The effectiveness of MAE pre-pretraining for billion-scale pretraining
[transformer deep-learning self-supervised masked-auto-encoder weakly-self-supervised pre-training coca clip florence dino This is my reading note for The effectiveness of MAE pre-pretraining for billion-scale pretraining. This paper proposes a pre-pretraining method: starts with MAE and then hashtag based week supervised learning. It shows improvement on over 10 vision tasks and scales by model size as well as dataset size.
Introduction
While MAE has only been shown to scale with the size of models, we find that it scales with the size of the training dataset as well. (p. 1)
In this work we explore the combination of selfand weakly-supervised learning in a simple pre-pretraining framework, as follows. We first begin with the Masked Autoencoder (MAE) [33] self-supervised learning technique to pre-pretrain vision models without using any labels. After initializing from the pre-pretrained model, we use standard weakly supervised pretraining on billions of images with noisy labels. (p. 2)
Our study on large-scale pre-pretraining reveals that model initialization plays a significant role, even for webscale pretraining, and pre-pretraining is a simple and promising technique in that direction. In particular, we show that
- MAE not only scales with model size as shown in [33], but also with the size of the training data (Figure 2).
- Pre-pretraining improves both the model convergence and the final downstream performance for different sized models (millions to billions of parameters) trained on different sized datasets (millions to billions of images).
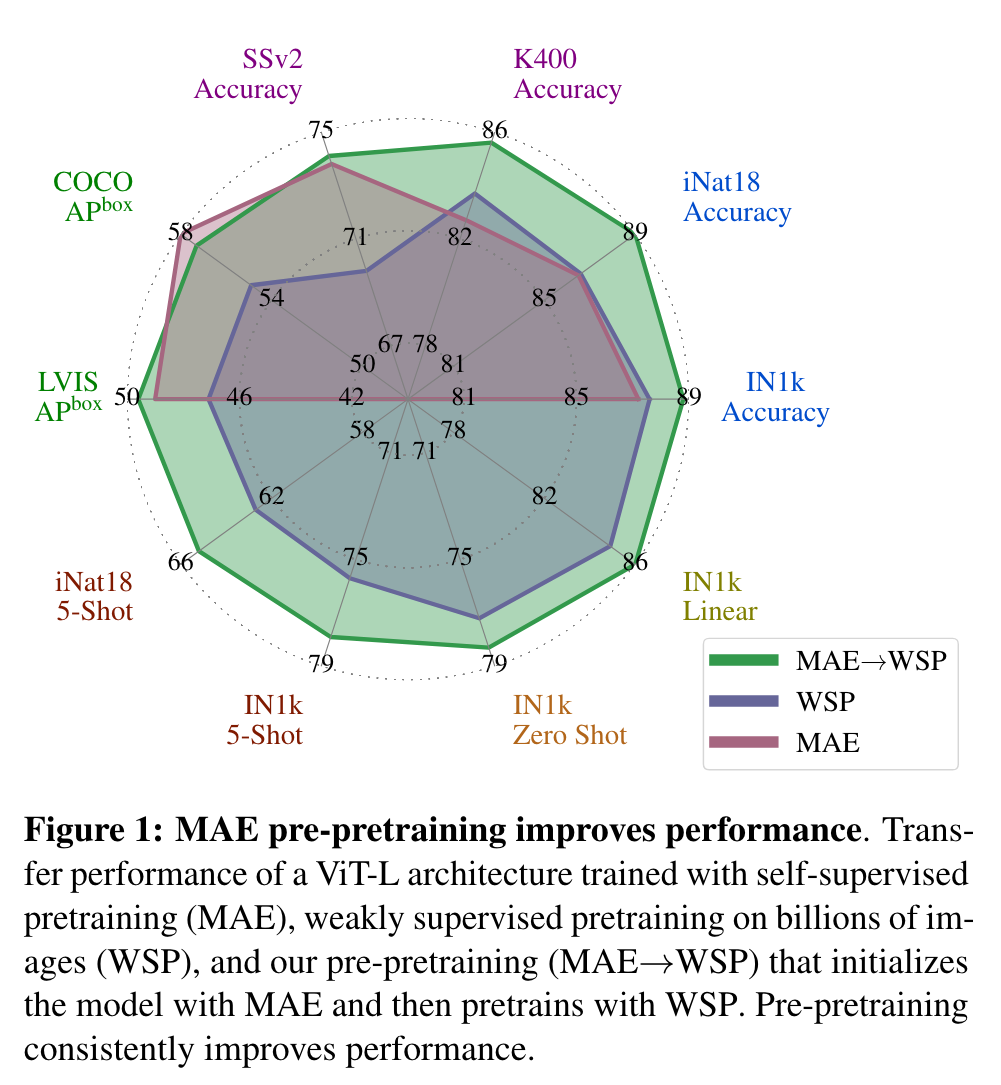
- Using pre-pretraining combines the benefits of both self-supervised learning and large scale weakly-supervised learning, and our models achieve excellent performance on a variety of different visual recognition tasks (Figure 1). (p. 2)
Related Work
- Self-supervised pretraining. Initial works focused on reconstructions methods [77] before moving to other pretraining tasks such as solving jigsaw puzzles [55], constrastive learning [15, 34] or joint embedding approaches [3, 4, 11, 12, 31, 89]. With the advent of Vision Transformers [23], approaches based on reconstructions such as [5, 33, 79] got renewed interest for their simplicity and state of the art performance. (p. 2)
- Weakly supervised pretraining (WSP). Of particular interest to us is the latter, i.e. approaches which leverage multi-label classification on noisy labels [27, 52, 70, 84] which have shown state of the art fine-tuning performance, and at the same time can be adapted using image-text data to gain zeroshot capabilities [85]. (p. 2)
Setup
Pre-pretraining (MAE). MAE randomly masks 75% of an image and trains the model to reconstruct the masked input image by minimizing the pixel reconstruction error. (p. 3)
Weakly-supervised pretraining (WSP). In particular, we focus on internet images and use their associated text information as supervision. We convert the text into a discrete set of labels, specifically leveraging hash-tag information [27, 52, 70]. We then use a multi-label classification loss to train models. (p. 3)
Experiments
We obtain labels using an automated process wherein we first obtain hashtags from the associated image captions, and then map the hashtags to WordNet synsets following [70]. Then perform supervised pretraining using the cross-entropy loss as described above. we train for 1 epoch on IG-3B (p. 4)
Scaling MAE pretraining to large data
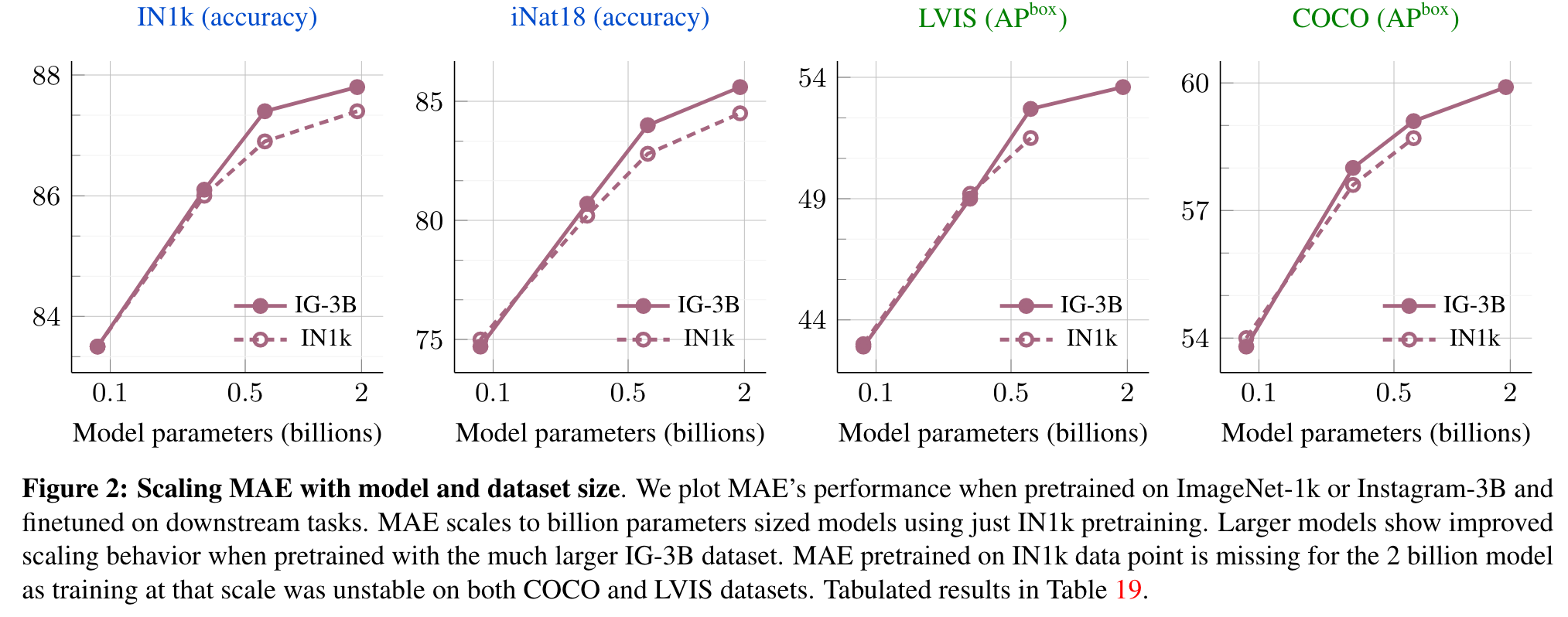
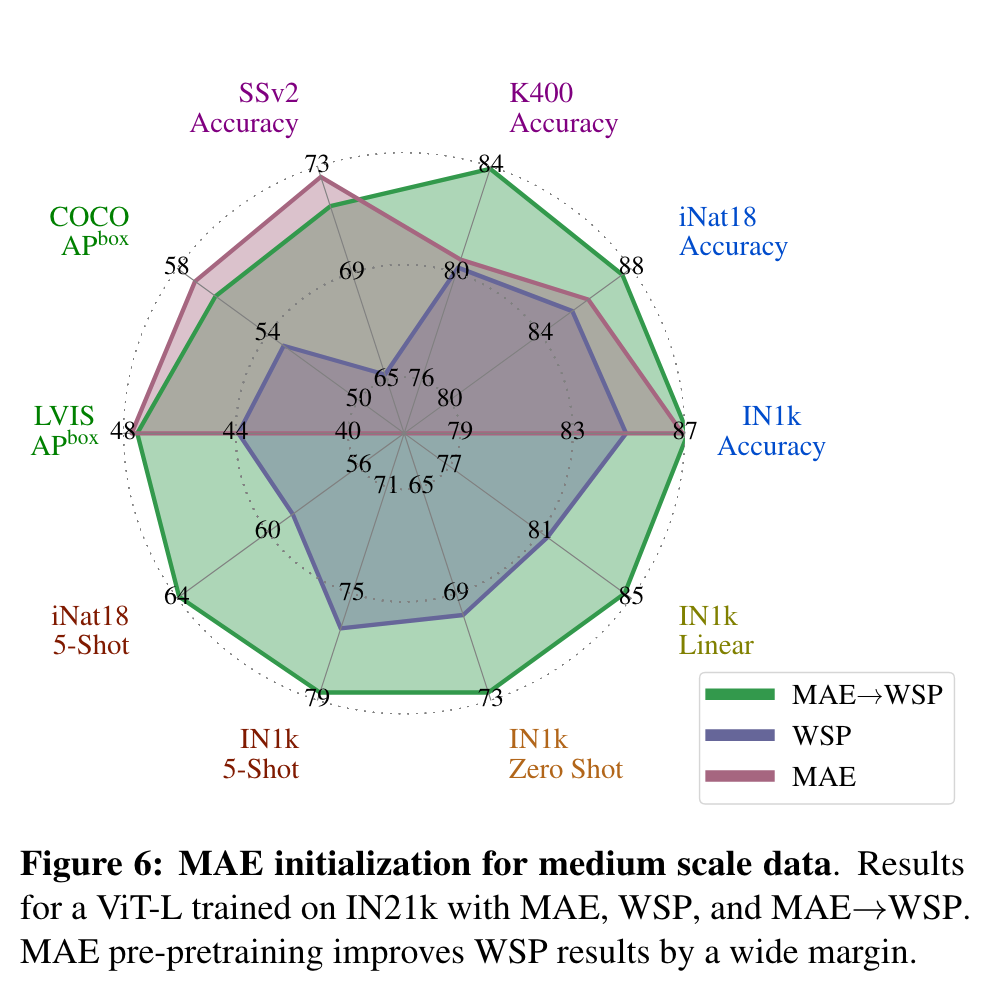
We observe that using the IG-3B data provides consistent gains over IN1k for all vision tasks, and the gain increases for larger models (p. 4)
MAE pre-pretraining
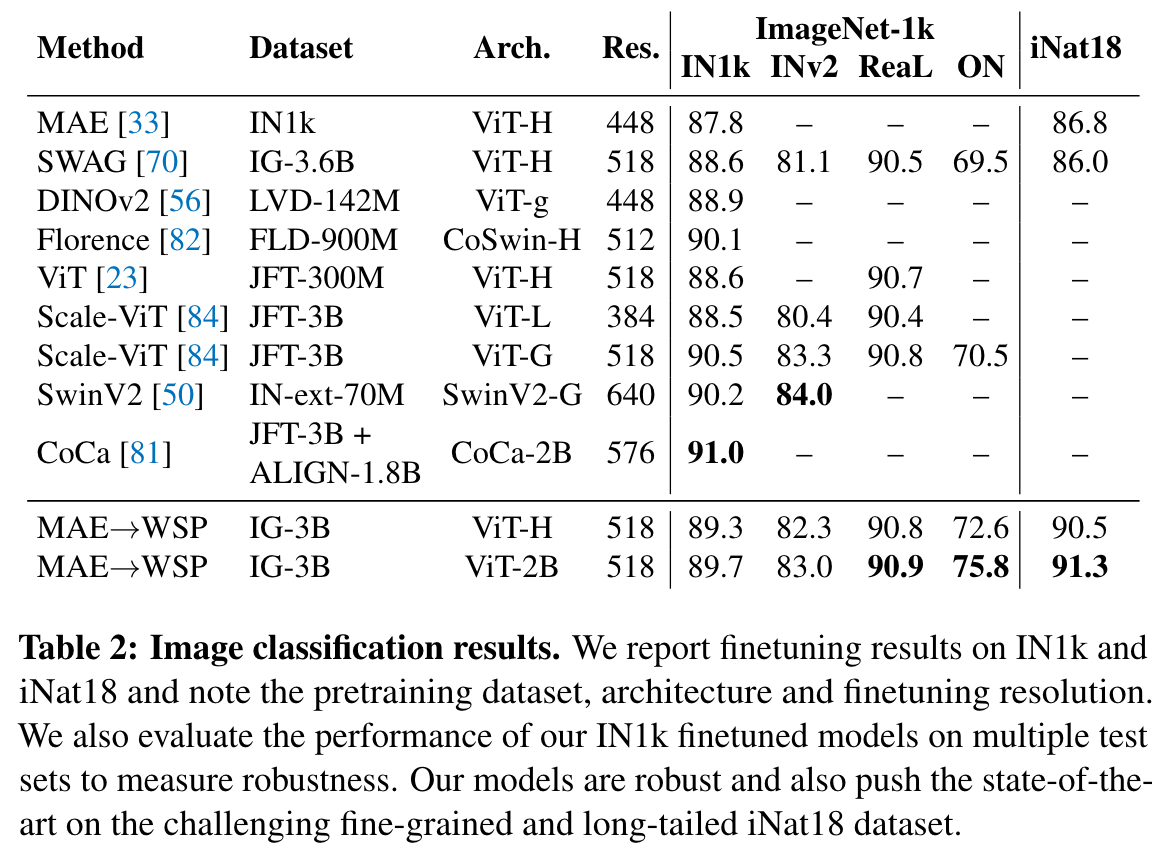
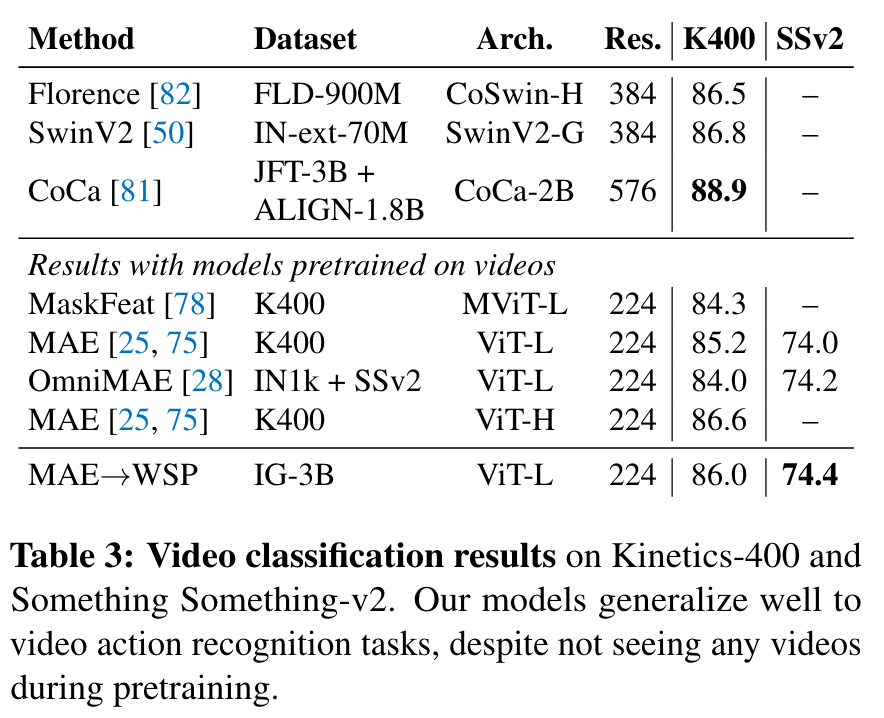
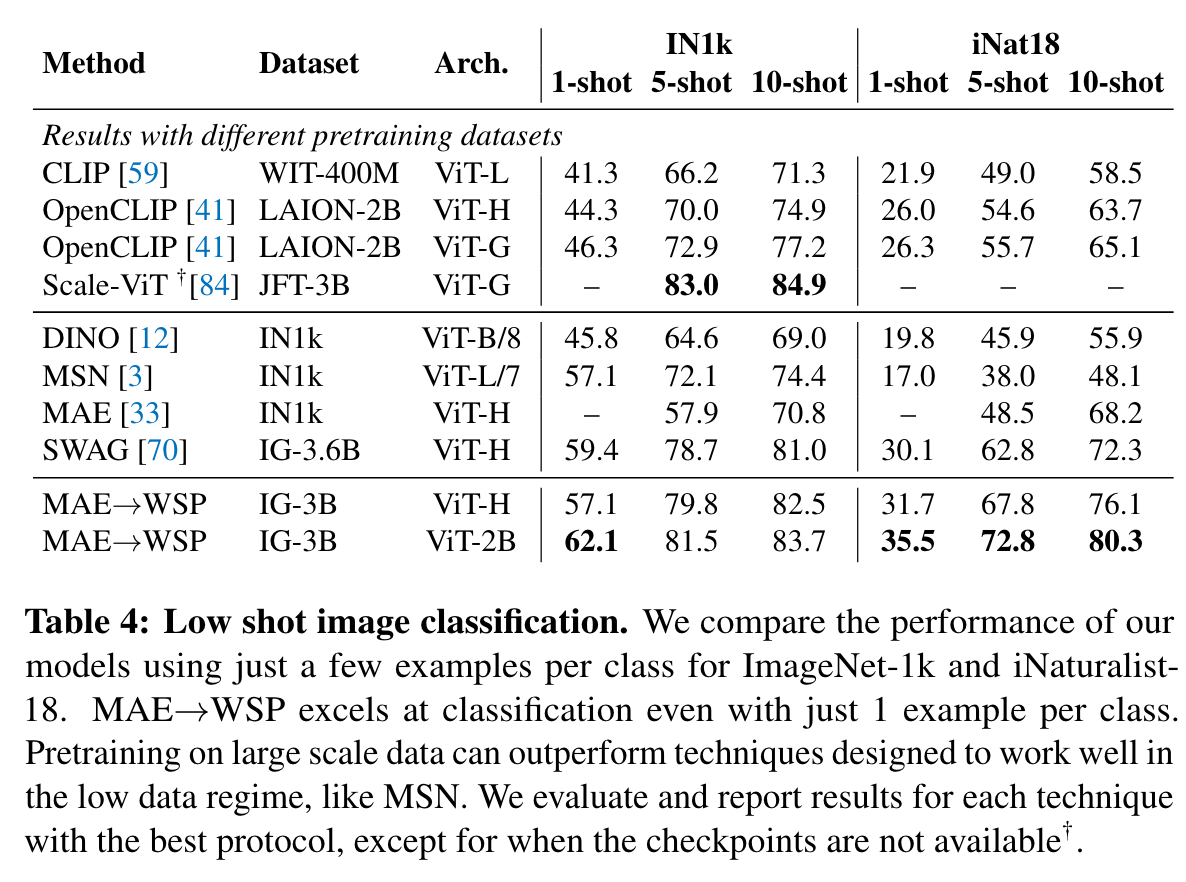
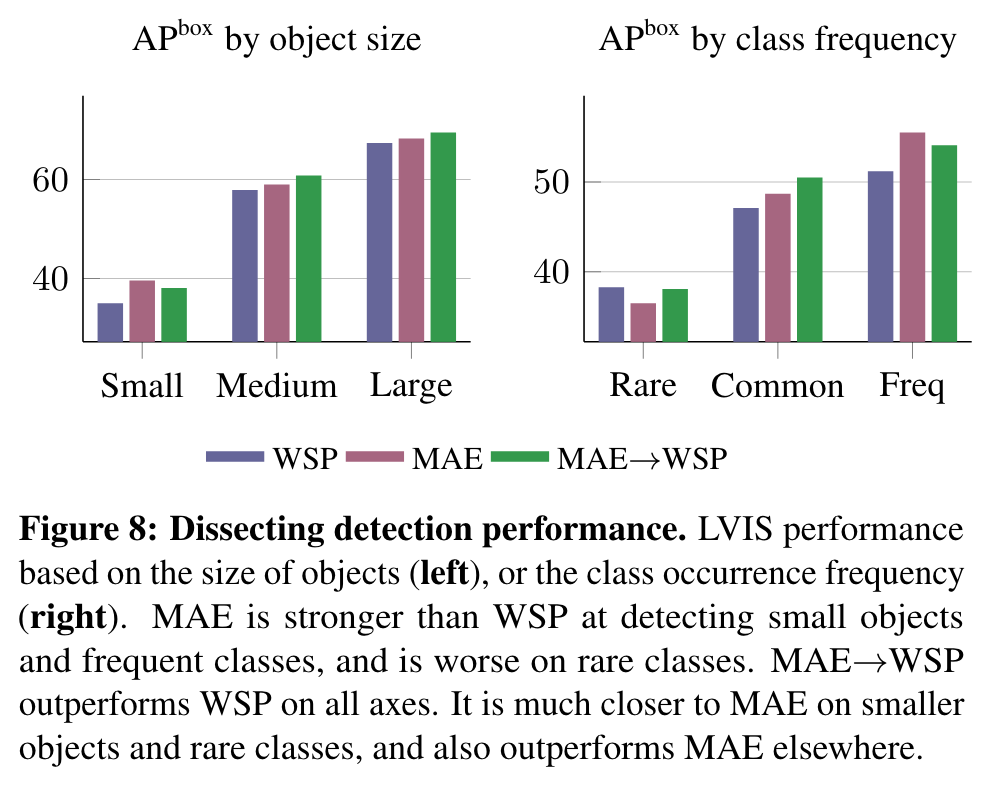
MAE has strong performance for object detection, and full finetuned image classification. However, MAE underperforms on tasks where the model is not finetuned, such as linear classifiers, zero-shot, or low-shot classification – situations where WSP performs better. For these evaluations MAE lags behind WSP by more than 10 points, which is why the results for MAE are not visible in Figure 1. For video classification, MAE performs significantly better than WSP on SSv2, but lags behind it on K400. (p. 4)
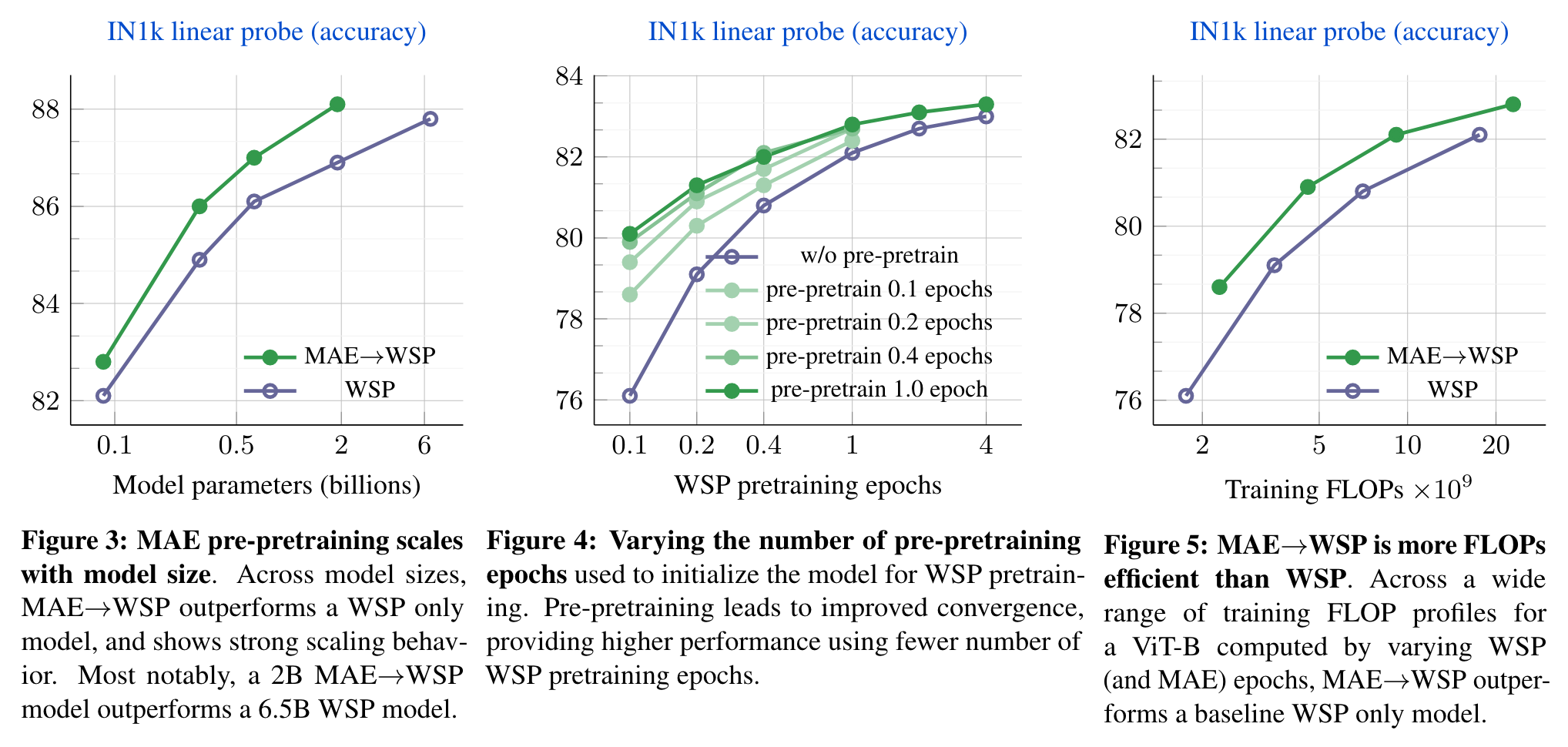
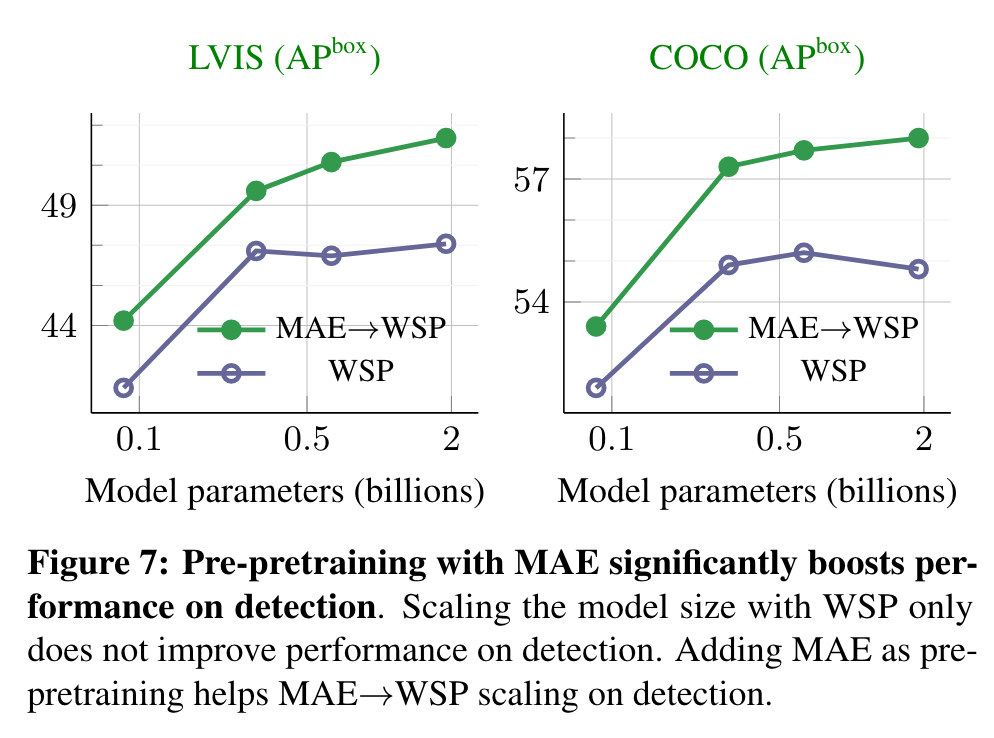
The gains over the WSP baseline increase for larger model sizes showing that pre-pretraining shows promising scaling behavior with model sizes. (p. 5)
Pre-pretraining improves results over the standard pretraining (random initialization, w/o pre-pretraining), and provides large gains with fewer WSP pretraining epochs. Pre-pretraining also leads to faster convergence since even a small amount of pre-pretraining for 0.1 epochs provides improvements. Increasing the epochs of pre-pretraining provide a larger improvement, and the gains saturate at 1 epoch of pre-pretraining. (p. 5)
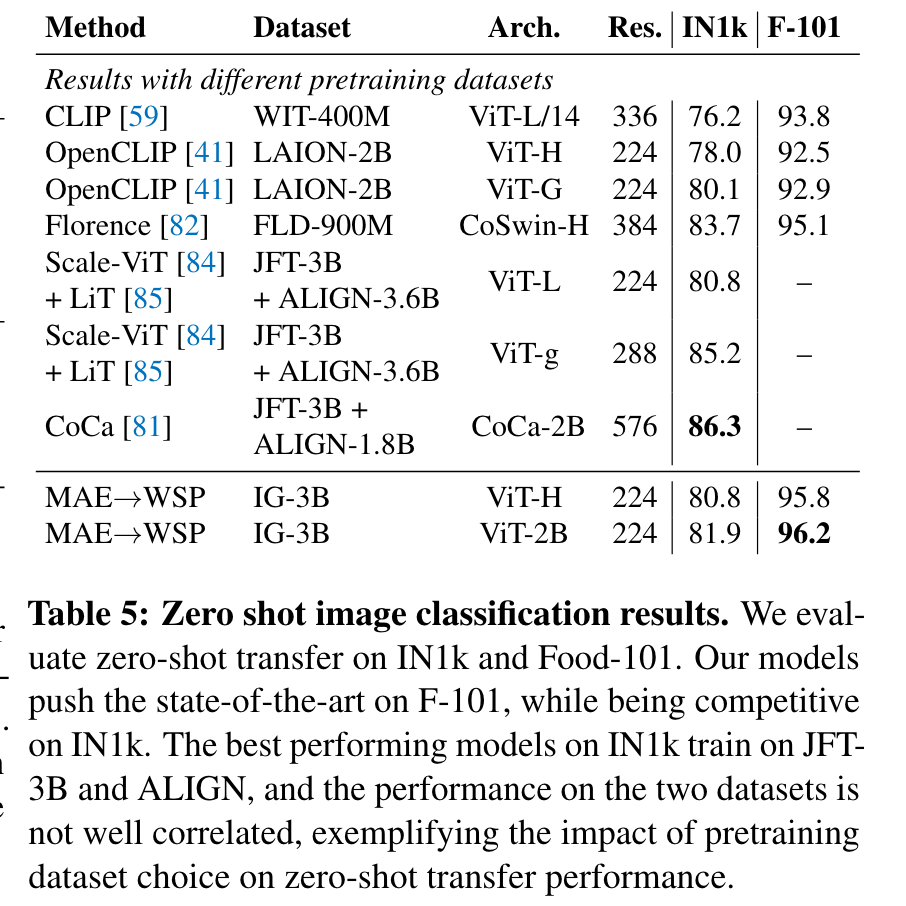
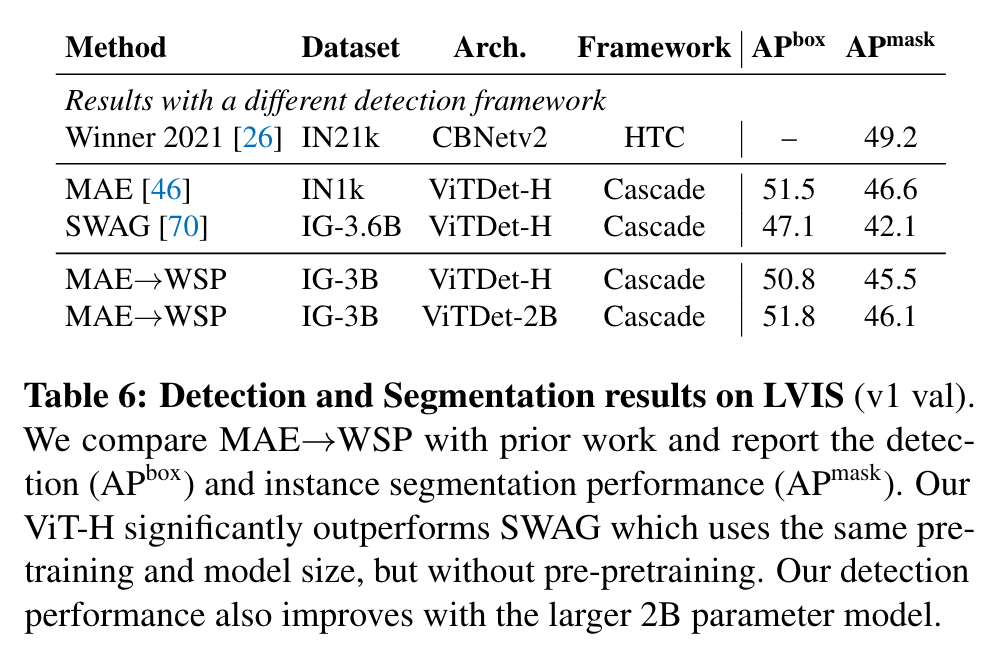
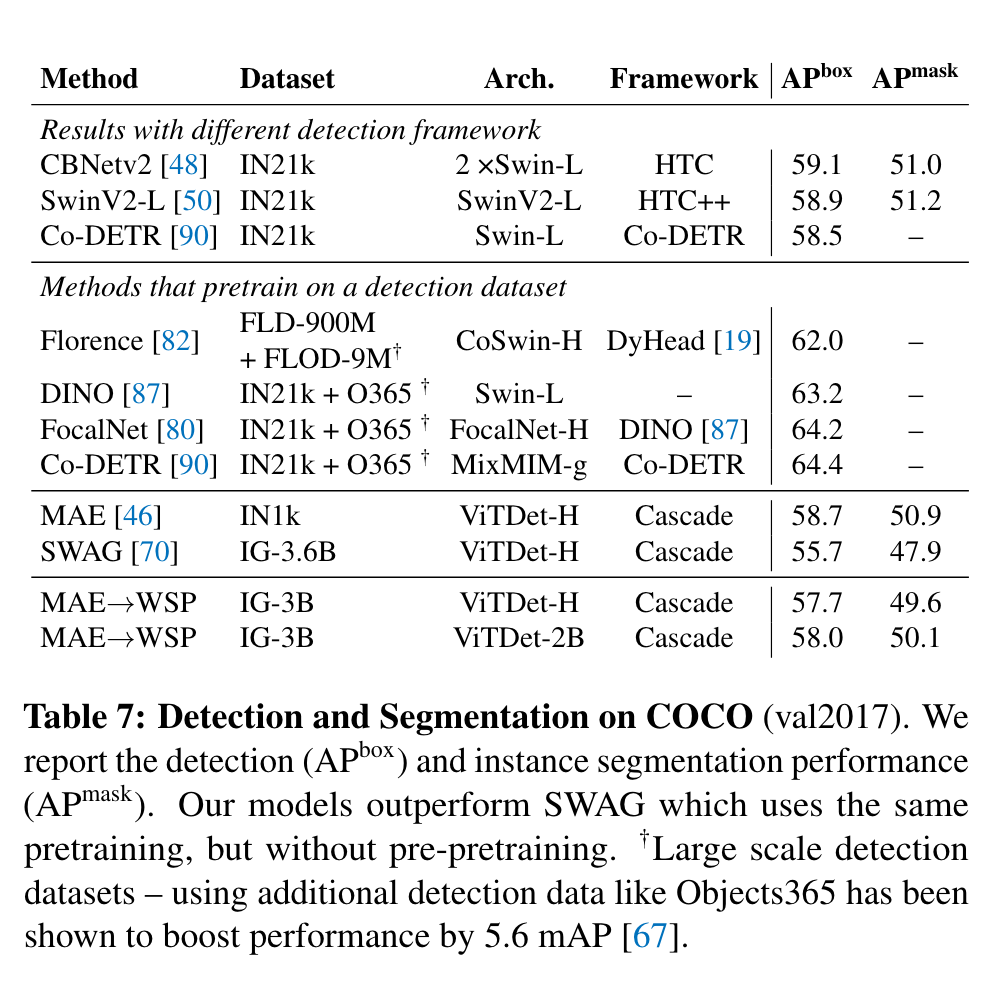
Other Results