Visual Instruction Tuning
[clip vicuna multimodal llm llama instruction-tuning palm deep-learning alphca chatgpt transformer llava flamingo This is my reading note for Visual Instruction Tuning. The paper exposes a method to train a multi-modality model - that woks like chat GPT. This is achieved by building an instruction following dataset that’s paired with images. The model is then trained on this dataset.
Introduction
In this paper, we present the first attempt to use language-only GPT-4 to generate multimodal language-image instruction-following data. By instruction tuning on such generated data, we in- troduce LLaVA: Large Language and Vision Assistant, an end-to-end trained large multimodal model that connects a vision encoder and LLM for general- purpose visual and language understanding. (p. 1)
Alpaca [43], Vicuna [45], GPT-4-LLM [34] utilize various machine-generated high-quality instruction-following samples to improve the LLM’s alignment ability, reporting impressive performance compared with proprietary LLMs. Importantly, this line of work is text-only (p. 2)
Major contributions:
- We present a data reformation perspective and pipeline to convert image-text pairs into the appropriate instruction-following format, using ChatGPT/GPT-4. (p. 2)
- We develop a large multimodal model (LMM), by connecting the open-set visual encoder of CLIP [36] with the language decoder LLaMA, and fine-tuning them end-to-end on our generated instructional vision-language data. (p. 2)
Related Work
Multimodal Instruction-following Agents
Existing works could be divided into two groups:
- End-to-end trained models, which are separately explored in each specific research topic (p. 2)
- A system that coordinates various models via LangChain [1] / LLMs [31] (p. 2)
Instruction Tuning
In the natural language processing (NLP) community, to enable LLMs such as GPT-3 [7], T5 [37], PaLM [9], and OPT [56] to follow natural language instructions and complete real-world tasks, researchers have explored methods for LLM instruction-tuning [33, 48, 47], leading to instruction-tuned counterparts such as InstructGPT [33]/ChatGPT [31], FLAN-T5 [10], FLAN- PaLM [10], and OPT-IML [19], respectively. It turns out this simple approach can effectively improve the zero- and few-shot generalization abilities of LLMs. (p. 2)
Flamingo [2] can be viewed as the GPT-3 moment in the multimodal domain, due to its strong performance on zero-shot task transfer and in-context-learning. Other LMMs trained on image-text pairs include BLIP-2 [25], FROMAGe [22], and KOSMOS-1 [17]. PaLM-E [12] is an LMM for embodied AI. (p. 2)
GPT-assisted Visual Instruction Data Generation

For an image Xv and its associated caption Xc, it is natural to create a set of questions Xq with the intent to instruct the assistant to describe the image content. We prompt GPT-4 and curate such a questions list in Table 8 in the Appendix. Therefore, a simple way to expand an image-text pair to its instruction-following version is Human : $Xq Xv
To mitigate this issue, we leverage language-only GPT-4 or ChatGPT as the strong teacher (both accept only text as input), to create instruction-following data involving visual content. Specifically, in order to encode an image into its visual features to prompt a text-only GPT, we use two types of symbolic representations:
- Captions typically describe the visual scene from various perspectives.
- Bounding boxes usually localize the objects in the scene, and each box encodes the object concept and its spatial location. One example is shown in the top block of Table 1. (p. 3)
For each type, we first manually design a few examples. They are the only human annotations we have during data collection, and are used as seed examples in in-context-learning to query GPT-4.
- Conversation. We design a conversation between the assistant and a person asking questions about this photo. The answers are in a tone as if the assistant is seeing the image and answering the question. A diverse set of questions are asked about the visual content of the image, including the object types, counting the objects, object actions, object locations, relative positions between objects. Only questions that have definite answers are considered. Please see Table 10 for the detailed prompt.
- Detailed description. To include a rich and comprehensive description for an image, we create a list of questions with such an intent. We prompt GPT-4 then curate the list, which is show in Table 9 in the Appendix. For each image, we randomly sample one question from the list to ask GPT-4 to generate the detailed description.
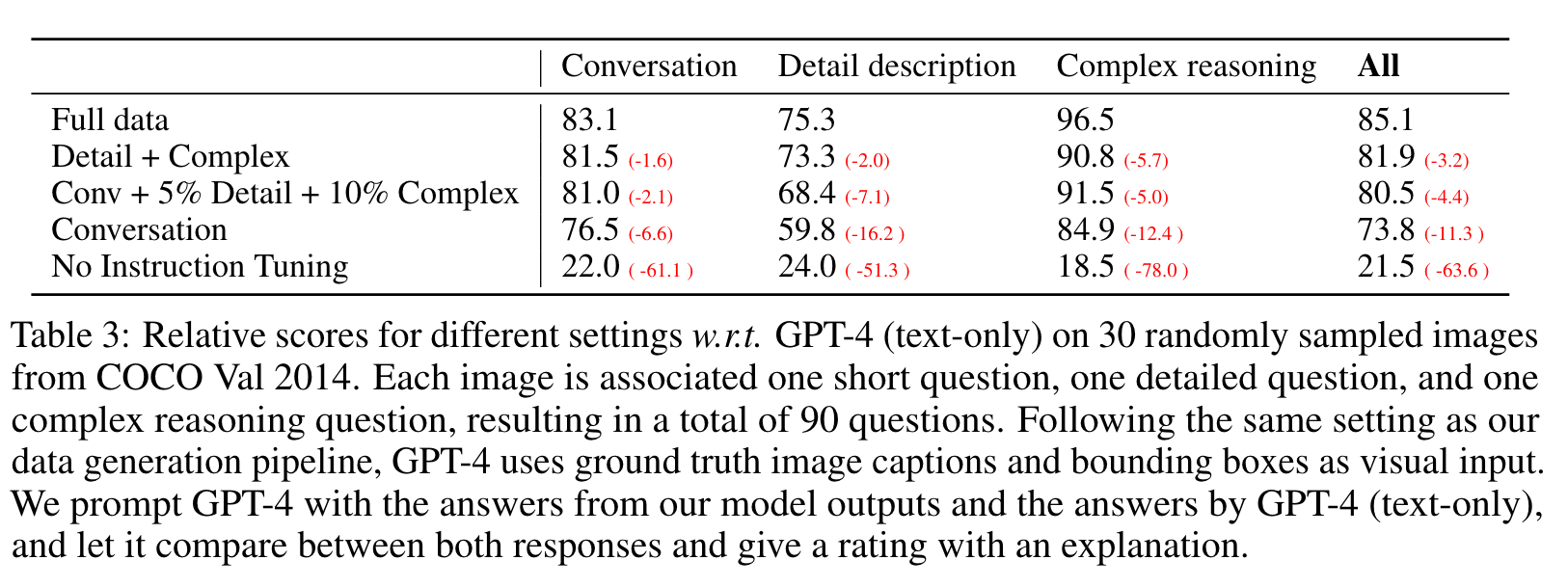
- Complex reasoning. The above two types focus on the visual content itself, based on which we further create in-depth reasoning questions. The answers typically require a step-by-step reasoning process by following rigorous logic. We collect 158K unique language-image instruction-following samples in total, including 58K in conversations, 23K in detailed description, and 77k in complex reasoning, respectively. We ablated the use of ChatGPT and GPT-4 in our early experiments, and found that GPT-4 can consistently provide higher quality instruction-following data, such as spatial reasoning. (p. 4)
Visual Instruction Tuning
Architecture
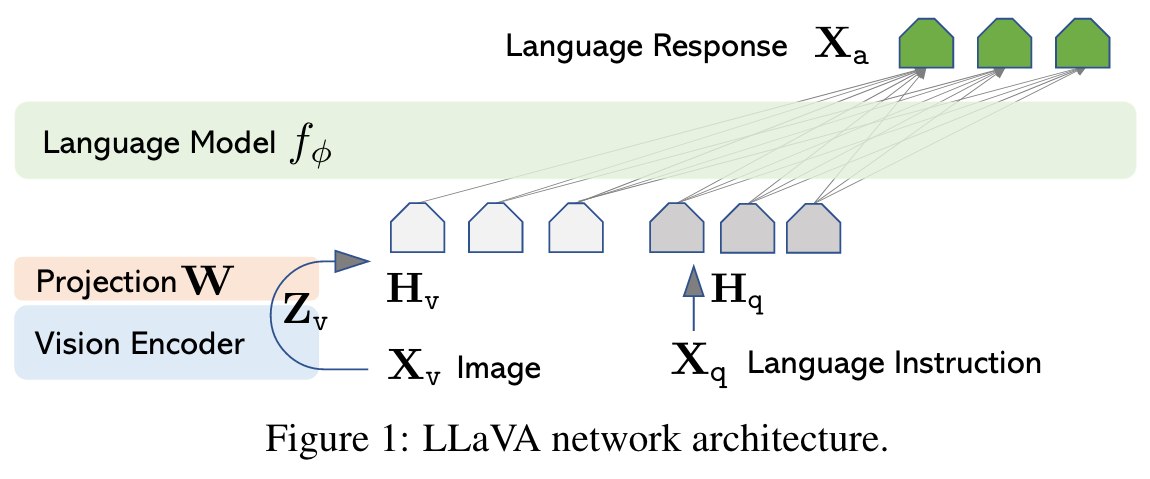
For an input image Xv, we consider the pre-trained CLIP visual encoder ViT-L/14 [36], which provides the visual feature Zv = g(Xv). The grid features before and after the last Transformer layer are considered in our experiments. We consider a simple linear layer to connect image features into the word embedding space. Specifically, we apply a trainable projection matrix W to convert Zv into language embedding tokens Hq, which have the same dimensionality of the word embedding space in the language model: (p. 4)
More sophisticated (but expensive) schemes to connect the image and language representations can also be considered, such as gated cross-attention in Flamingo [2] and Q-former in BLIP-2 [25], or other vision encoders such as SAM [21] that provide object-level features. (p. 4)
Training

For each image X_v, we generate multi-turn conversation data (X^1q, X^1_a, · · · , X^T_q , X^T_a ), where T is the total number of turns. We organize them as a sequence, by treating all answers as the assistant’s response, and the instruction X^t{instruct} at the t-th turn as: (p. 5)
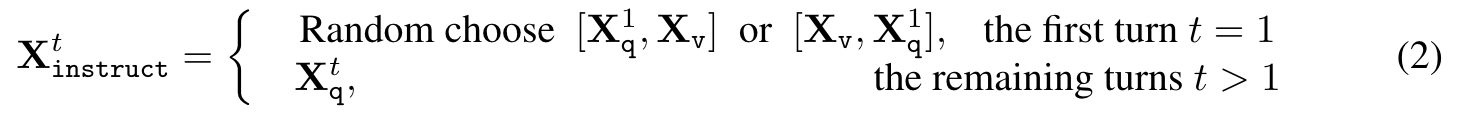
For LLaVA model training, we consider a two-stage instruction-tuning procedure. (p. 5)
Stage 1: Pre-training for Feature Alignment
In training, we keep both the visual encoder and LLM weights frozen, and maximize the likelihood of (3) with trainable parameters θ = W (the projection matrix) only. I (p. 5)
Stage 2: Fine-tuning End-to-End
We only keep the visual encoder weights frozen, and continue to update both the pre-trained weights of the projection layer and LLM in LLaVA (p. 5)
- Multimodal Chatbot. We develop a Chatbot by fine-tuning on the 158K unique language- image instruction-following data collected in Section 3 (p. 5)
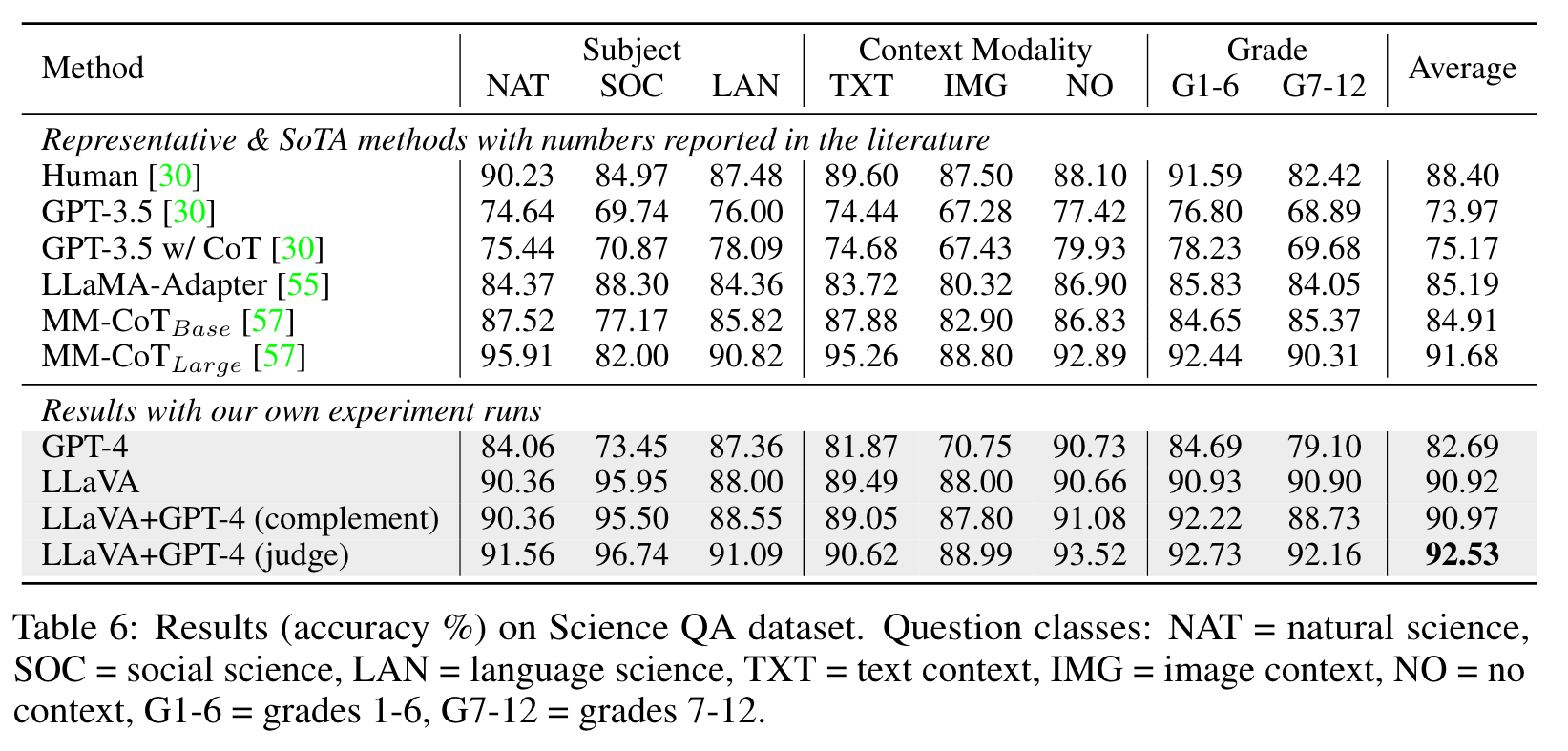
- Science QA. We study our method on the ScienceQA benchmark [30], the first large-scale multimodal science question dataset that annotates the answers with detailed lectures and explanations. Each question is provided a context in the form of natural language or an image. The assistant provides the reasoning process in natural language and selects the answer from multiple choices. For training in (2), we organize the data as a single turn conversation, the question & context as Xinstruct, and reasoning & answer as Xa. (p. 6)
Experiments

Ablations
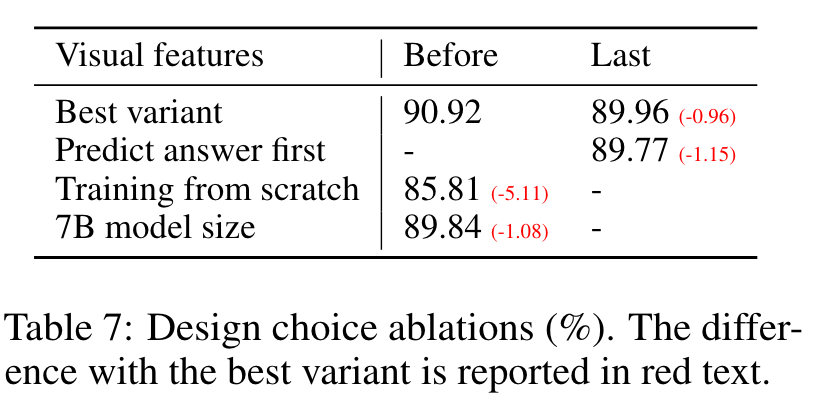
We ablate several design choices on ScienceQA in Table 7.
Visual features
We tried using the last layer feature from CLIP vision encoder, which yields 89.96% and is 0.96% lower than the feature before the last year. We hypothesize that this is because CLIP’s last year features may focus more on global image properties compared to the layer before it, which can focus more on localized properties that can be more useful for understanding specific image details.
Chain-of-thoughts
To decide the order between the answer and reasoning process in the model prediction, we run both variants and observe that answer-first reports the best number 89.77% accuracy in 12 epochs, while reasoning-first can quickly reach 89.77% accuracy in 6 epochs, but no further improvement with more training. Training the model for 24 epochs does not improve the performance. We conclude that CoT-like reasoning-first strategy can largely improve convergence, but contributes relatively little to the final performance.
Pre-training
We skip pre-training and directly train on Science QA from scratch – performance drops to 85.81% accuracy. The 5.11% absolute degradation indicates the importance of our pre-training stage, in aligning multimodal features while preserving the vast pre-trained knowledge.
Model size
We keep all configurations the same as our best 13B model, and train a 7B model. This yields 89.84% accuracy, which is 1.08% lower than 90.92%, demonstrating the importance of model scale. (p. 9)