OmniVL One Foundation Model for Image-Language and Video-Language Tasks
[transformer multimodal deep-learning omnivl clip align albef coca unicl blip florence flava univlp This is my reading note for OmniVL:One Foundation Model for Image-Language and Video-Language Tasks. The paper proposes a vision language pre-training method optimized to linear probe for classification problem. To this end, it modifies the contrast loss by creating positive. samples from the images of same label class.
Introduction
It adopts a unified transformer-based visual encoder for both image and video inputs, and thus can perform joint image-language and video-language pretraining. (p. 1)
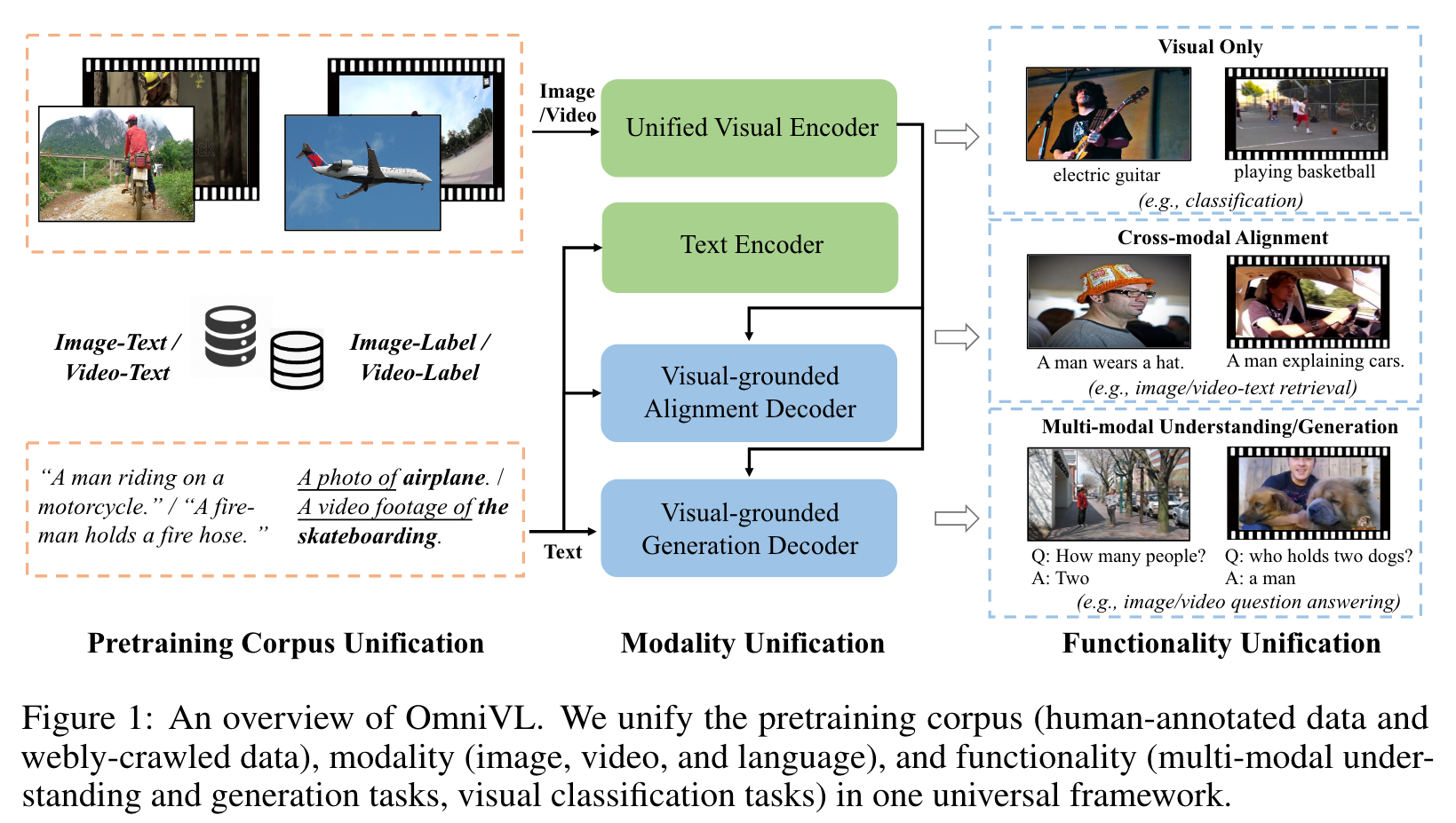
To this end, we propose a decoupled joint pretraining of image-language and video-language to effectively decompose the vision-language modeling into spatial and temporal dimensions and obtain performance boost on both image and video tasks. Moreover, we introduce a novel unified vision-language contrastive (UniVLC) loss to leverage image-text, video-text, image-label (e.g., image clas- sification), video-label (e.g., video action recognition) data together, so that both supervised and noisily supervised pretraining data are utilized as much as possible. Without incurring extra task-specific adaptors, OmniVL can simultaneously support visual only tasks (e.g., image classification, video action recognition), cross-modal alignment tasks (e.g., image/video-text retrieval), and multi-modal understanding and generation tasks (e.g., image/video question answering, captioning). (p. 1)
To support both image and video inputs, OmniVL adopts a unified transformer-based visual encoder to extract visual representations, where video inputs share most transformer layers with images except for the 3D patch tokenizer and temporal attention blocks [8]. (p. 2)
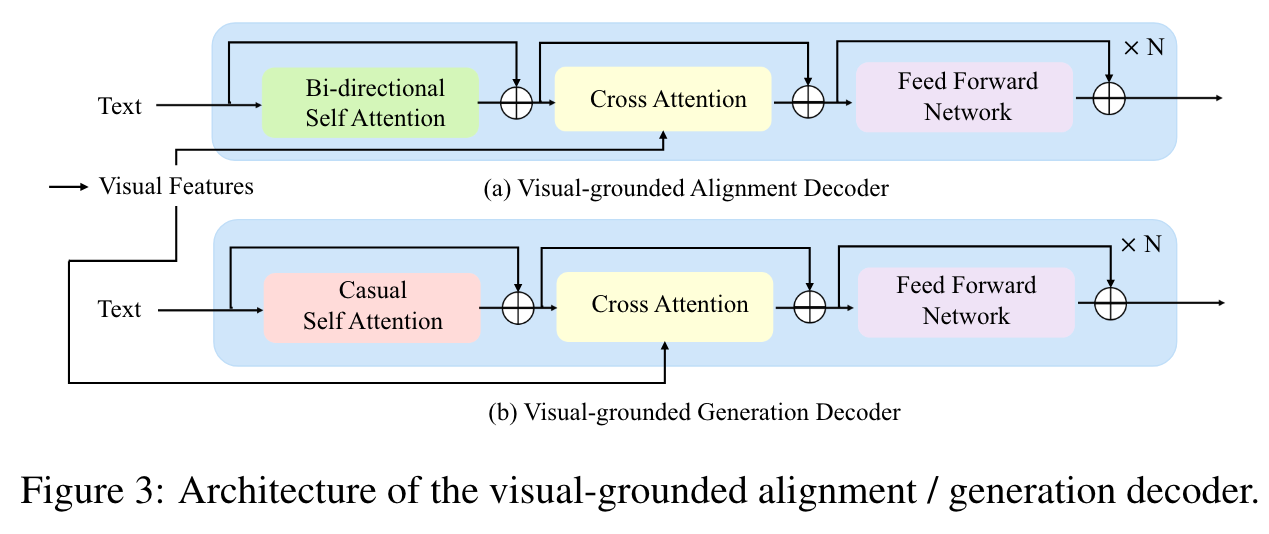
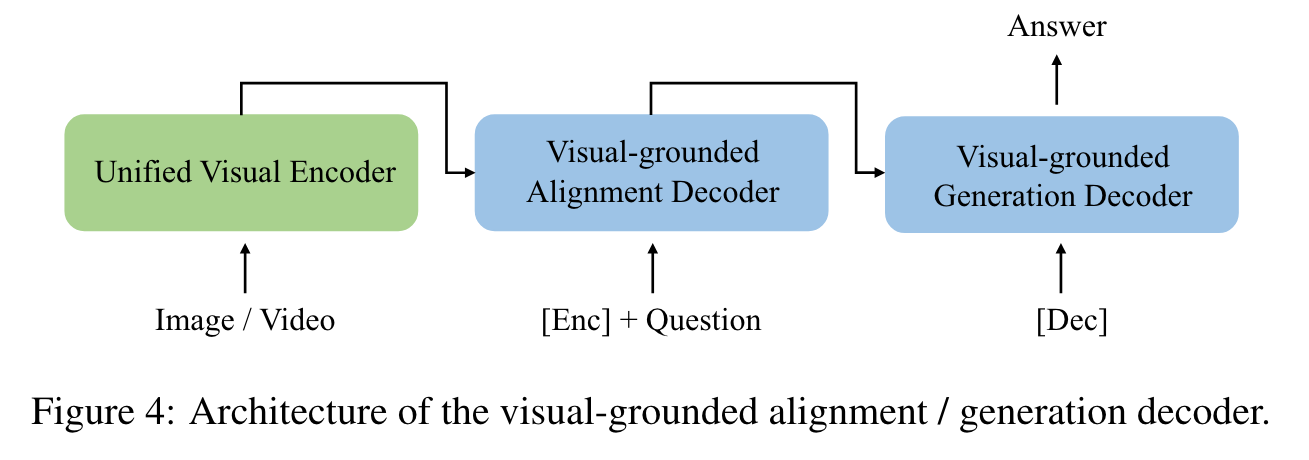
OmniVL follows an encoder-decoder structure with two visual-grounded decoders. One decoder is designed with bidirectional attention for visual-text semantic alignment, while the other is equipped with causal attention for text generation. (p. 2)
More specifically, we first pretrain on image- language to focus on spatial representation learning, and then do joint pretraining with video-language together to learn the temporal dynamics incrementally while preserving/polishing the well-learned spatial representations (p. 2)
Moreover, OmniVL is motivated by the unified contrastive learning [69] used in Florence [71], and extends its scope to cover video-text and video-label (e.g., video action recognition) data. (p. 2)
Related Work
Florence [71] further extends the scope of foundation models to cover Space-Time-Modality space and performs better especially on vision-only tasks with unified contrastive learning (p. 3)
To address this limitation, some recent works like FLAVA [55], BLIP [37] and CoCa [70] design one image-language foundation model to support both cross-modal alignment tasks and multi-modal generation tasks (p. 3)
Methodology
Overall Framework
Unified Visual Encoder
We unify images and videos in a transformer-based visual encoder by converting both of them into a series of tokens, where the independent 2D/3D convolution-based patch tokenizers are used for image/video respectively. Accordingly, spatial and temporal positional encodings are added to the input tokens to incorporate positional information. For the transformer structure, we follow TimeSformer [8] to employ decoupled spatial-temporal attention, which individ- ually models the static spatial appearance and temporal dynamics in visual data. Specifically, within each transformer block, we sequentially perform temporal self-attention and spatial self-attention. The temporal self-attention blocks will be automatically skipped for the image inputs. The final visual representation vcls is obtained from the [CLS] token of the last block. Note that we share the model weights for image and video inputs except for the temporal self-attention (p. 4)
Text Encoder
We adopt BERT [17] as the Text Encoder, which transforms input text into a sequence of token embeddings. The embedding of [CLS] token wcls is used as the language representation. (p. 4)
Visual-grounded Alignment Decoder
we employ an extra visual-grounded alignment decoder to further facilitate the learning and enhance the alignment accuracy like [37, 23]. Additionally, a task-specific [ENC] token is added to the input text, the output embedding of which will be used as the fused cross-modal representation. (p. 4)
Visual-grounded Generation Decoder
We empower our model to own the multi-modal generation capability by attaching a visual-grounded text generation decoder. It adopts the similar architecture to the above alignment decoder, but replaces the bidirectional self-attention with causal self-attention. A [DEC] token and an [EOS] token are added to indicate the task type and signal the end, separately. (p. 4)
Pre-training Objectives
Three pre-training objectives are used:
- Unified Vision-Language Contrastive (UniVLC) Loss
- Vision-Language Matching (VLM) Loss
- Language Modeling (LM) Loss
Unified Vision-Language Contrastive (UniVLC) Loss
y ∈ Y is the unique label indicating the index of the grouped language description in the whole pretrain dataset. Note that in this joint visual-label-text space, visual data from manually-annotated dataset belonging to the same category shares the common textual description. (p. 5)
To enjoy a large batch size for contrastive learning, we maintain three memory banks as [25, 38] to store the most recent M visual vectors {v_m}^M_{m=1} and text vectors {w_m}^M_{m=1} from the momentum encoders, and the corresponding labels {y_m}^M_{m=1}. (p. 5)
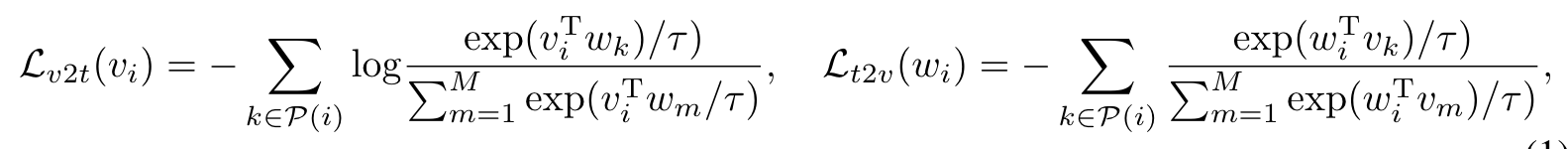
| where k ∈ P(i) = {k | k ∈ M, y_k = y_i} (p. 5) |
Pretraining Corpus and Paradigms
Extensions
Implementation
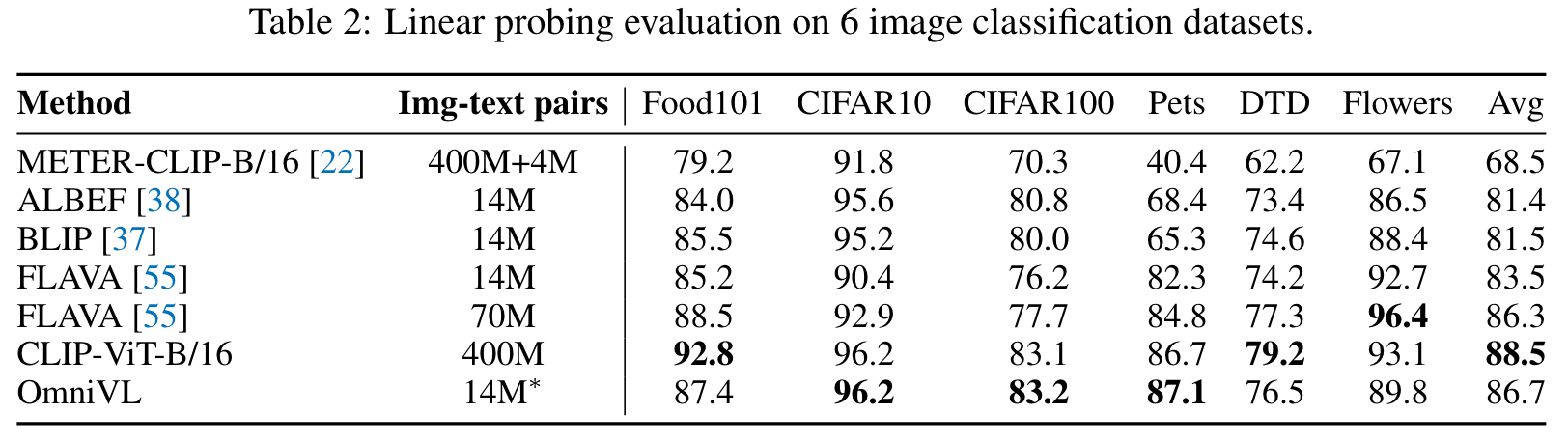
For the image-language pretraining stage, we initialize spatial attention with ViT-B/16 [21] pretrained on ImageNet-1K [16]. We take random image crops of resolution 224 × 224 as inputs and apply RandAugment [15]. The model is pretrained for 20 epochs using a batch size of 2880. For the joint pretraining, we sparsely sample 8 × 224 × 224 video clips, and train the model for 10 epochs with a batch size of 800 for video data and 2880 for image data. Our joint pretraining alternates batches between the image and video data. The model is optimized with AdamW [44] using a weight decay of 0.05. The learning rate is warmed-up to 3e-4 (image) / 8e-5 (joint) and decayed linearly with a rate of 0.85. (p. 6)
Experiments
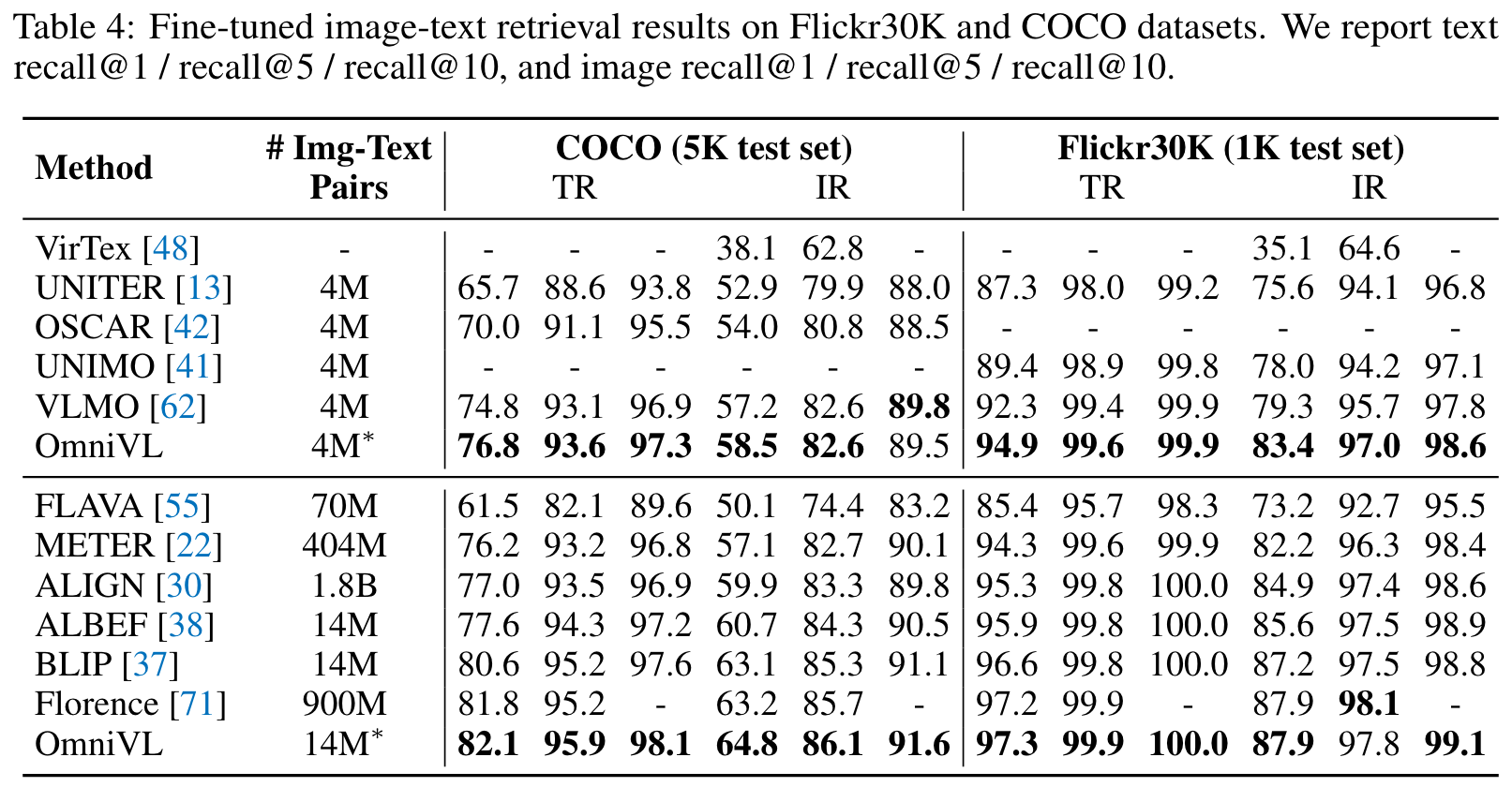
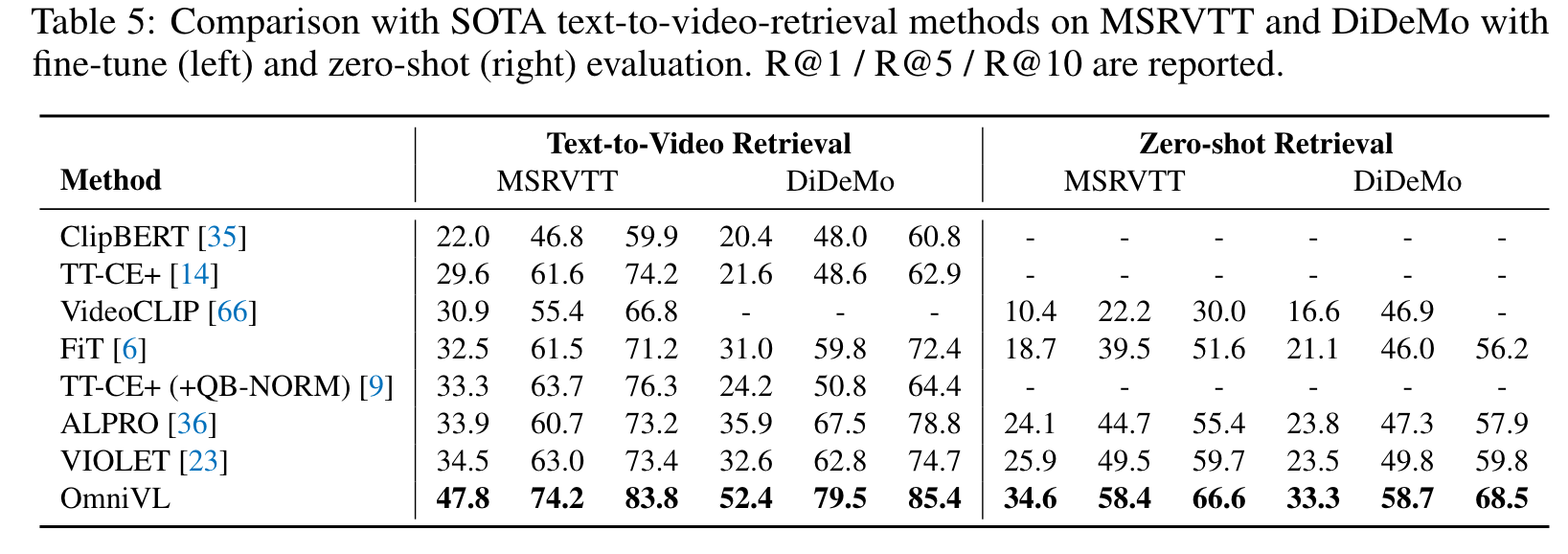
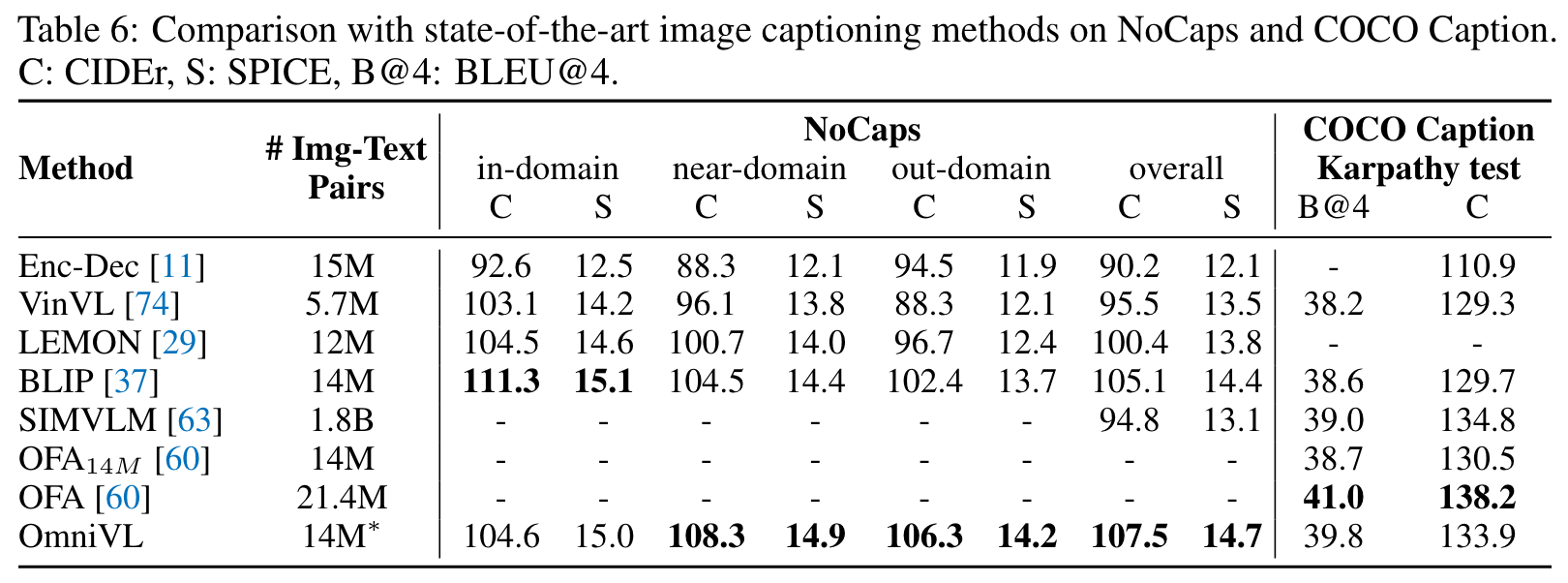


Ablation Study
Decoupled Joint Pretraining
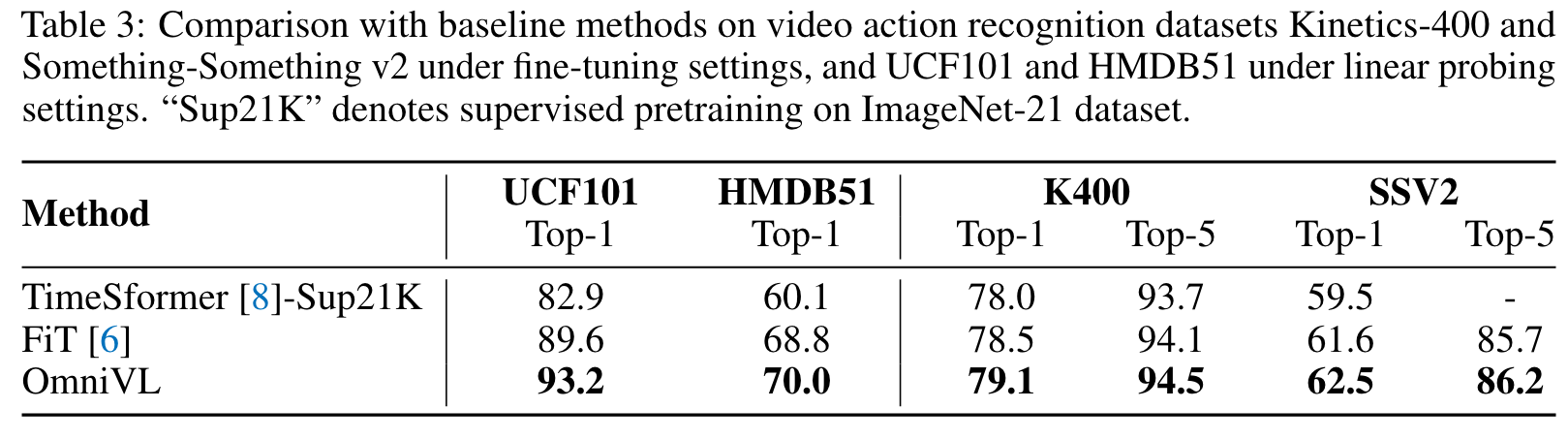
To verify the effect of decoupled joint pretraining, we conduct four ablation experiments with different pretraining strategies: image-only pretraining, video-only pretraining, joint pretraining from scratch, and Img2Vid pretraining where we first pretrain OmniVL on image and then on video. (p. 9)
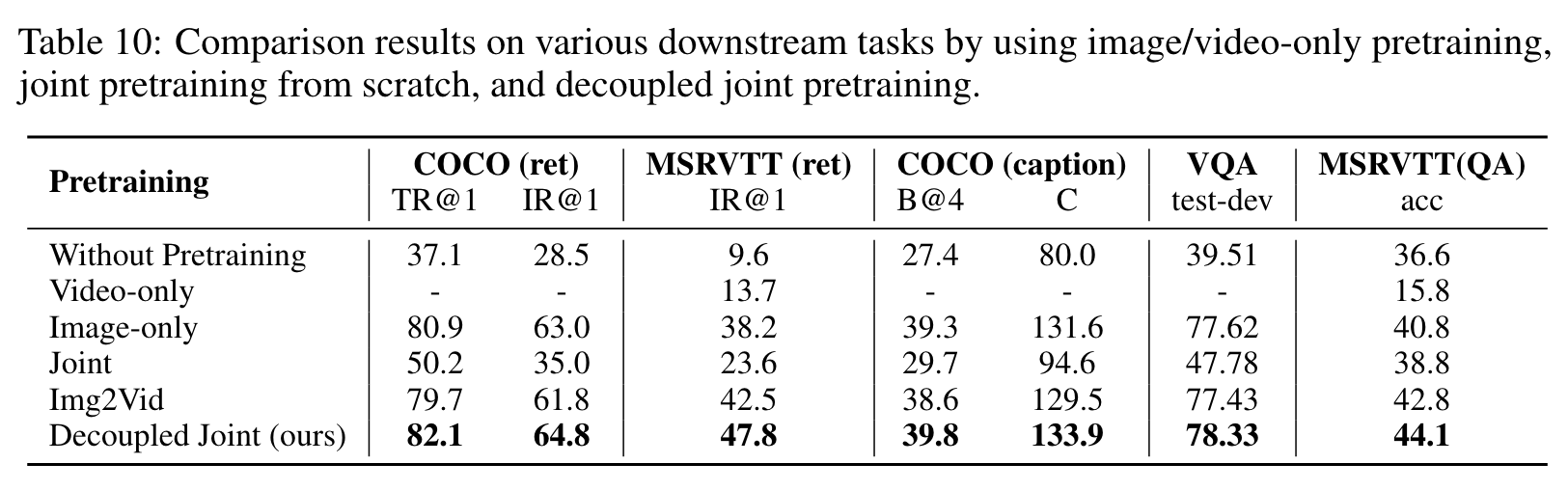
Compared to video-only pretraining, joint pretraining from scratch can significantly improve the performance on video tasks, which has also been verified in [6, 23]. However, it produces limited results on image tasks, which is even worse than image-only pretraining. Img2Vid is another competitive baseline, which however demonstrates degraded performance on image tasks compared to image-only pretraining. This indicates the naive combination of image-language and video-language cannot enjoy their synergy. (p. 10)
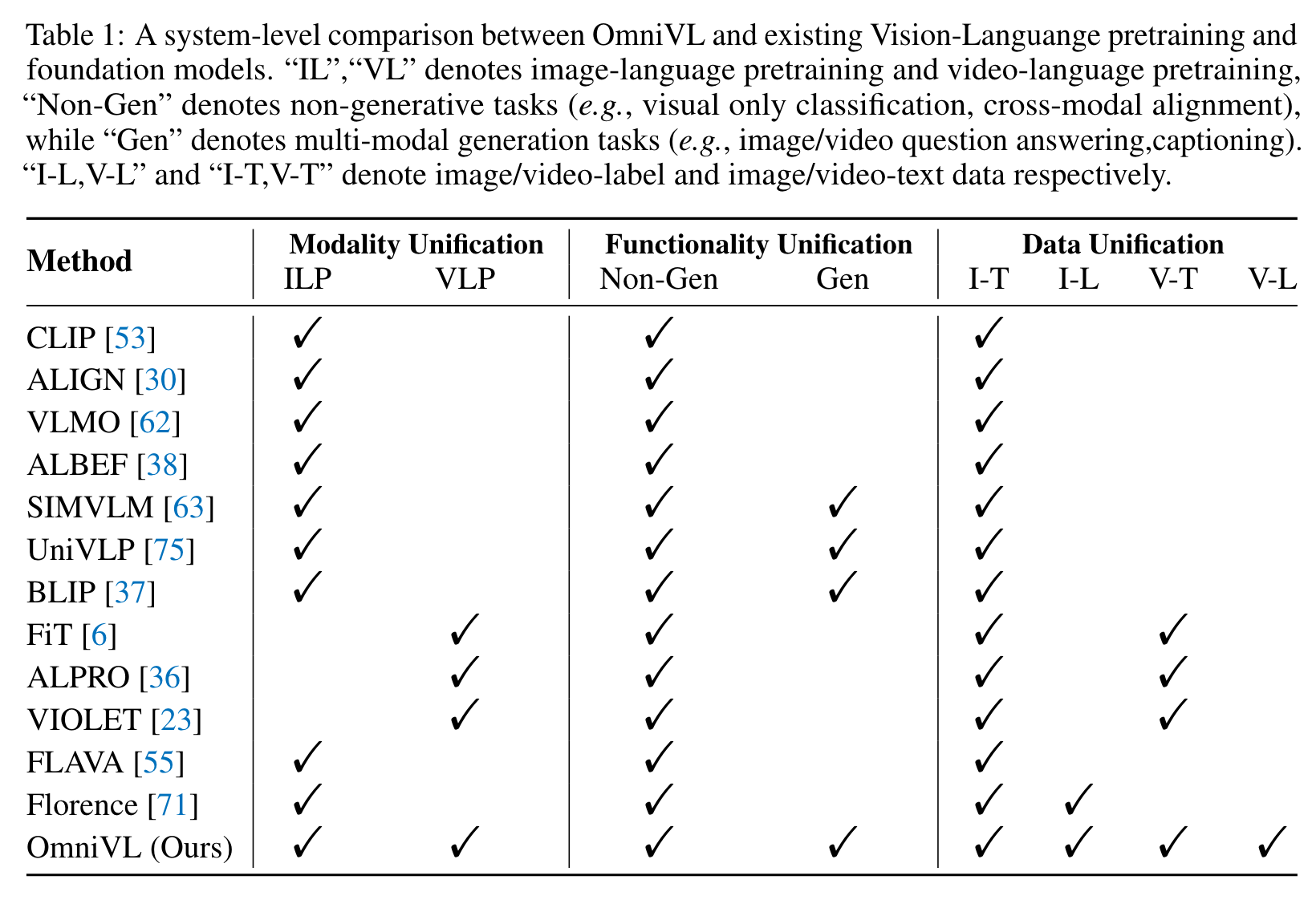
UniVLC Loss
The example results shown in Figure 2 illustrate that our method performs comparably to vanilla contrast-based model on vision-language tasks, e.g., image/video-text retrieval, image captioning, and image/video question answering. But on visual only tasks, e.g., linear probing for image/video classification and video action recognition fine-tuning, the performance gain is much higher, indicating that UniVLC could facilitate model to learn more discriminative visual representations and benefit transfer learning tasks. (p. 10)