Unified Contrastive Learning in Image-Text-Label Space
[multimodal deep-learning unicl contrast-loss omnivl clip align albef coca blip florence flava univlp This is my reading note for Unified Contrastive Learning in Image-Text-Label Space. This paper proposes to combine label in image-text contrast loss. It treats the image or text from the same labels are from the same class and thus is required to have higher similarity; in contrast loss of CLIP, image/text is required to be similar if they are from the same pair.
Introduction
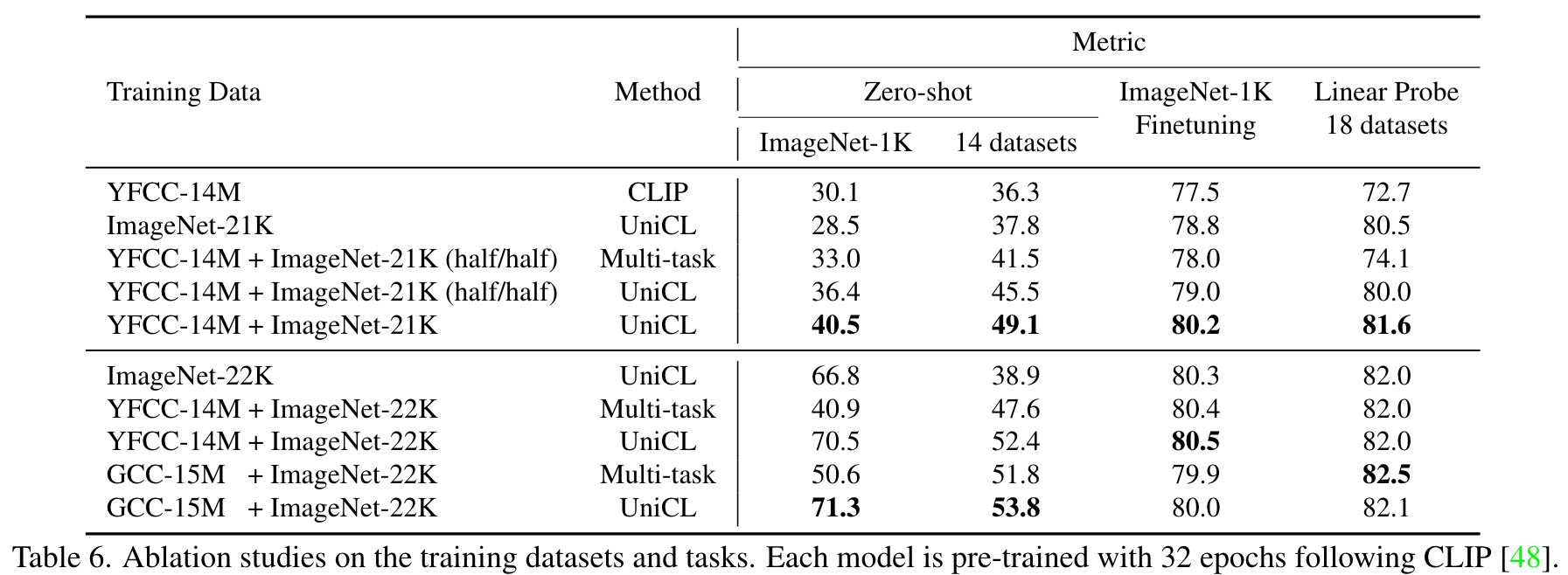
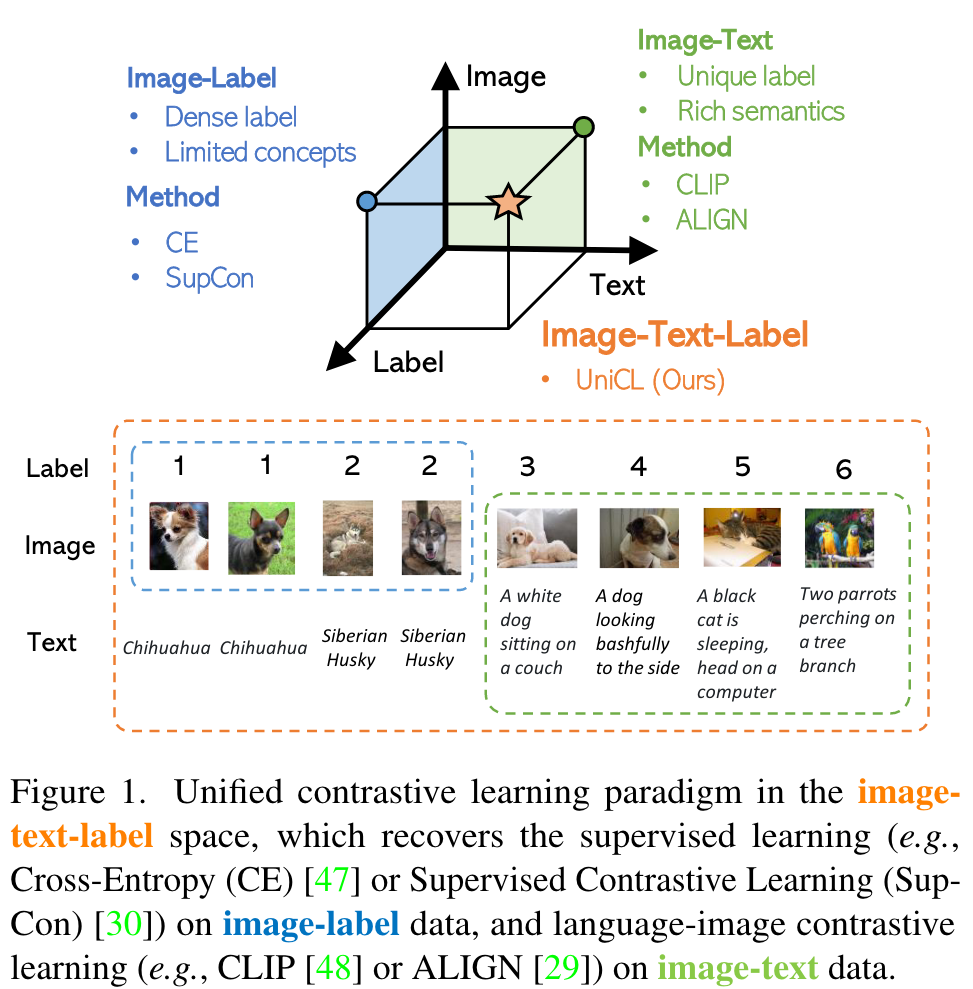
While supervised learning may result in a more discriminative representation, language-image pretraining shows unprecedented zero-shot recognition capability, largely due to the different properties of data sources and learning objectives. In this work, we introduce a new formulation by combining the two data sources into a common image-text-label space. In this space, we propose a new learning paradigm, called Unified Contrastive Learning (UniCL) with a single learning objective to seamlessly prompt the synergy of two data types. (p. 1)
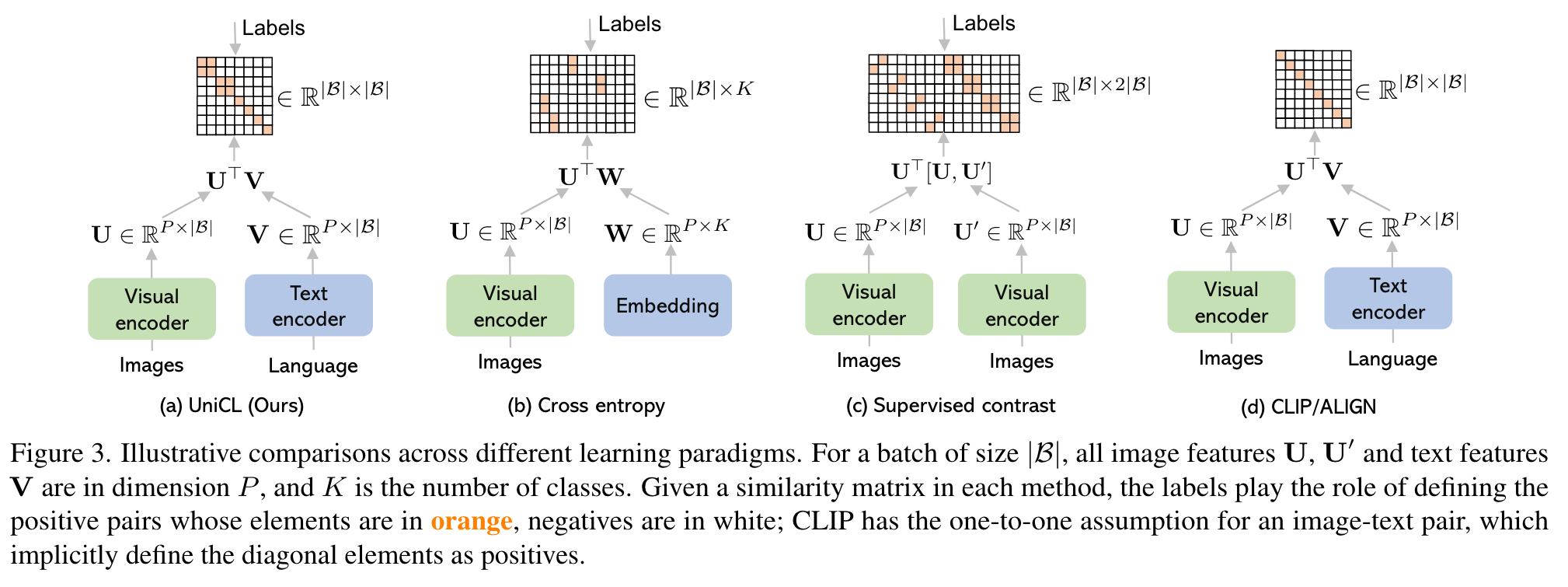
we find in our experiments that they usually lack the strong discriminative ability required by transfer learning. Contrast loss in CLIP and ALIGN implicitly assumes that each image-text pair has a unique label. (p. 2)
Based on this new perspective, we can simply use a visual encoder and a language encoder to encode the images and texts, and align the visual and textual features with the guide of labels (unique labels for image-text pairs and manual labels for image-label data). (p. 2)
It takes images, texts as input and compute the loss with softened targets derived from the labels. With UniCL, we combine image-label and image-text data together to learn discriminative and semantic-rich representations, which are beneficial to a variety of downstream tasks. (p. 2)
Method

Unified Image-Text-Label Contrast
The image-to-text contrastive loss to align matched images in a batch with a given text (p. 3)
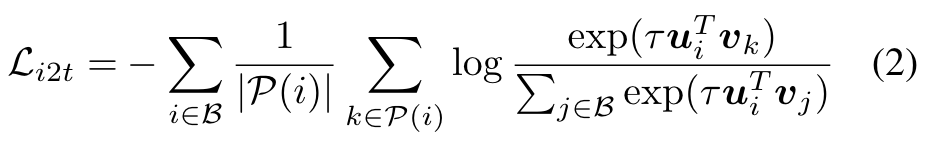
The text-to-image contrastive loss to align matched texts to a given image (p. 3)
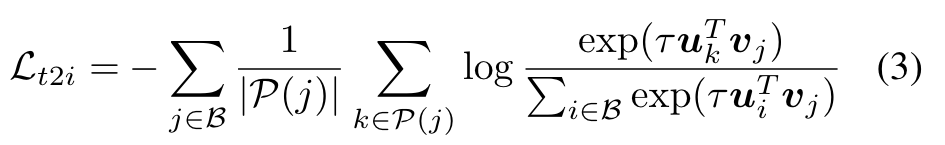
Discussions & Properties
Connections to Cross-Entropy
We note the proposed LBiC in (1) is closely related to the standard cross-entropy loss used in supervised image classification. Specifically, the text-to-image contrastive term in (3) recovers cross-entropy as a special case (p. 3)
Connections to SupCon
One shared property between our UniCL and SupCon is that both methods exploit labelguided contrastive learning: For any query, both methods leverage samples with the same label to contribute to the numerator as positives (p. 4)
Connections to CLIP
For image-texts pairs, there are only one-to-one mappings between an image and its paired text in a batch. In another word, P(i) = {i} and P(j) = {j} for Eq. (2) and Eq. (3), respectively. (p. 4)

Experiments

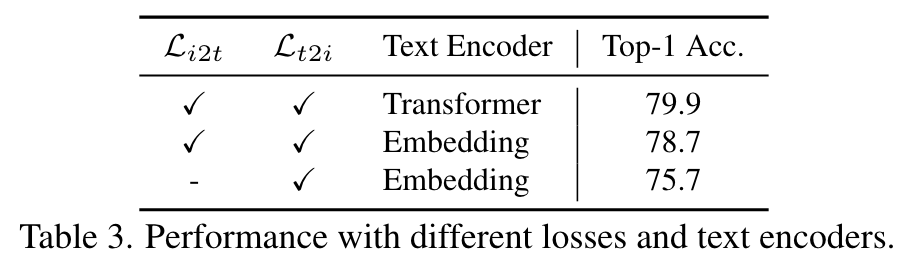
Ablation of training objectives
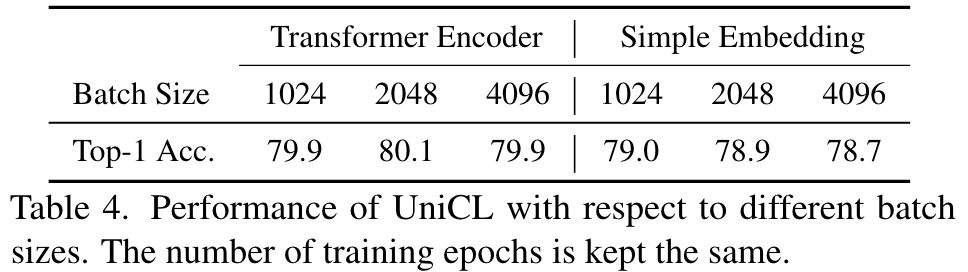
UniCL is robust to the variation of batch size, regardless of which language encoder is employed. (p. 6)
Benefit of image-text to image-label
We use ImageNet-1K as the base dataset, and gradually add different sets of image-text pairs, including GCC-3M, GCC15M and YFCC-14M. When combining with image-text pairs, we use a balanced data sampler to ensure that the model is trained with the same number of image-label and image-text pairs per epoch. (p. 6)
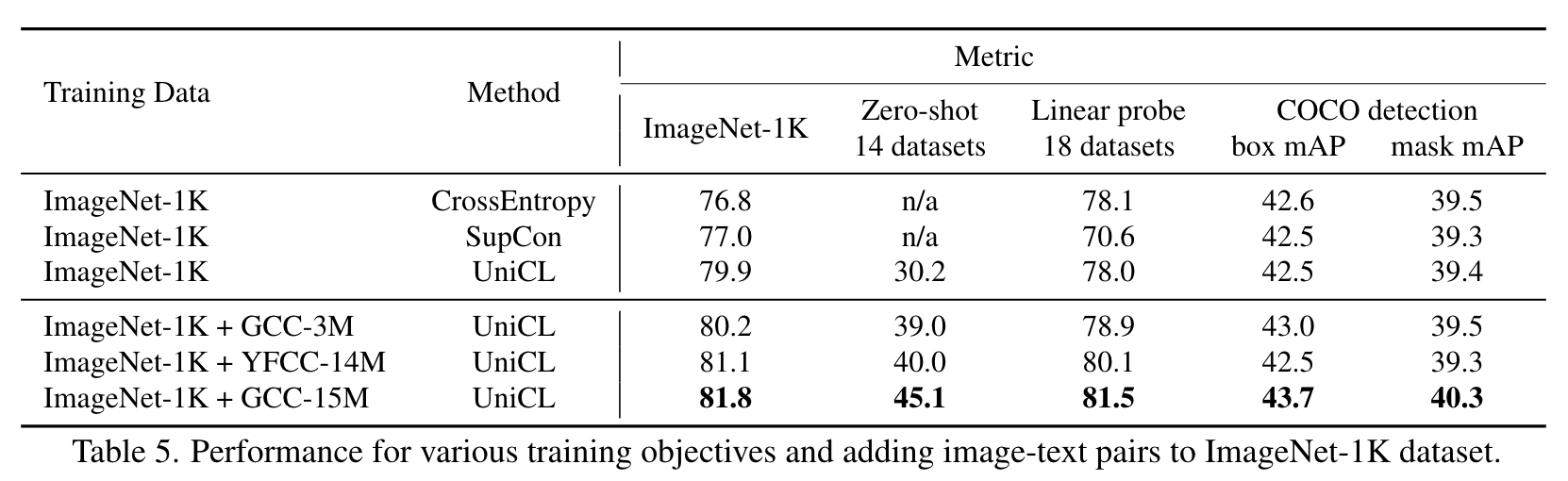
Benefit of image-text pairs

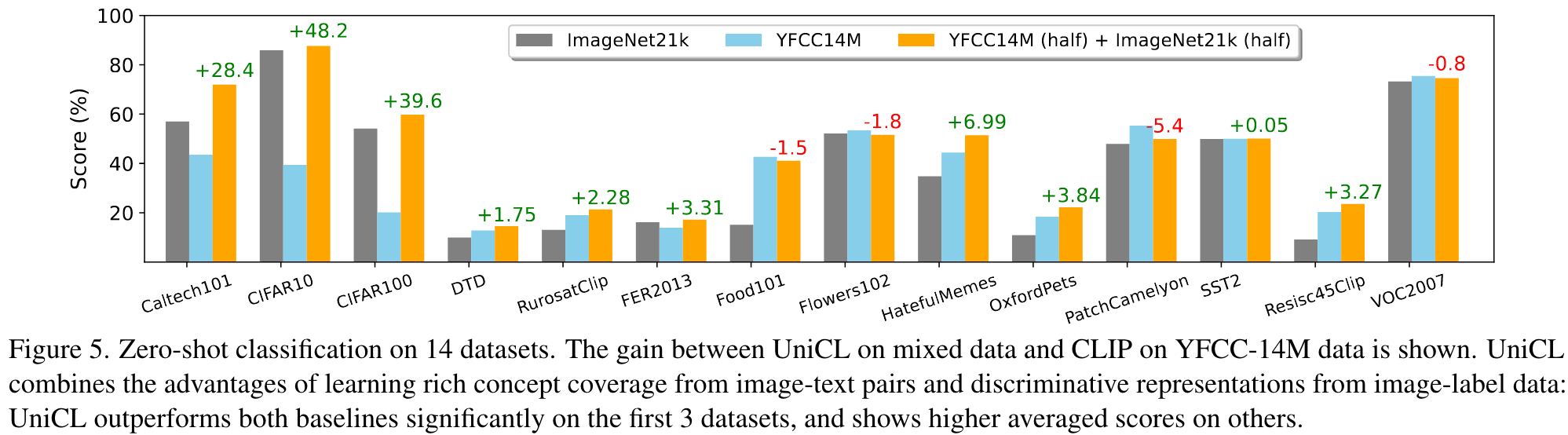
image-text pairs are coarsely aligned, but cover rich visual concepts. Therefore, they are particularly beneficial for tasks requiring broad visual concept understanding, such as zero-shot and linear probe on dozens of datasets. (p. 7)
Benefit of image-label to image-text
We compare against two baselines: (i) CLIP, a languageimage contrastive learning method without label supervision, our UniCL can recover CLIP when merely using image-text pair for the training. (ii) Multi-task learning that performs CE on image-label data, and CLIP on image-text data. (p. 7)