VideoChat Chat-Centric Video Understanding
[video-chat multimodal llm video blip2 deep-learning video-chatgpt chatgpt transformer This is my reading note for VideoChat: Chat-Centric Video Understanding. The papers extends chatGPT to understand the video. To this end.it develops a video backbone based on BLIP2
Introduction
It integrates video foundation models and large language models via a learnable neural interface, excelling in spatiotemporal reasoning, event localization, and causal relationship inference. To instructively tune this system, we propose a video-centric instruction dataset, composed of thousands of videos matched with detailed descriptions and conversations. T (p. 1)
Existing video-centric multimodal dialogue systems 1 [16] transform video understanding into a natural language processing (NLP) question-answering formulation by textualizing video content using open-source vision classification/detection/caption models. Despite demonstrating decent performance in short-term scenarios with clear objects and actions, converting videos into textual descriptions inevitably results in visual information loss and over-simplification of spatiotemporal complexities. Additionally, almost all utilized vision models struggle with spatiotemporal reasoning, event localization, and causal relationship inference within videos. (p. 1)
By a two-stage lightweight training (with only spatiotemporal and video-language alignment modules) on large-scale video-text datasets and self-built video instruction ones, our method excels in spatiotemporal perception & reasoning, and causal inference, marking the first attempt to create a fully learnable and efficient video understanding system that facilitates effective communication. (p. 2)
Related Work
Video Foundation Models
Early methods [38, 60] employed pretrained visual and language encoders to derive offline video and text features; Additionally, prevalent techniques often encompass two or three pretraining tasks, such as masked language modeling [22], video-text matching [43], video-text contrastive learning [49, 46], masked video modeling [41, 44, 46] and video-text masked modeling [12]. Within the realm of video multimodal tasks, VIOLET [12] integrates masked language and masked video modeling, while All-in-one [43] suggests a unified video-language pretraining methodology using a shared backbone, and LAVENDER [22] consolidates the tasks through masked language modeling. Although these approaches yield impressive results in multimodal benchmarks, their training relies on limited video-text data, which leads to difficulties in video-only tasks such as action recognition. (p. 2)
Large Language Models
InstructGPT models [32] are finetuned using datasets containing prompts with corresponding human-annotated desired behavior. This results in better alignment with users, improved output quality compared to GPT-3, increased truthfulness, and reduced risks. Instruction-tuned models also present remarkable generalization capacity for zero-shot tasks. Therefore, instruction-tuning [28, 8] is crucial in leveraging LLMs’ potential. (p. 2)
LLMs for Multimodal Understanding
Visual instruction tuning introduces an innovative technique for refining large language models on visual instruction tasks, enabling pretrained BLIP and Vicuna to nearly match GPT-4 level conversation performance for image-based tasks [25]. (p. 3)
Proposed Method
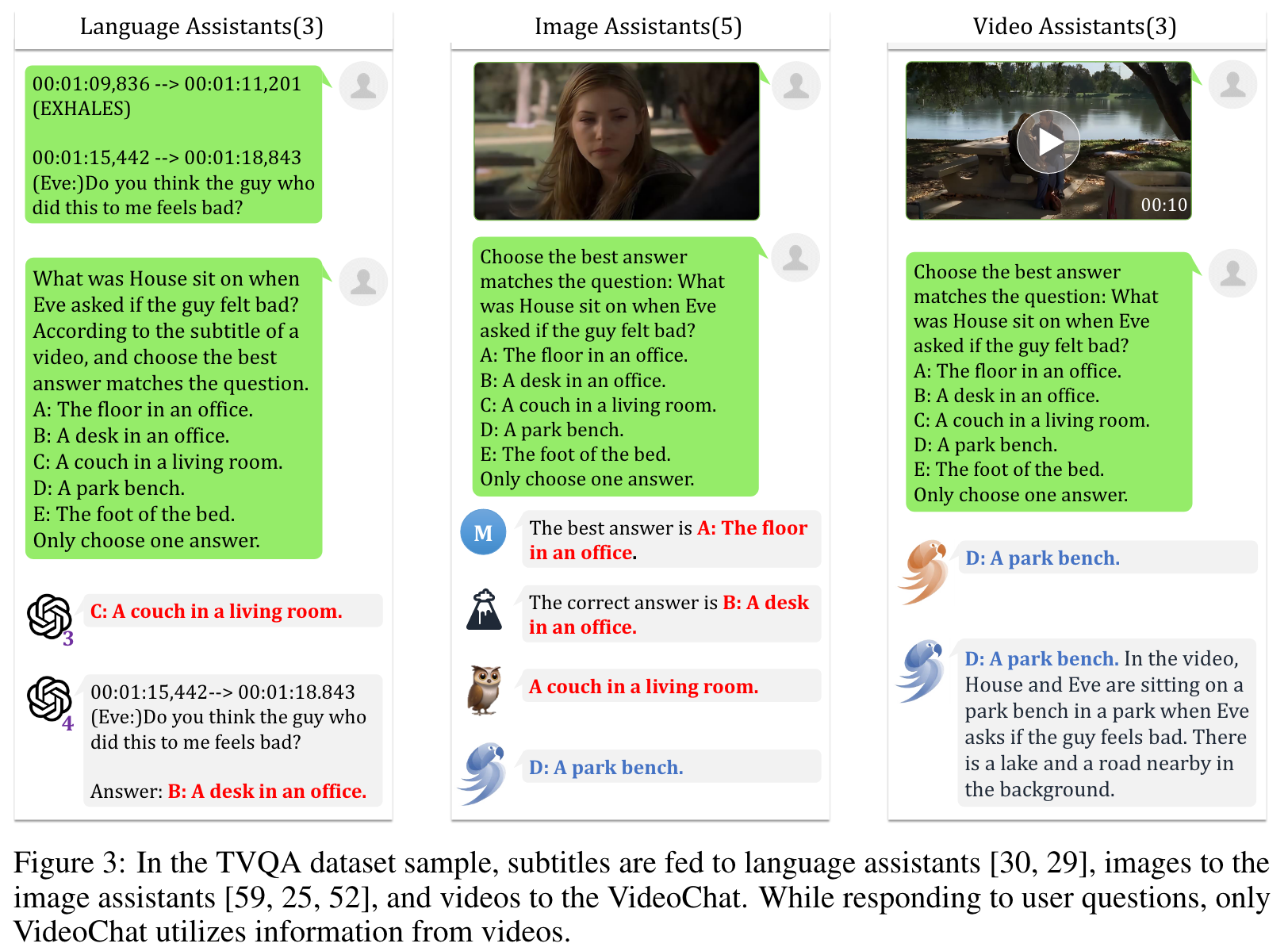
VideoChat unifies video-related tasks into the formulation of multiple-round video question answering, in which tasks are defined by words in a live inference and no or a few instances are given for learning. In this formulation, we treat an LLM as a universal video task decoder, turning video-related descriptions or embeddings into human-understandable text. (p. 3)
In technical terms, an ideal end-to-end chat-centric video understanding system should utilize a video/vision base model (an encoder) to convert visual sequences into latent features for LLM, guaranteeing the system’s overall differentiability. Prior to this, we verify the efficacy of LLM as a universal video task interpreter through our proposed VideoChat-Text (Section 3.1). This method transforms videos into textual streams for subsequent discrimination/reasoning tasks using LLMs by incorporating various open-source vision models. While VideoChat-Text can tackle typical spatiotemporal tasks such as spatial and temporal perception, it falls short in comprehending intricate temporal reasoning and causal inference. Therefore, we introduce VideoChat-Embed (Section 3.2), a multimodal system that combines both video and language foundation models. Finetuned with video instruction data, it significantly enhances performance in higher-order temporal assignments. We will describe these two approaches in the following sections. (p. 3)
VideoChat-Text : VideoChat by Textualizing Videos in Stream
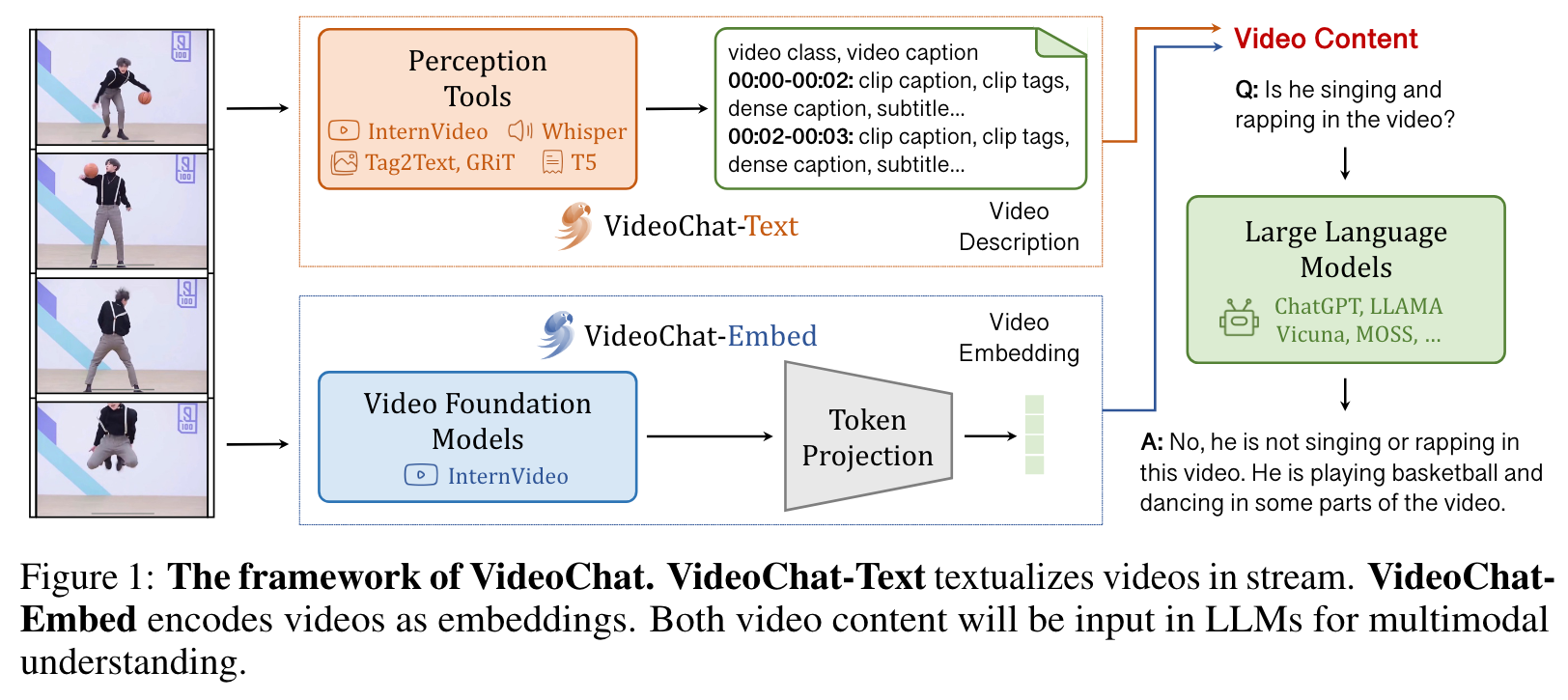
We employ several vision models to convert visual data from videos into textual format. Subsequently, we create purpose-built prompts to temporally structure the predicted text. Ultimately, we rely on a pretrained LLM to address user-specified tasks by responding to questions based on video text descriptions. (p. 4)
In particular, for a given video, we use ffmpeg to extract key frames from the video at a low FPS, resulting in T video frames and associated audio. By feeding the extracted frames and audio into various models, we acquire action labels, frame summaries, video tags, comprehensive descriptions, object positional coordinates, video narratives, timestamps, and other segment-related details. We then consolidate related content in the captions considering the timing and generate a timestamped video text description. (p. 4)
However, using text as the communication medium restricts the representation capabilities of the perception models, as it limits their decoders (p. 4)


VideoChat-Embed : VideoChat by Encoding Videos as Embeddings
VideoChat-Embed is an end-to-end model designed to handle video-based dialogue. It employs an architecture (Figure 2a) that combines both video and language foundation models with an addition learnable Video-Language Token Interface (VLTF). To achieve better cross-modality optimization, the model incorporates language-friendly video foundation models, inspired by [53, 49, 46, 21]. Considering the video redundancy [41], we introduce the VLTF, using cross-attention to compress the video tokens (p. 4)
Architecture
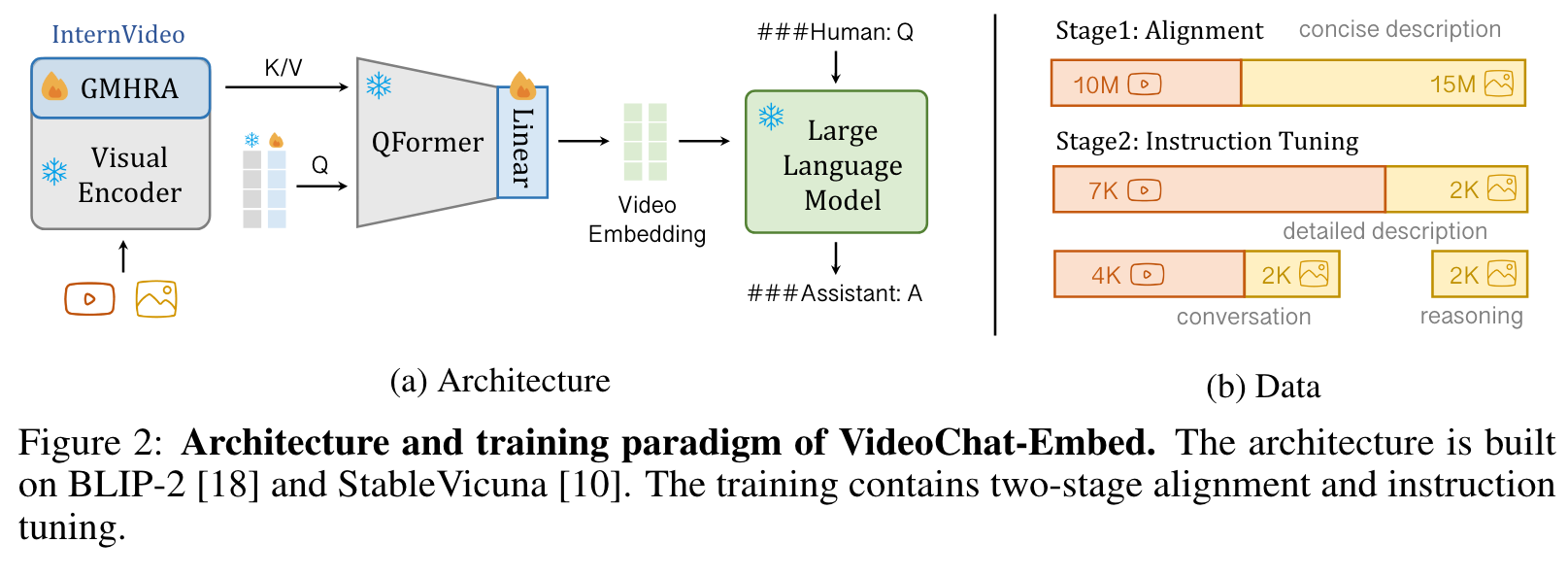
In this paper, we instantiate the VideoChat-Embed based on BLIP-2 [18] and StableVicuna [10]. Concretely, we incorporate the pretrained ViT-G [39] with Global Multi-Head Relation Aggregator (GMHRA), a temporal modeling module used in InternVideo [46] and UniFormerV2 [20]. For the token interface, we employ the pretrained QFormer with extra linear projection, supplemented by additional query tokens to account for video context modeling. This allows us to obtain compact LLM-compatible video embeddings for future dialogues. (p. 4)
When training, we freeze most of the parameters except the newly incorporated GMHRA, queries and linear projection. In Stage1, we align the video encoder with LLM via large-scale video-text fine-tuning. In Stage2, we tune the system with two types of video instruction data: in-depth video descriptions and video question-answer pairs. (p. 5)
Instruction Data
The corresponding detailed descriptions and question-answer generations are produced by ChatGPT based on video text (aided by VideoChat-Text) with several prompts concerning spatiotemporal features. (p. 6)
Detailed Video Descriptions. We condense the provided video description into a video narrative employing GPT-4, as shown in Table 5. This highlights the temporal aspects of the video by illustrating its progression over time (p. 6)

Video Conversations. With the video description, we generate multi-round dialogues with three types of prompts concerning descriptive, temporal, and causal content for videos with ChatGPT. The descriptive part mostly inherits key points from LLaVA [25]. For the temporal and causal parts, we propose prompts (Table 6) focus on temporal perception/reasoning and explanation/uncovering intentions/causes, respectively. (p. 6)

Experiment

Limitations
1) Both VideoChat-Text and VideoChat-Embed struggle with managing long-term videos (≥ 1min). (p. 9) 2) Our system’s capacities for temporal and causal reasoning remain rudimentary. These limitations stem from the current scale of our instruction data and its construction approaches, as well as the overall system scale and the models employed. 3) Addressing performance disparities in time-sensitive and performance-critical applications, such as egocentric task instruction prediction and intelligent monitoring, is an ongoing challenge. (p. 9)