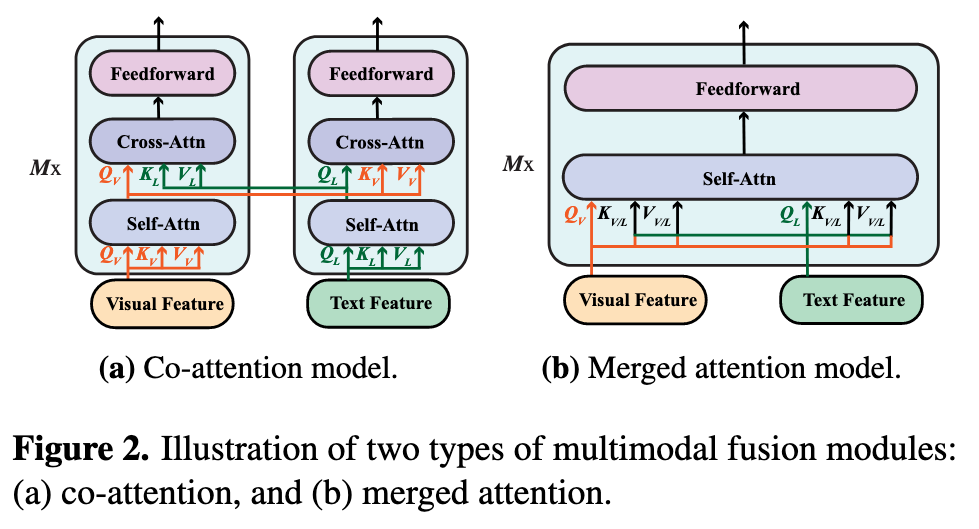
In the merged attention module, the text and visual features are simply concatenated together, then fed into a single transformer block. In the co-attention module, on the other hand, the text and visual features are fed into different transformer blocks independently, and techniques such as cross-attention are used to enable crossmodal interaction. For region-based VLP models, as shown in [4], the merged attention and co-attention models can achieve comparable performance. Yet, the merged attention module is more parameter-efficient, as the same set of parameters are used for both modalities. (p. 3)
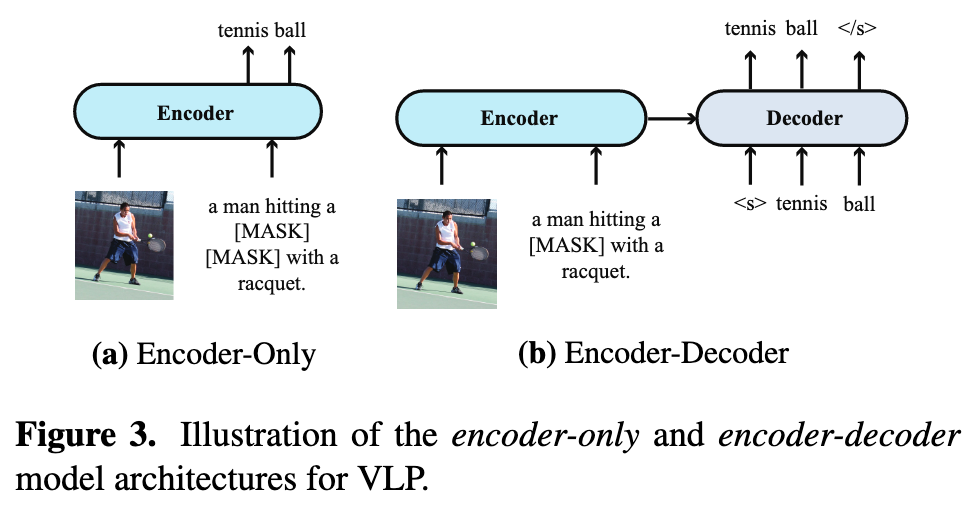
Encoder-Only vs. Encoder-Decoder.
Many VLP models such as VisualBERT [30] adopt the encoder-only architecture, where the cross-modal representations are directly fed into an output layer to generate the final outputs. Recently, VL-T5 [7] and SimVLM [58], on the other hand, advocate the use of a transformer encoder-decoder architecture, where the cross-modal representations are first fed into a decoder and then to an output layer. (p. 3)
Pre-training Objectives
Masked Language Modeling
Specifically, given an image-caption pair, we randomly mask some of the input tokens, and the model is trained to reconstruct the original tokens given the masked tokens lmask and its corresponding visual input v. (p. 4)
Image-Text Matching
In image-text matching, the model is given a batch of matched or mismatched image-caption pairs, and the model needs to identify which images and captions correspond to each other. Most VLP models treat image-text matching as a binary classification problem. Specifically, a special token (e.g., [CLS]) is inserted at the beginning of the input sentence, and it tries to learn a global cross-modal representation. We then feed the model with either a matched or mismatched image-caption pair hv, li with equal probability, and a classifier is added on top of the [CLS] token to predict a binary label y, indicating if the sampled image-caption pair is a match. (p. 4)
Masked Image Modeling
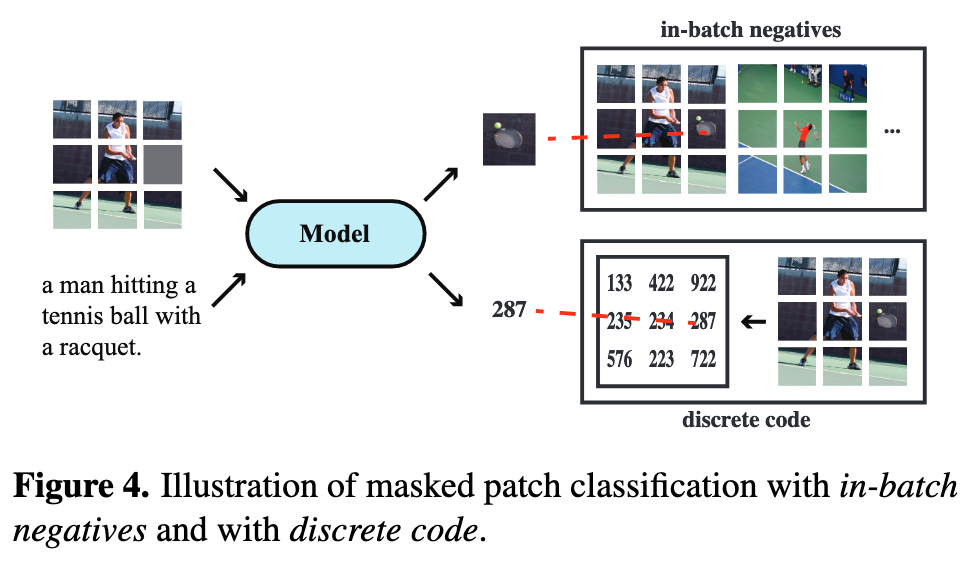
Formally, given a sequence of visual features v = <v_1, · · · , v_M>, where v_i is typically a region feature, we randomly mask some of the visual features, and the model outputs the reconstructed visual features ov given the rest of the visual features and the unmasked tokens t, and regression aims to minimize the mean squared error loss.
Notably, recent state-of-the-art models (e.g., ALBEF [29], VinVL [65]) do not apply MIM during VLP. In addition, in ViLT [25], the authors also demonstrate that masked patch regression is not helpful in their setting. (p. 4)
1) Masked Patch Classification with In-batch Negatives.We treat all the patches in {vk}B k=1 as candidate patches, and for each masked patch, we mask 15% of the input patches, and the model needs to select the original patch within this candidate set. (p. 4) 2) Masked Patch Classification with Discrete Code. Specifically, we first use the VQ-VAE [54] model in DALL-E [43] to tokenize each image into a sequence of discrete tokens. We resize each image so that the number of patches is equal to the number of tokens, and thus each patch corresponds to a discrete token. Then, we randomly mask 15% of the patches and feed the masked image patches to the model as before, but now the model is trained to predict the discrete tokens instead of the masked patches. (p. 5)
Experiment
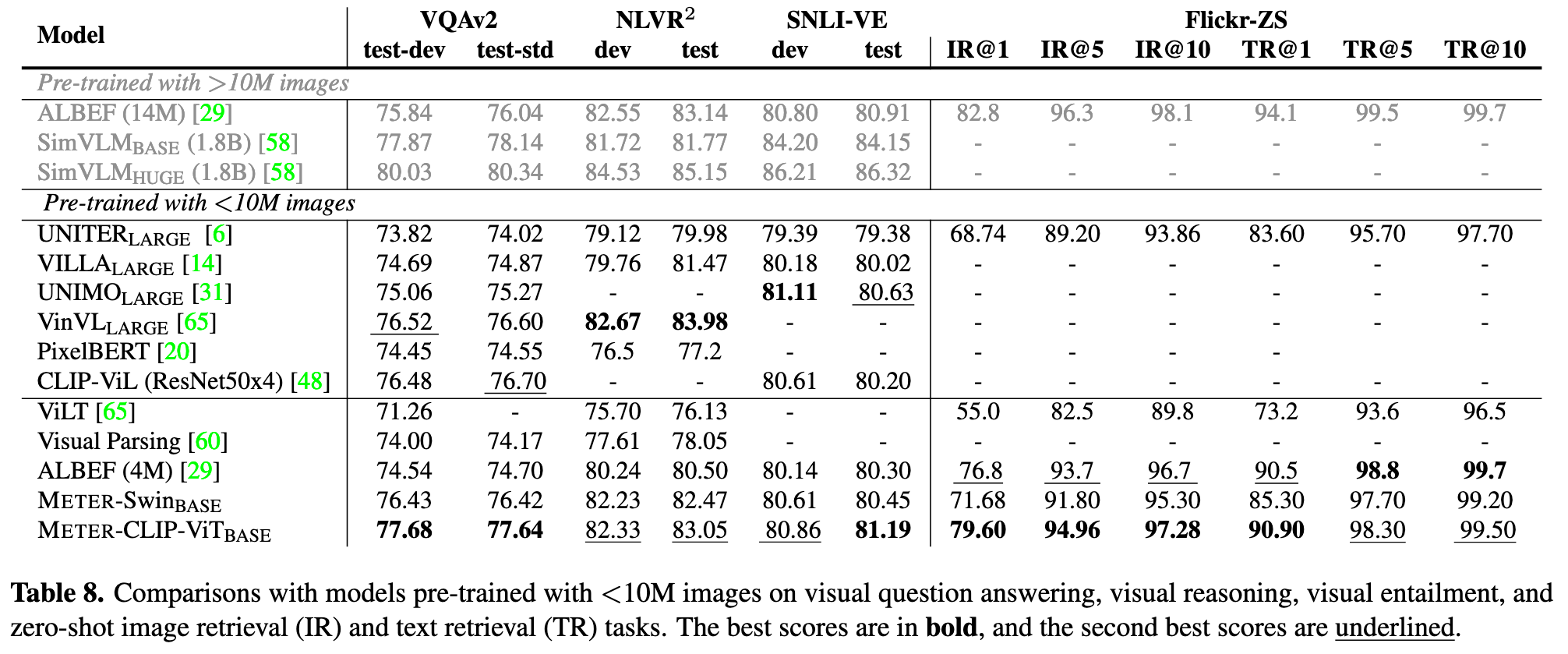
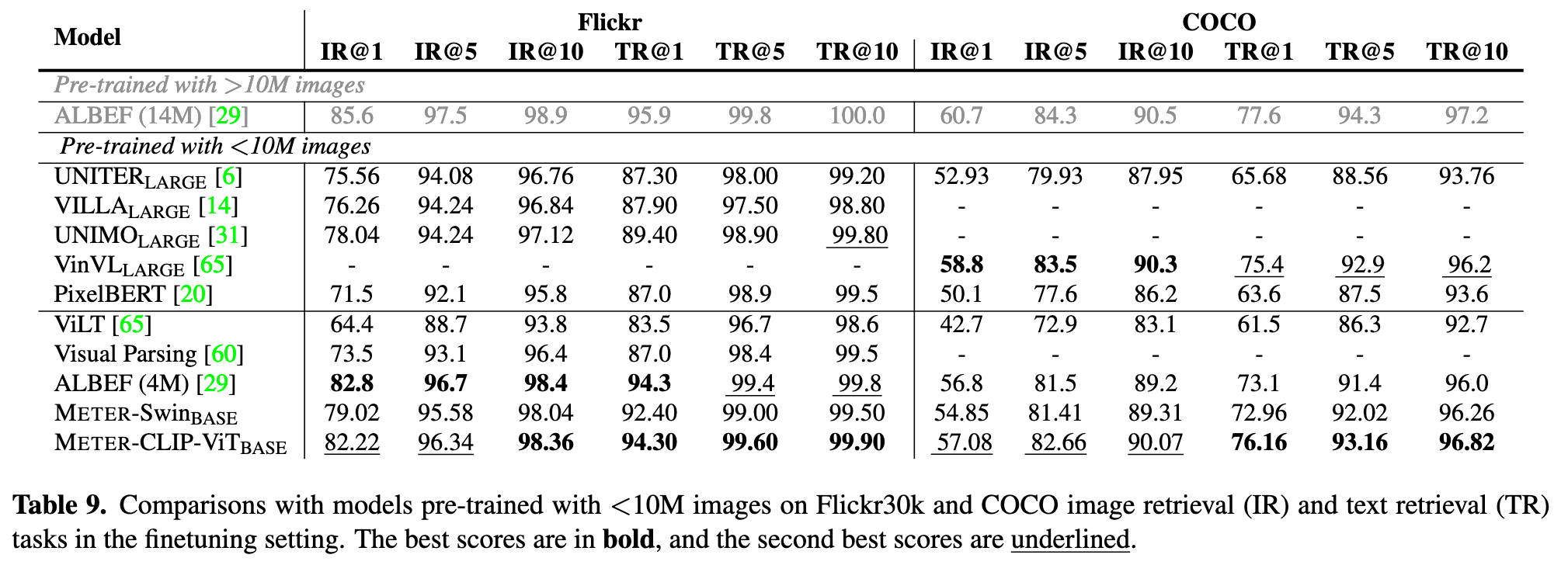
Impact of Vision and Language Encoders
Explorations without VLP
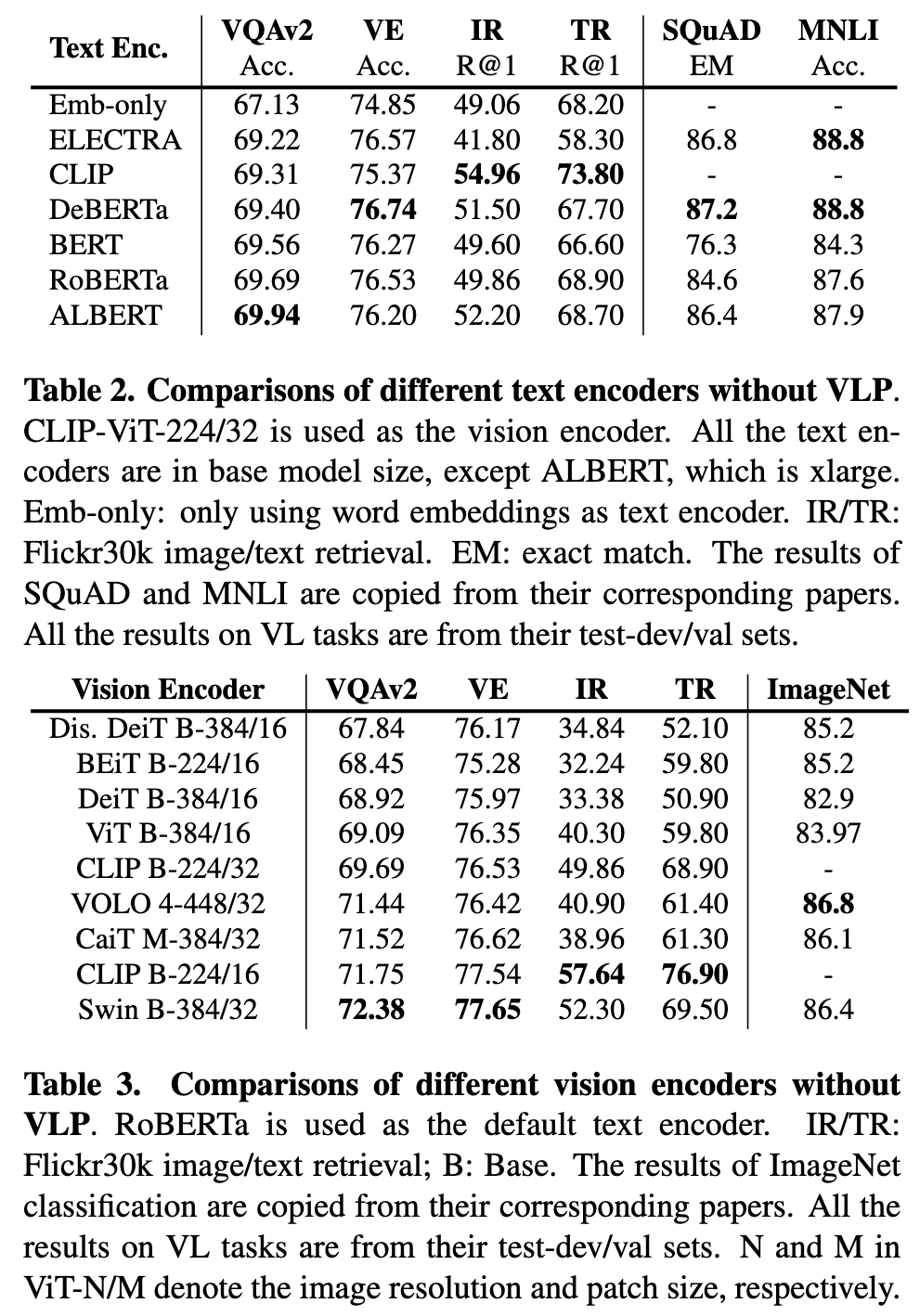
Impact of Text Encoders. As shown in Table 2, there are no significant differences between the model performance of different text encoders. RoBERTa seems to achieve the most robust performance in this setting. Also, as can be seen from the Emb-only results, it is necessary to have a pre-trained encoder because otherwise the downstream task performance will be degraded. (p. 6)
Impact of Vision Encoders. As summarized in Table 3, both CLIP-ViT-224/16 and Swin Transformer can achieve decent performance in this setting. Notably, Swin Transformer can achieve an VQA score of 72.38 on the test-dev set without any VLP, which is already comparable to some VLP models after pre-training. (p. 6)
Results with VLP
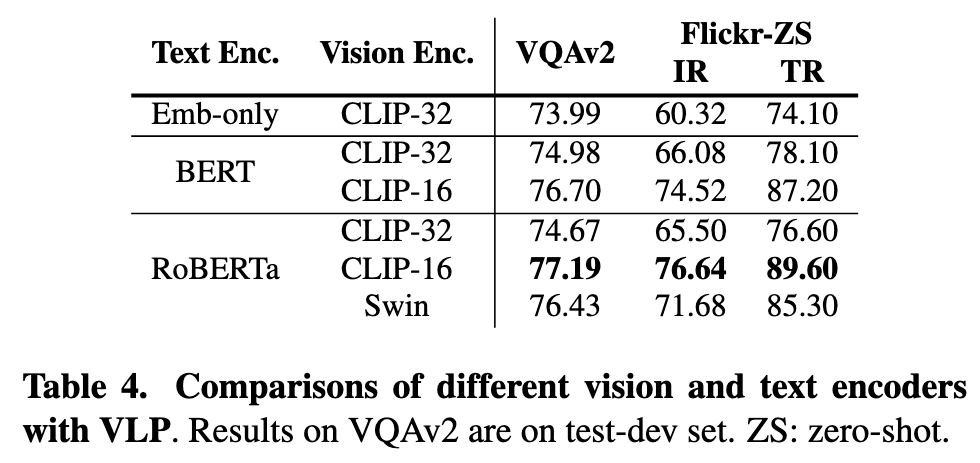
As shown in Table 4, after VLP, the difference between BERT and RoBERTa seems to be diminished, but it is still important to have a pre-trained text encoder on the bottom (Embed-only vs. RoBERTa). (p. 6)
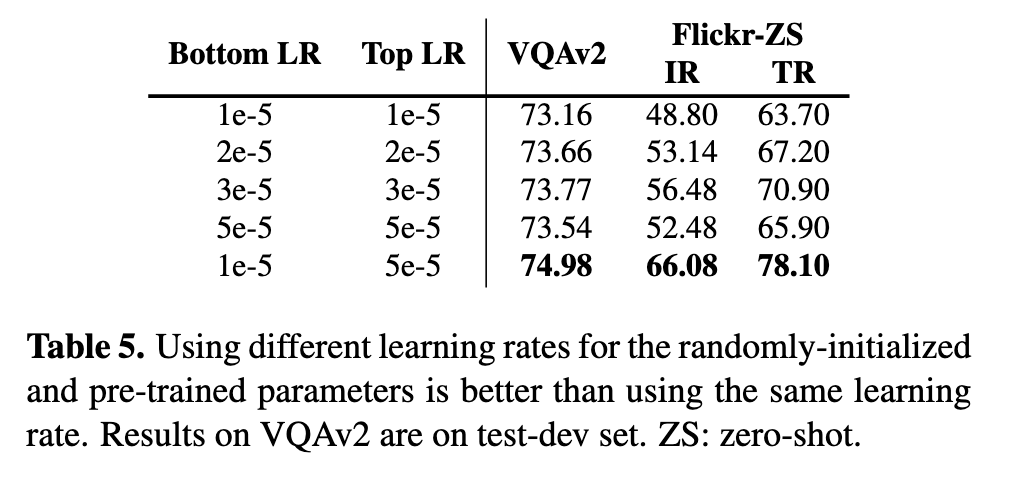
First, it is better to use a larger learning rate for the randomly initialized parameters than parameters initialized with pre-trained models, which is also found useful in some other NLP tasks [34]. (p. 6)
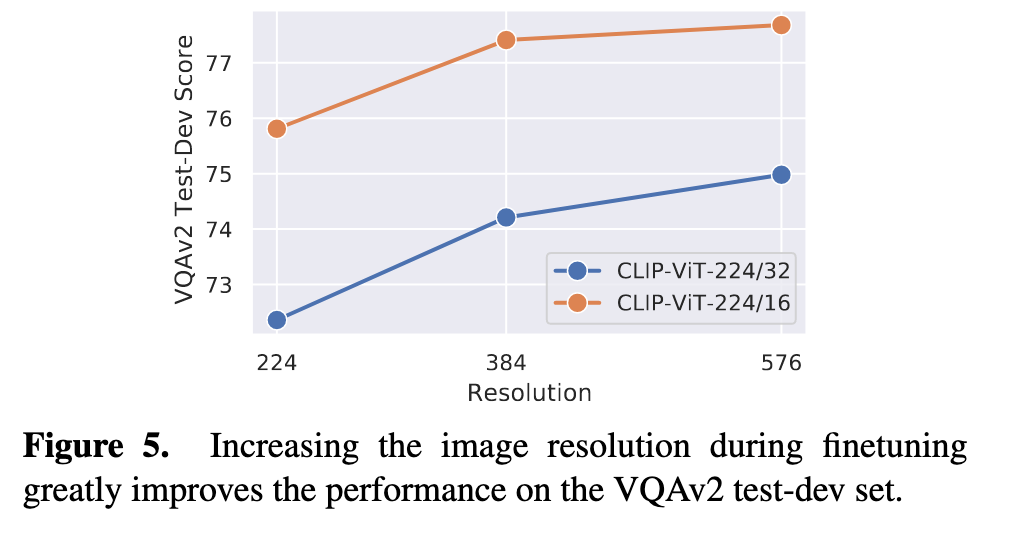
Second, similar to several previous work [25,64], we find that increasing the image resolution during finetuning can improve the model performance by a large margin, especially when the ratio of image resolution to patch size is low. (p. 6)
Analysis of the Multimodal Fusion Module

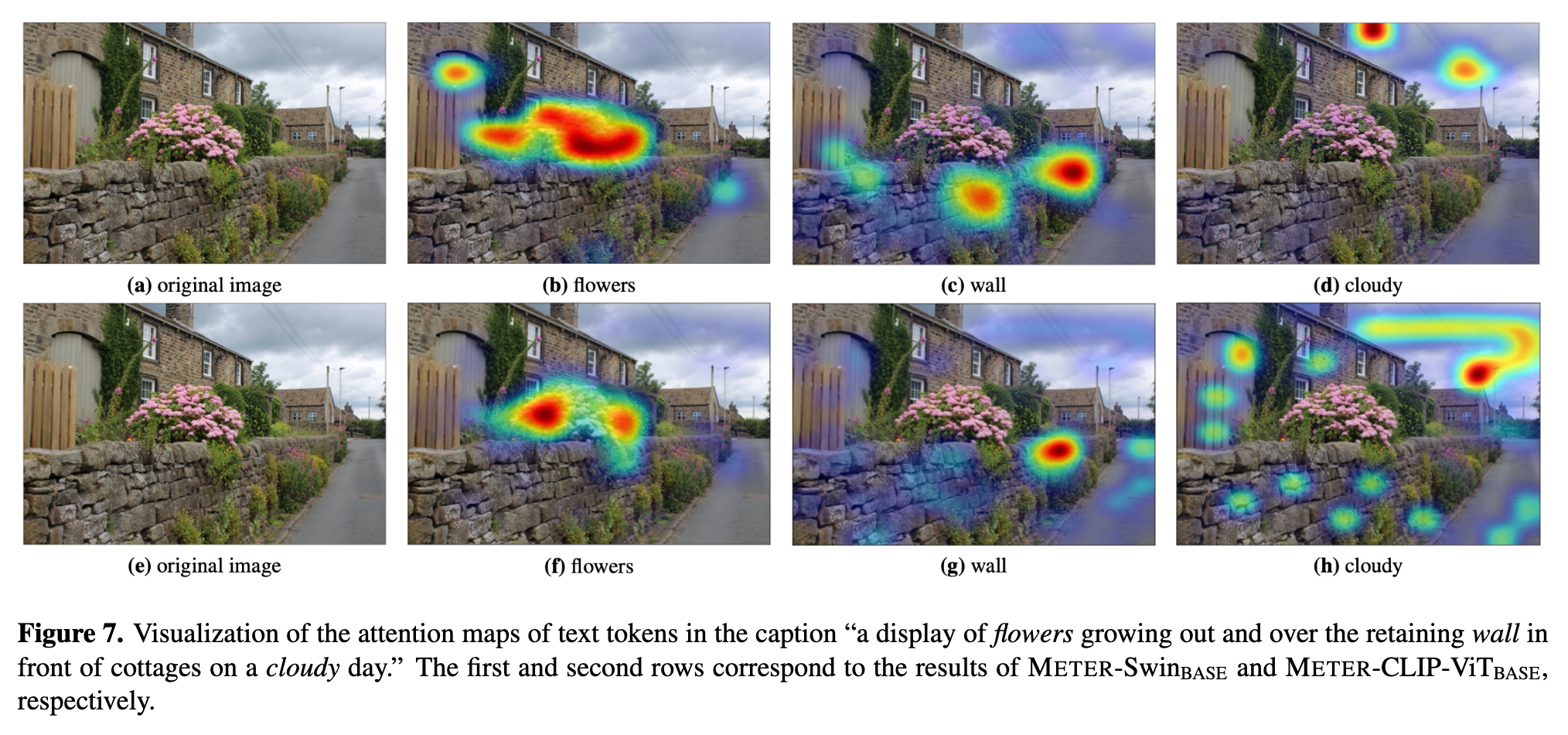
The co-attention model performs better than the merged attention model in our setting, indicating that it is important to have different sets of parameters for the two modalities. Note that this contradicts with the findings in region-based VLP models [4], possibly because (i) findings of region-based VLP models cannot directly apply to ViT-based VLP models; (ii) most region-based VLP models only use pre-trained visual encoders, and also do not have a pre-trained text encoder included, thus the inconsistency between the two modalities will not favor symmetrical architecture like the co-attention model. (p. 7)
Encoder-Only vs. Encoder-Decoder
As shown in Table 6, the encoder-only model can outperform the encoder-decoder model on our two discriminative tasks, which is consistent with the findings in [7]. However, it should be noted that the encoder-decoder architecture is more flexible, as it can perform tasks such as image captioning which may not be that straightforward for an encoder-only model to be applied to. (p. 7)
Ablations on Pre-training Objectives
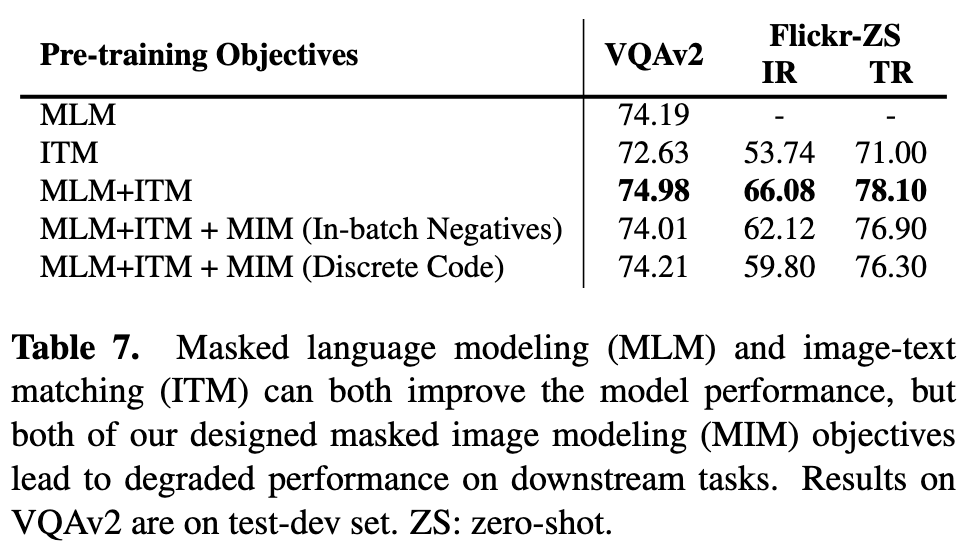
As summarized in Table 7, both masked language modeling and image-text matching can bring performance improvements on downstream tasks. However, both of our masked image modeling objectives can lead to degraded performance on both VQAv2 and Flickr30k retrieval tasks. This further indicates that conclusions in region-based VLP models may not necessarily hold in vision transformer based models. We hypothesize that the performance drop is due to the conflicts between different objectives, and some techniques in multi-task optimization [57, 62] may be borrowed to resolve the conflicts, which we list as one of the future directions. Another possible reason is that image patches can be noisy, thus the supervisions on reconstructing these noisy patches can be uninformative (p. 7)