Make-An-Audio Text-To-Audio Generation with Prompt-Enhanced Diffusion Models
[hubert bert clip audio-gen multimodal diffusion diff-sound audio-lm clap sound-stream deep-learning neural-sound mel-spectrogram audio vq-vae transformer make-an-audio This is my reading note for Make-An-Audio: Text-To-Audio Generation with Prompt-Enhanced Diffusion Models. This paper proposes a diffusion model for audio, which uses an auto encoder to convert audio signal to a spectrum which could be natively handled by latent diffusion method.
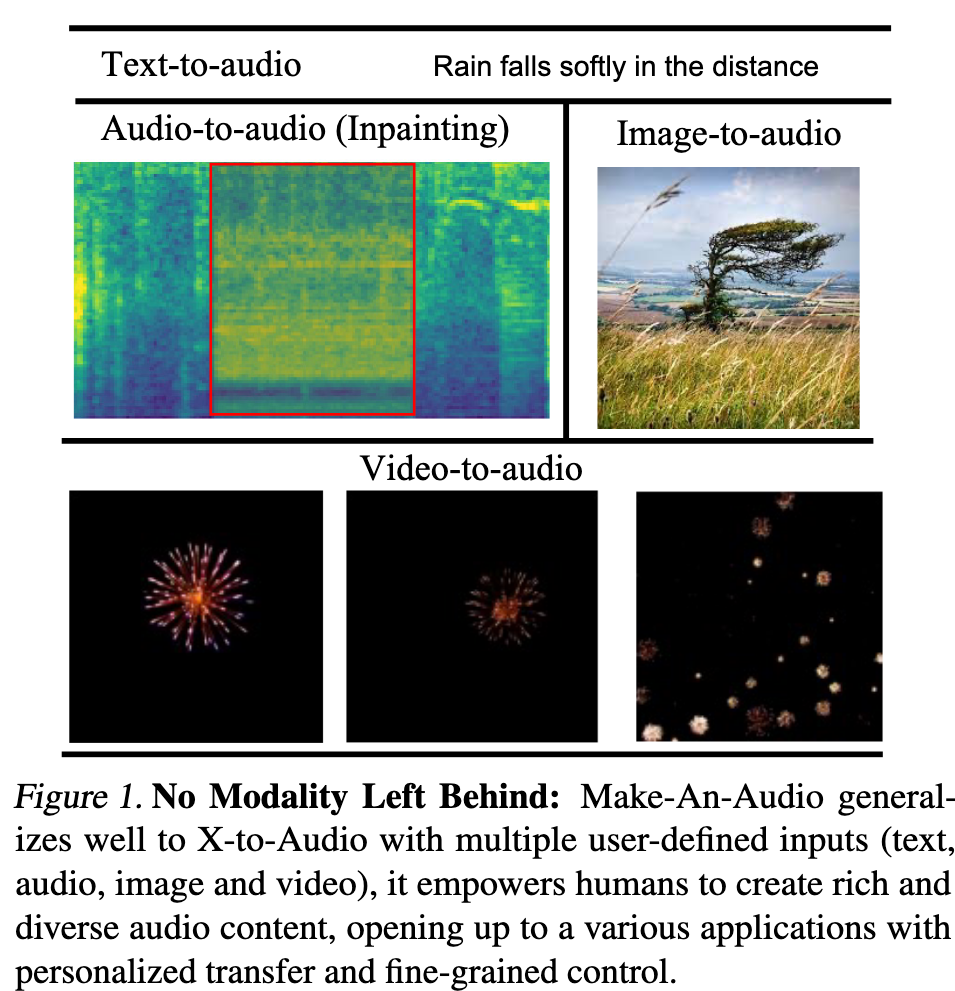
Introduction
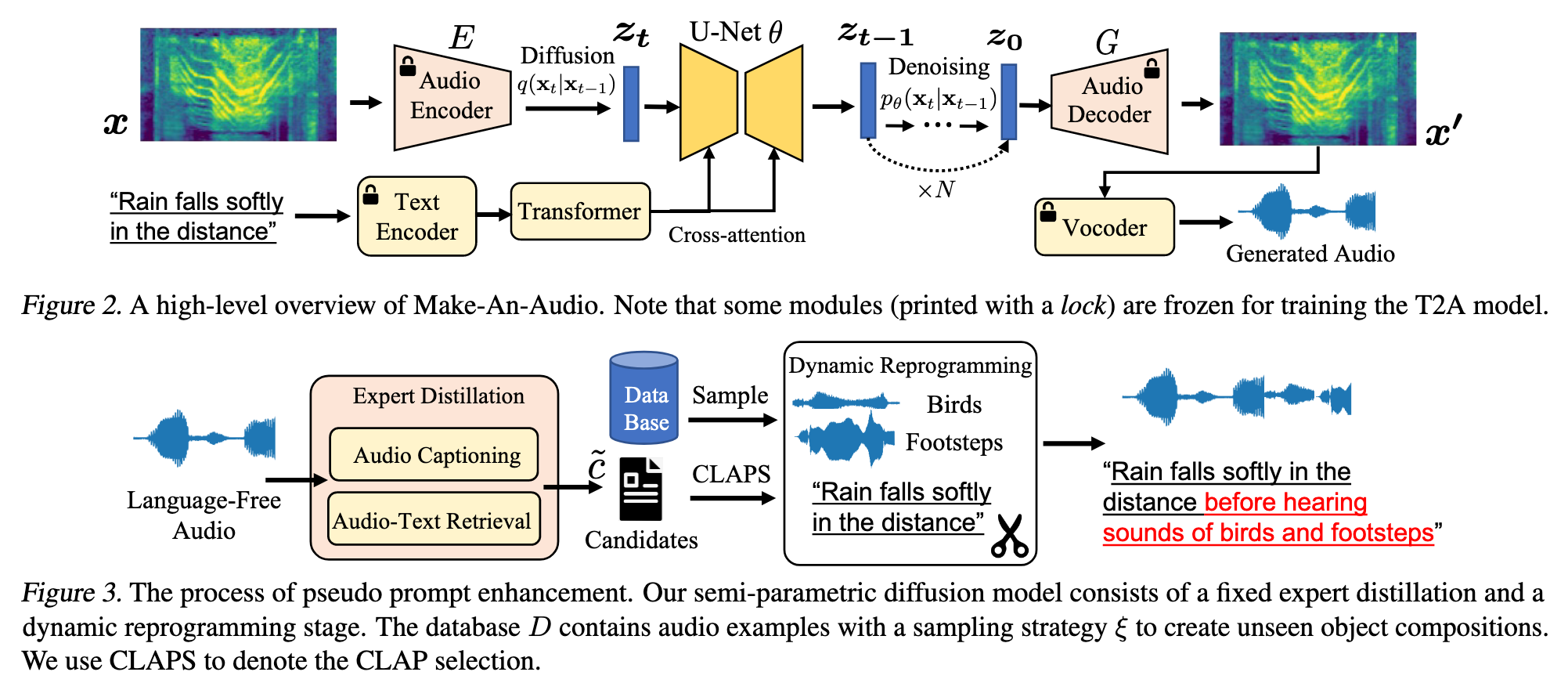
In this work, we propose Make-An-Audio with a prompt-enhanced diffusion model that addresses these gaps by 1) introducing pseudo prompt enhancement with a distill-then-reprogram approach, it alleviates data scarcity with orders of magnitude concept compositions by using language-free audios; 2) leveraging spectrogram autoencoder to predict the self-supervised audio representation instead of waveforms. Together with robust contrastive language-audio pretraining (CLAP) representations, Make-An-Audio achieves state-of-the-art results in both objective and subjective benchmark evaluation (p. 1)
Related Works
Text-Guided Audio Synthesis
DiffSound (Yang et al., 2022) is the first to explore text-to-audio generation with a discrete diffusion process that operates on audio codes obtained from a VQ-VAE, leveraging masked text generation with CLIP representations. AudioLM (Borsos et al., 2022) introduces the discretized activations of a masked language model pre-trained on audio and generates syntactically plausible speech or music. (p. 2)
The concurrent work AudioGen (Kreuk et al., 2022) propose to generate audio samples auto-regressively conditioned on text inputs, while our proposed method differentiates from it in the following: 1) we introduce pseudo prompt enhancement and leverage the power of contrastive language-audio pre-training and diffusion models for high-fidelity generation. 2) We predict the continuous spectrogram representations, significantly improving computational efficiency and reducing training costs. (p. 2)
Audio Representation Learning
Inspired by vector quantization (VQ) techniques, SoundStream (Zeghidour et al., 2021) presents a hierarchical architecture for high-level representations that carry semantic information (p. 2)
Recently, spectrograms (akin to 1-channel 2D images) auto-encoder (Gong et al., 2022; He et al., 2022) with reconstruction objective as self-supervision have demonstrated the effectiveness of heterogeneous image-to-audio transfer, advancing the field of speech and audio processing on a variety of downstream tasks. (p. 3)
Proposed Method
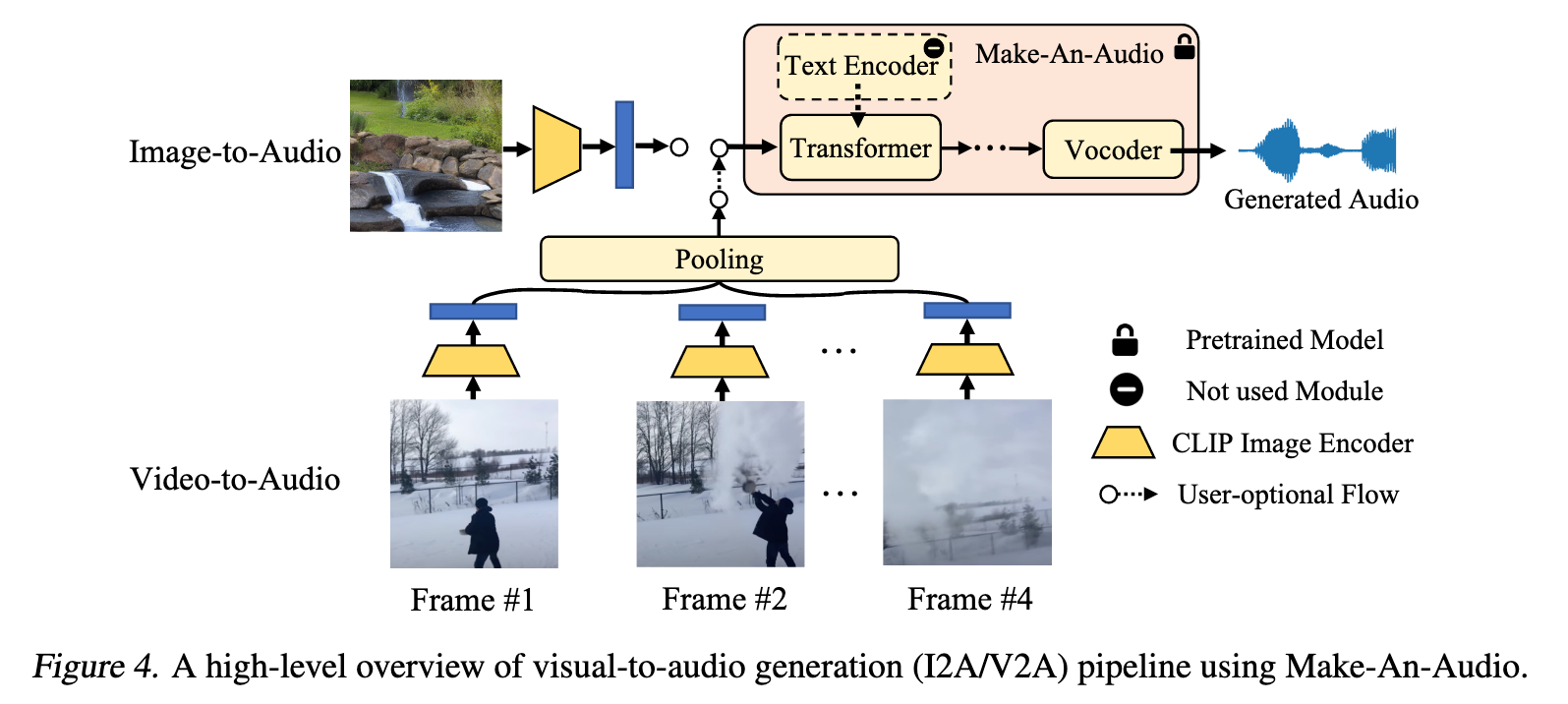
Pseudo Prompt Enhancement: Distill-then-Reprogram
It consists of two stages: an expert distillation approach to produce prompts aligned with audio, and a dynamic reprogramming procedure to construct a variety of concept compositions. (p. 3)
EXPERT DISTILLATION
To this end, experts jointly distill knowledge to construct a caption aligned with audio, following which we select from these candidates that endow high CLAP (Elizalde et al., 2022) score as the final caption (p. 3)
The original text-audio pair data has been randomly concatenated with the sampled events according to the template, constructing a new training example with varied concept compositions (p. 4)
Audio Representation
Our spectrogram auto-encoder is composed of 1) an encoder network E which takes samples x as input and outputs latent representations z; 2) a decoder network G reconstructs the mel-spectrogram signals x0 from the compressed representation z; and 3) a multi-window discriminator Dis learns to distinguish the generated samples G(z) from real ones in different multi-receptive fields of mel-spectrograms. (p. 4)
The whole system is trained end-to-end to minimize 1) Reconstruction loss Lre, which improves the training efficiency and the fidelity of the generated spectrograms; 2) GAN losses LGAN , where the discriminator and generator play an adversarial game; and 3) KL-penalty loss LKL, which restricts spectrogram encoders to learn standard z and avoid arbitrarily high-variance latent spaces. (p. 4)
Visual-To-Audio Generation
Experiment
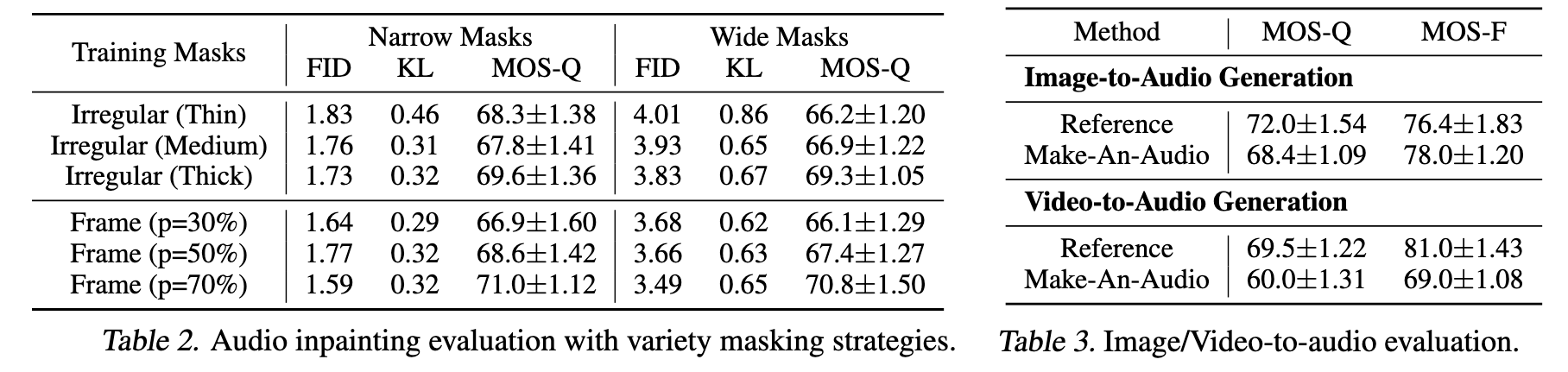
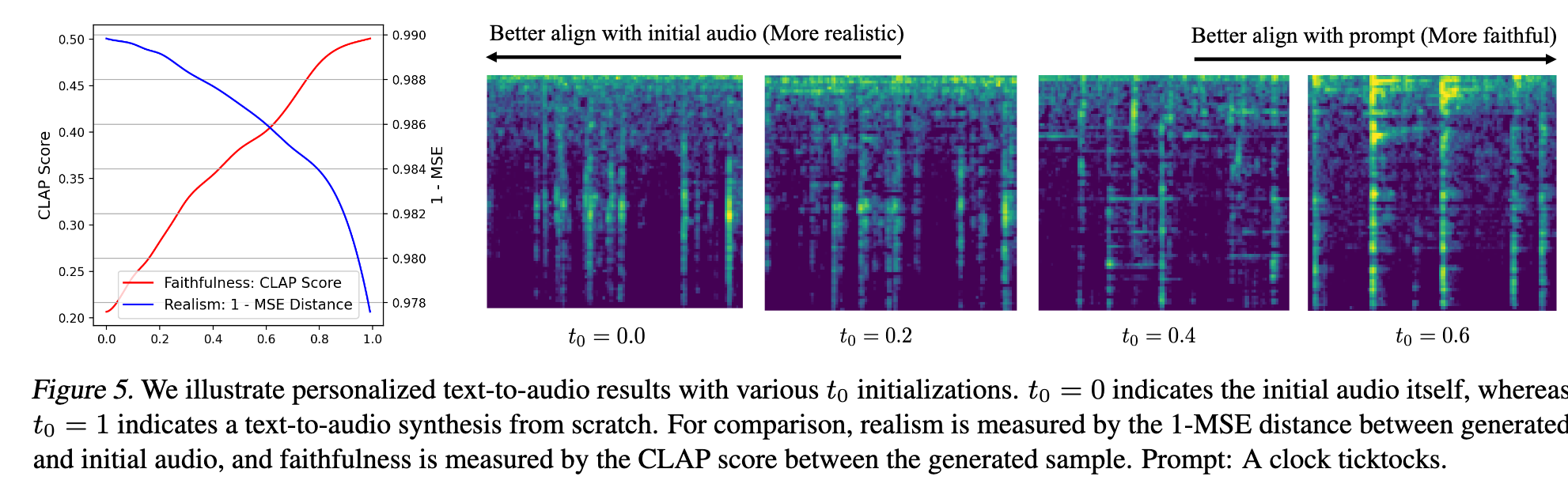
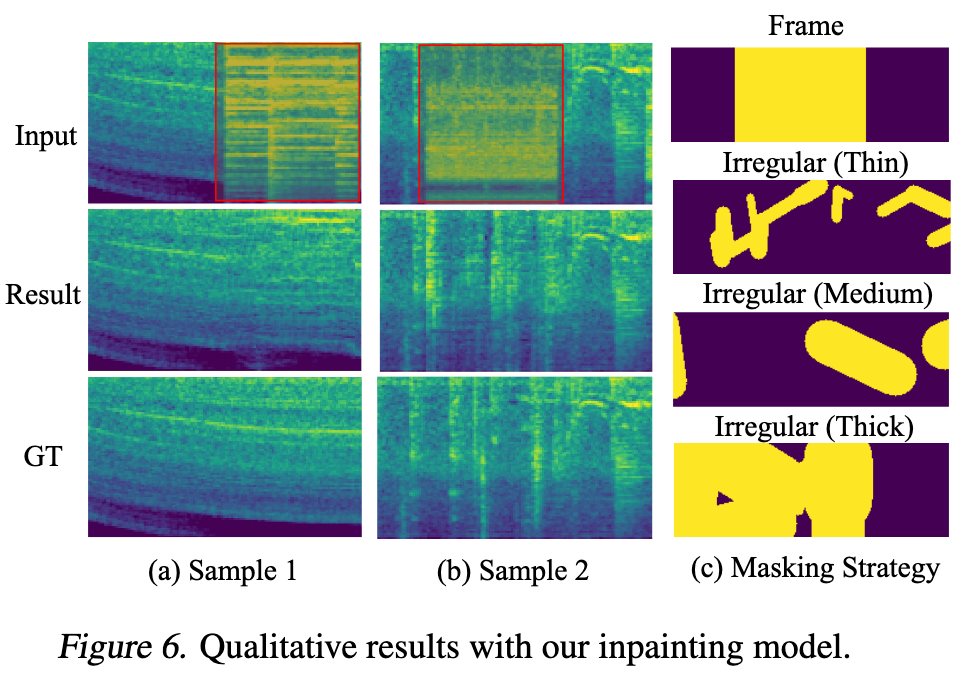
Analysis and Ablation Studies
TEXTUAL REPRESENTATION
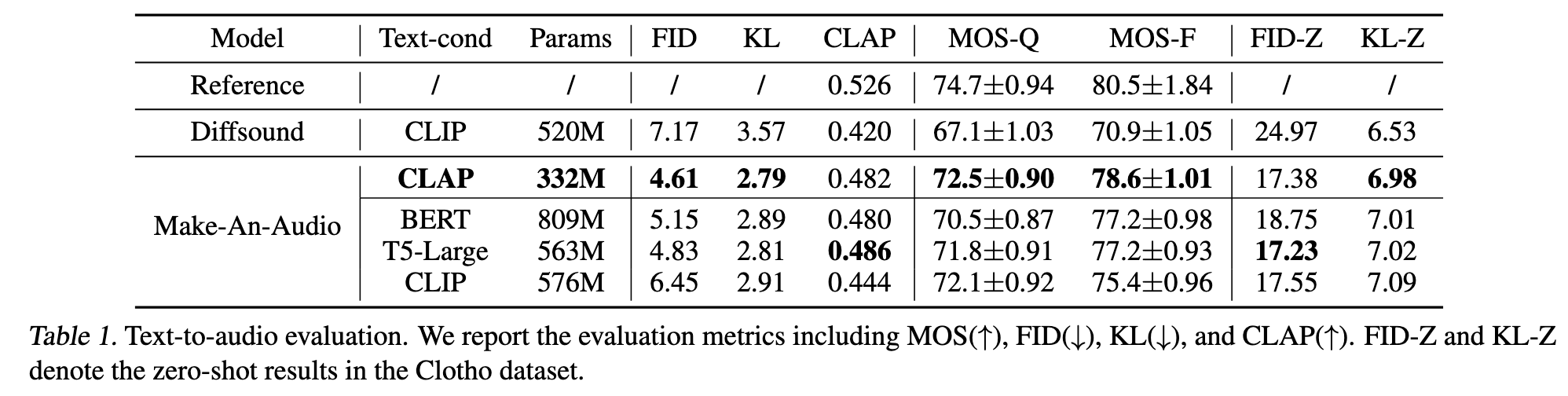
Since CLIP is introduced as a scalable approach for learning joint representations between text and images, it could be less useful in deriving semantic representation for T2A in contrast to Yang et al. (2022). CLAP and T5Large achieve similar performances on benchmarks dataset, while CLAP could be more computationally efficient (with only %59 params), without the need for offline computation of embeddings in large-scale language models. (p. 8)
PSEUDO PROMPT ENHANCEMENT
To highlight the effectiveness of the proposed dynamic reprogramming strategy to create unseen object compositions, we additionally train our Make-An-Audio in the static training dataset, and attach the results in Table 7 in Appendix E: 1) Removing the dynamic reprogramming approach results in a slight drop in evaluation; 2) When migrating to a more challenging scenario to Clotho in a zero-shot fashion, a significant degradation could be witnessed, demonstrating its effectiveness in constructing diverse object compositions for better generalization. (p. 8)