Otter A Multi-Modal Model with In-Context Instruction Tuning
[multimodal mm-react bad mimic-it llava deep-learning cola hugging-gpt flamingo instruct-gpt llm blip visual-chat-gpt llama dataset open-flamingo otter viper-gpt mini-gpt x-gpt This is my reading note for Otter: A Multi-Modal Model with In-Context Instruction Tuning. It is a replication of Flamingo model trained on MIMIC-IT: Multi-Modal In-Context Instruction Tuning.
Introduction
Recent studies have highlighted the importance of instruction tuning in empowering LLMs, as exemplified by the boosting of GPT-3 [6] to InstrctGPT [22] and ChatGPT [20], which follows natural language instructions effectively to accomplish real-world tasks and allows for customizing task-specific rules into instructions during downstream fine-tuning, enabling pre-trained models to comprehend user intents more effectively and produce accurate and relevant responses. (p. 1)
For instance, a common practice is to use image-text data pairs from Caption [16] or VQA [11] tasks to align visual and language modules. While embedding visual information into the language model in this way can be effective, we question whether this practice is inherently task-dependent, as it relies on the task for which the data is used to train the alignment module.
Upon reflection, we have discovered that DeepMind Flamingo’s [1] upstream pretraining dataset, MultiModal MassiveWeb (M3W), has significant value in aligning visual and language information in a more natural manner. The dataset comprises HTML webpages, where all images and texts are arranged in an interleaved format. Specifically, a piece of text may describe an image (or videos) above or below it, and correlations may exist between images (or videos) and text in adjacent positions. This natural organization of context provides richer information than a caption dataset, where text only describes its corresponding image. (p. 2)
Although the OpenFlamingo model exhibits impressive multi-modal in-context learning abilities and executes tasks with given in-context examples, as an upstream pre-trained model, it still requires instruction tuning to perform downstream tasks more effectively. (p. 2)
Related Work
System Design Perspective
This perspective involves using ChatGPT [20] as a dispatch scheduler and connecting different expert models through it to allow for different visual tasks. Language prompts serve as an interface to call expert visual-language models within their respective task domains. Works in this category include VisualChatGPT [35], HuggingGPT [29], Cola [8], XGPT [42], MM-REACT [37], and ViperGPT [31]. (p. 3)
End-to-End Trainable Models Perspective
This perspective focuses on connecting models from different modalities into integrated end-to-end trainable models, also known as multi-modal foundation models. (p. 3)
Early works in this field include Flamingo [1], which proposes a unified architecture for modeling language and vision and was later open-sourced as OpenFlamingo [4] by LAIONAI. Other earlier works include BLIP-2 [15], which uses a lightweight Querying Transformer and two-stage bootstrap pretraining to connect information from the image to text modality (p. 3)
Academic multi-modal efforts include a variety of models such as LLaMA-Adapters [38], Mini-GPT4 [39], and LLaVA [17]. LLaMA-Adapters aims to adapt LLaMA [33] into an instructionfollowing model with an additional adapters module and multi-modal prompts (p. 3)
Data
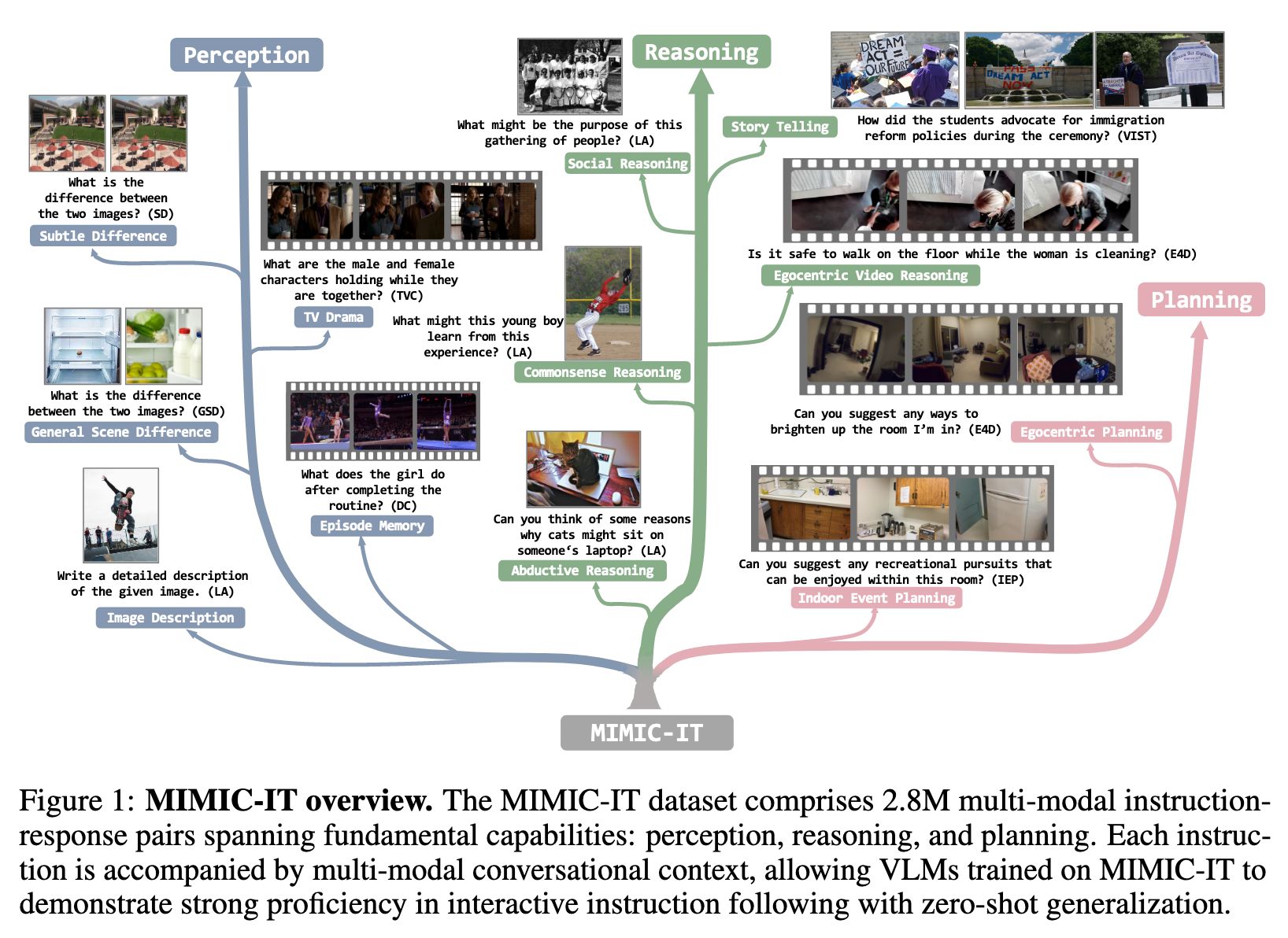

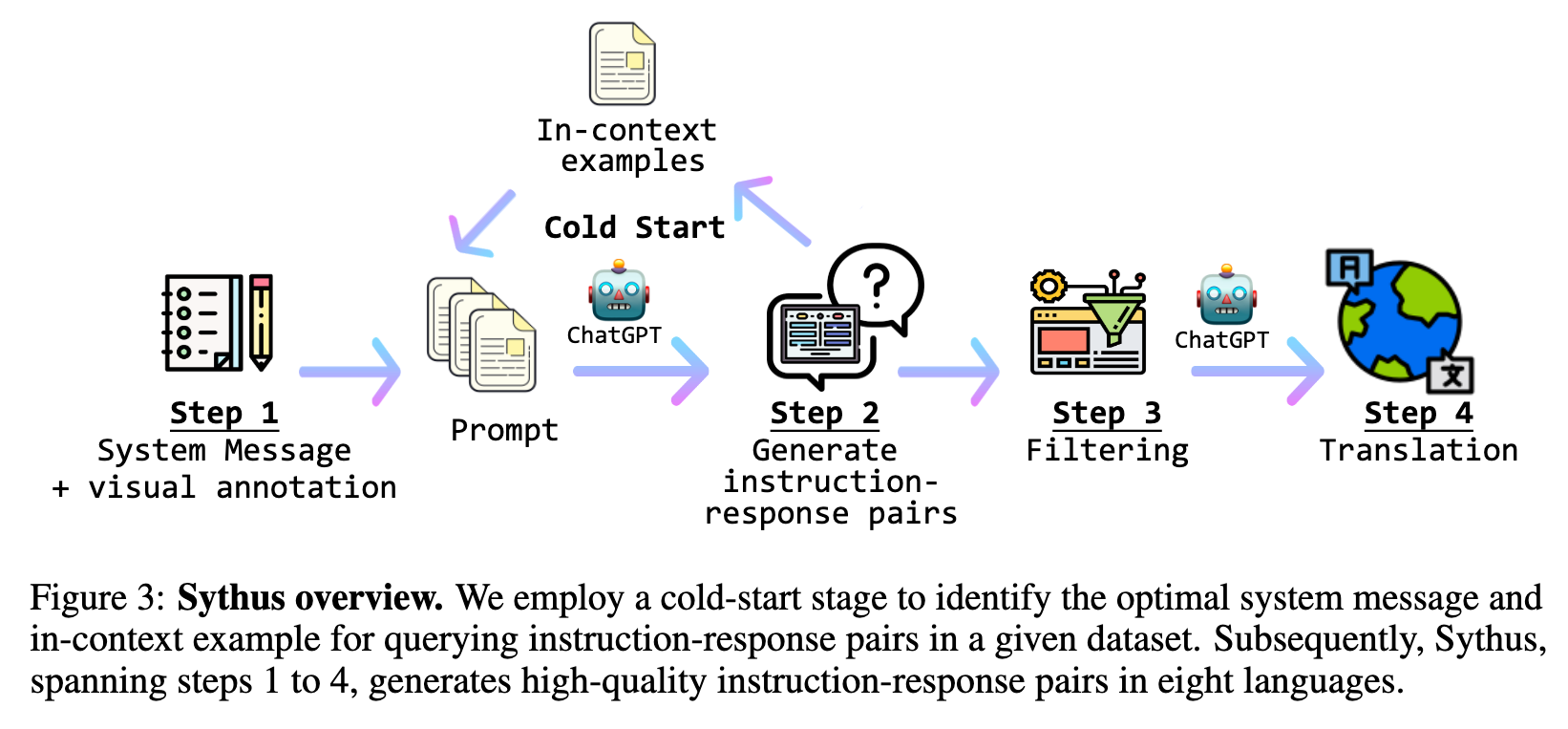
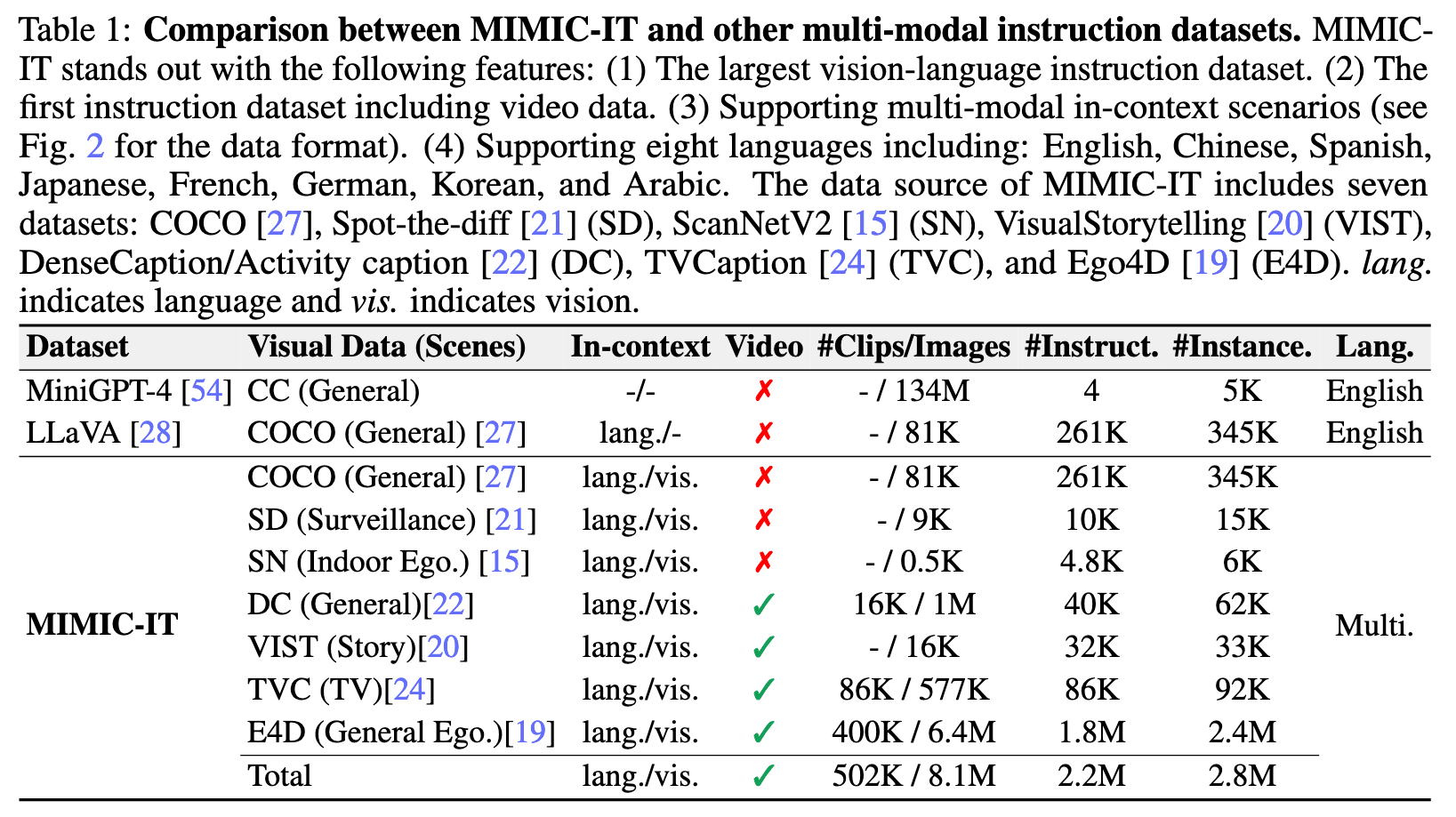
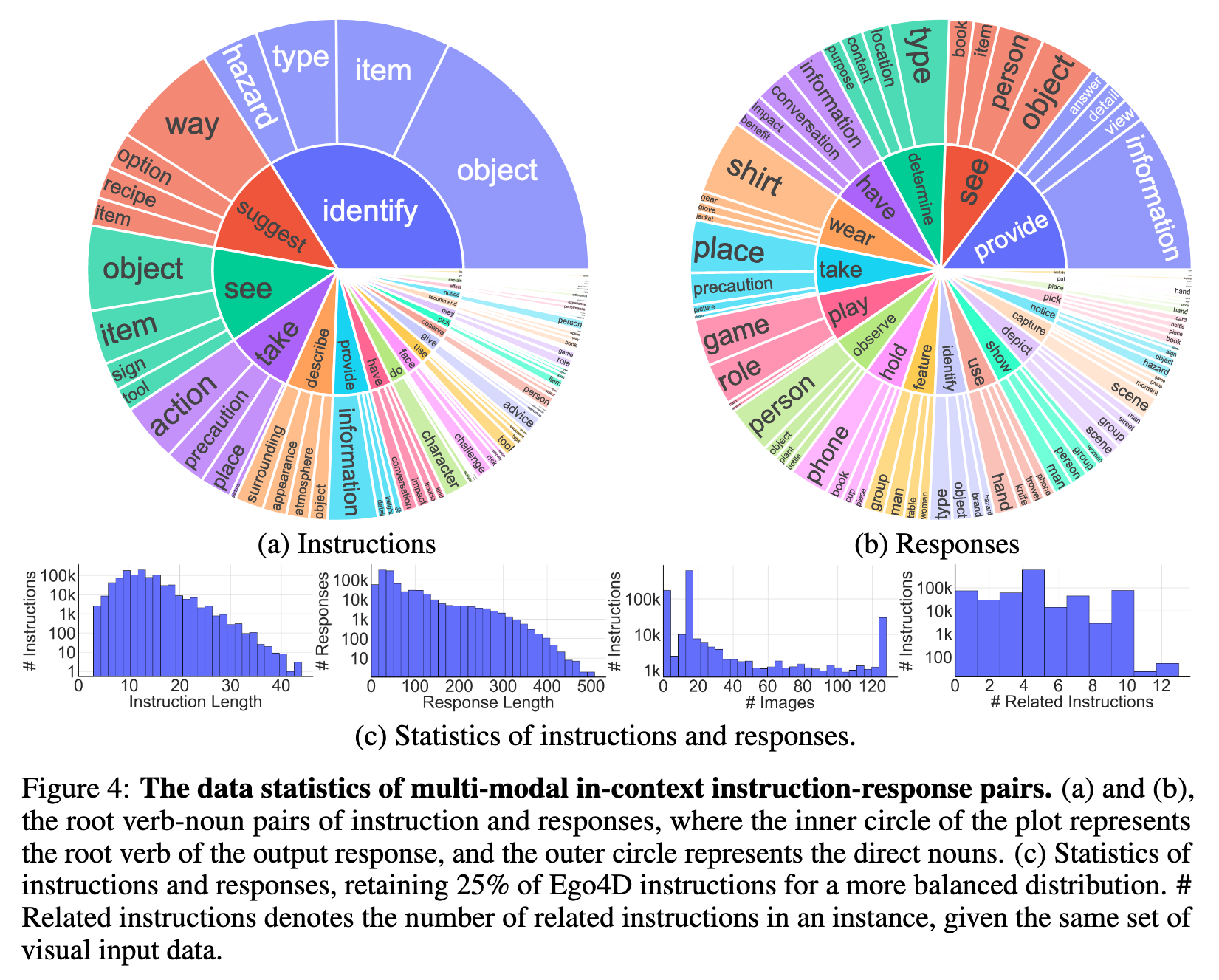

Method
Specifically, each MIMIC-IT data sample consists of (i) a queried image-instruction-answer triplet, with the instruction-answer tailored to the image, and (ii) context. The context contains a series of image-instruction-answer triplets that contextually correlate with the queried triplet, emulating the relationship between the context and the queried image-text pair found in the MMC4 dataset. (p. 4)
Training Details
Our approach adopts the OpenFlamingo training paradigm to train the Otter model. The pretrained OpenFlamingo model comprises a LLaMA-7B [33] language encoder and a CLIP ViT-L/14 [24] vision encoder. To prevent overfitting and leverage pretrained knowledge, we freeze both the encoders and only finetune the Perceiver resampler module, cross-attention layers inserted into the language encoder and input/output embeddings of the language encoder. This results in approximately 1.3 billion trainable parameters for the Otter model. (p. 4)
To optimize our model, we employ the AdamW optimizer [18] with a starting learning rate of 10−5 and a batch size of 4. We train Otter for 6 epochs, with the learning rate scheduled using a cosine annealing scheduler. We also use gradient clipping of a threshold of 1.0 to prevent exploding gradients. (p. 4)
Experiment

