Vision-Language Intelligence Tasks, Representation Learning, and Large Models
[masked-language-modeling multimodal contrast-loss masked-image-modeling deep-learning review image-text-matching pretrain foundation-model This is my reading note for Vision-Language Intelligence: Tasks, Representation Learning, and Large Models. It is yet another review paper for pre-trained vision-language model. Check my reading note for another review paper in Large-scale Multi-Modal Pre-trained Models A Comprehensive Survey
Introduction
A good visual representation should have three attributes as summarized in (Li et al., 2021b), which are object-level, language-aligned, and semantic-rich. Object-level means the granularity of vision and language features should be as fine as in object and word-level, respectively. Language-aligned emphasizes that the vision feature aligned with language can help in vision tasks. Semantic-rich means the representation should be learned from large-scale data without domain restriction. (p. 2)
The first stage is gloabl vector representation and simple fusion. The second stage is grid feature representation and cross-modal attention. The third stage is object-centric feature representation and bottom-up top-down attention (Anderson et al., 2018b). (p. 2)
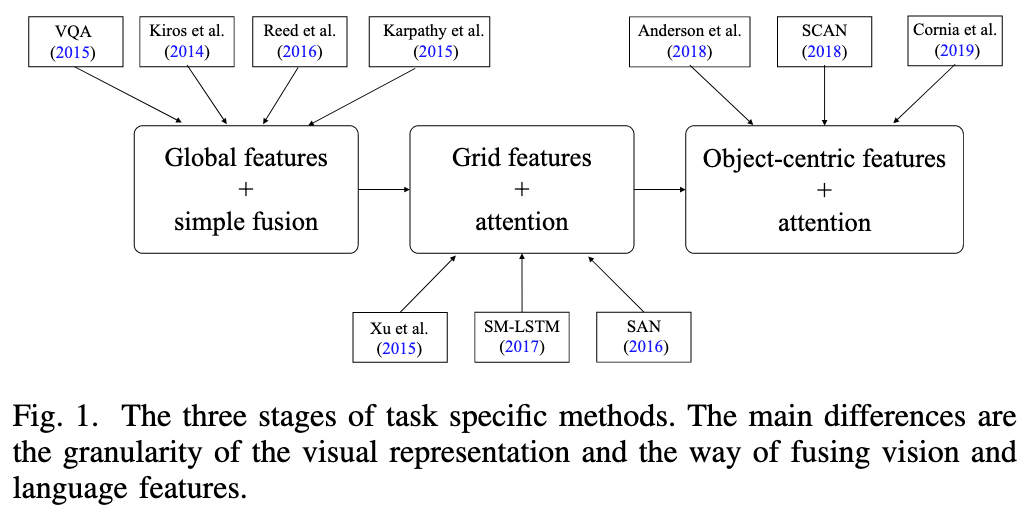
Image Captioning
Early image captioning methods before deep learning (Kulkarni et al., 2013; Farhadi et al., 2010) are mainly rule-based. They first recognize objects and their relations and then generate captions based on predefined rules. (p. 3)
Following the encoderdecoder structure in Seq2Seq, Xu et al. (2015) proposed to replace the text encoder with an image encoder using GoogleNet (Szegedy et al., 2014) and achieved state-of-theart performance at that time. (p. 3)
Xu et al. (2015) proposed the first method leveraging attention over gird features. Assume the output feature map of a CNN feature extractor has a shape (H, W, C) where H, W are the height and width of the feature map and C is the feature dimension. The feature map can be flattened along spatial dimensions to H × W grid features with dimension C. For each cell of the LSTM decoder, the hidden state attends to grid features to decide which grids to focus on (p. 4)
Compared to convolution, the attention mechanism has the following benefits. It allows the model to focus on certain parts of an image by giving high attention weights to important grid features. (p. 4)
BUTD extracts region features with a Faster-RCNN (Ren et al., 2016) model pre-trained on Visual Genome (Krishna et al., 2017a) (p. 4)
VQA
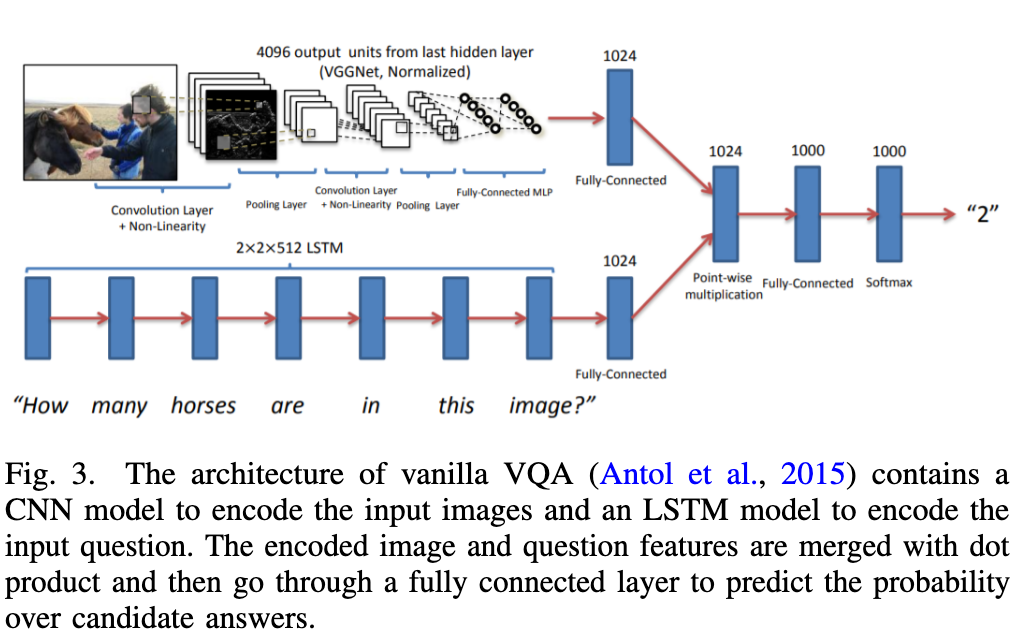
The vanilla VQA (Antol et al., 2015) is a combination of an LSTM (Hochreiter and Schmidhuber, 1997b) question encoder and a VGG (Simonyan and Zisserman, 2015b) image encoder. The output image embedding and question embedding are simply fused by point-wise multiplication. Then the fused vector goes through a linear layer followed by a softmax layer to output the probability of choosing each candidate answer. (p. 4)
(Yang et al., 2016) proposed Stacked Attention Network (SAN) to stack multiple question-guided attention layers. In each layer, the semantic representation of the question is used as a query to attend to image grids. SAN is the first work that verifies the effectiveness of attention in VQA. (p. 5)
Ren et al. (2015) treat an image feature as a language token. They concatenates the image embeddings with language tokens as the input to LSTM. (p. 5)
Image Text Matching
Early methods (Frome et al., 2013; Socher et al., 2014; Kiros et al., 2014) mainly adopted global feature to encode image and text. Kiros et al. (2014) proposed to learn crossview representation with a hinge-based triplet ranking loss (p. 5)
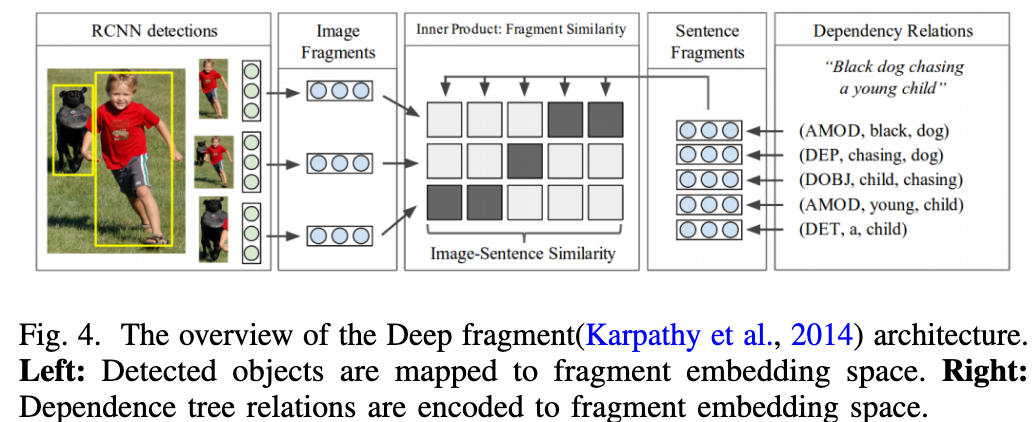
Instead of directly representing the whole image and sentence, they map each image fragment and sentence fragment into the cross-modality embedding space. (p. 5)
Huang et al. (2016) proposed to introduce attention into image-text matching (ITM). They developed a context-modulated attention scheme to attend to instance pairs appearing in both image and text. Nam et al. (2017) proposed a dual attention framework that attends to specific regions in images and words in the text through multiple steps and gathers essential information from both modalities. (p. 5)
Lee et al. (2018) proposed a cross-attention algorithm called SCAN to calculate the similarity between image and sentence. To enable cross attention, they represent an image as a set of regions and a sentence as a set of words. The core idea of cross attention is to not only use the sentence as a query to attend to image regions but also use the image as a query to attend to words. (p. 5)
VISION LANGUAGE JOINT REPRESENTATION
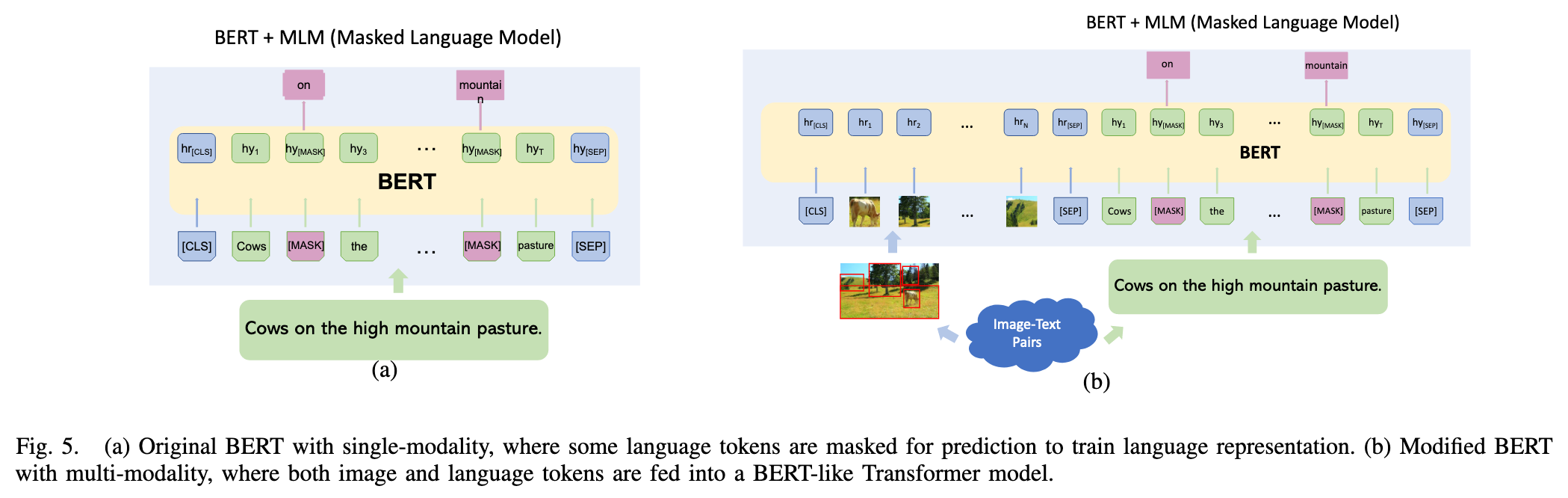
As shown in Figure 5(a), training is conducted by replacing some text tokens with a special [MASK] token and predicting each [MASK] using its context information. (p. 6)
Similar to language training, image is tokenized and embedded along with language tokens with certain techniques, which will be elaborated on later. Usually, the tokenized visual features and textual features together are fed into a Transformer encoder with masked language training to learn a joint representation. (p. 6)
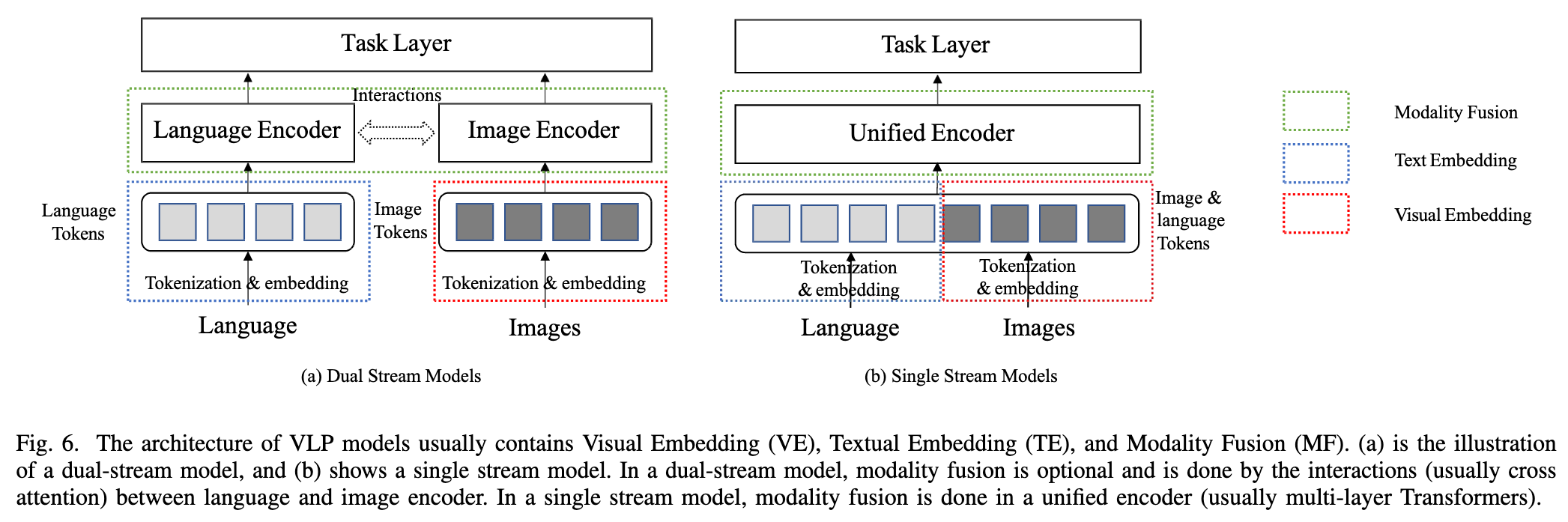
In this section, we will go through the main components of VLP models. As shown in Figure 6, there are primarily three components in VLP models, namely the visual embedding (VE), textual embedding (TE), and modality fusion (MF) modules (p. 6)
Pre-training on a massive dataset is crucial for improving the performance on downstream tasks with smaller datasets, as the learned representation can be transferred in downstream tasks. VLP models have been proven very effective to empower downstream tasks. (p. 6)
Modality Embedding
Ablation studies conducted by Bugliarello et al. (2021) demonstrate that training datasets and hyperparameters are responsible for most performance improvements across many different VLP models and also emphasize the importance of modality embeddings. (p. 7)
Text Tokenization and Embedding
Word2Vec is computationally efficient to scale to large corpus and produces high-quality embeddings. However, although its vocabulary size is as large as about one million, this method suffers from out-of-vocabulary issues due to rare or unseen words, making it difficult to learn word sub-units such as ’est’. (p. 7)
To resolve this problem, Sennrich et. al (Sennrich et al., 2015) proposed a subword tokenization approach, which segments words into smaller units with byte pair encoding (BPE) (Gage, 1994). Subword tokenization is widely used in many language models including BERT. (p. 7)
Most VLP models adopt text embeddings from pre-trained BERT (Devlin et al., 2018). As BERT is trained with masked token learning using Transformer encoders, it has a strong bidirectional representation ability. (p. 7)
Visual Tokenization and Embedding
1) Grid features are directly extracted from equally sized image grids with a convolution feature extractor as aforementioned. (p. 8) 3) Patch features are usually extracted by a linear projection on evenly divided image patches. The main difference between patch and grid features is that grid features are extracted from the feature map of a convolutional model while patch features directly utilize a linear projection. (p. 8)
Training
Masked Vision Modeling
MVM is more challenging than MLM since the information density of image is lower than that of language. When reconstructing a missing word, sophisticated language understanding is required. On the contrary, a missing image patch can be recovered from neighboring patches without crossmodality understanding (He et al., 2021). To overcome this gap, most works mask detected object regions that have relatively high information density. Other works such as SOHO (Huang et al., 2021) use a visual dictionary (VD) to represent more comprehensive and compact semantics in the visual domain so that they can apply MVM in the same way as MLM. (p. 9)
Masked Visual Modeling with Visual Dictionary
Secondly, for MVMVD, neighboring image grids tend to map to the same VD token as they are highly co-related. When performing reconstruction, the model may directly copy the surrounding tokens. Therefore, all visual embedding vectors mapped to the same VD token are masked together in SOHO. (p. 9)
Landscape of General Pre-training Studies
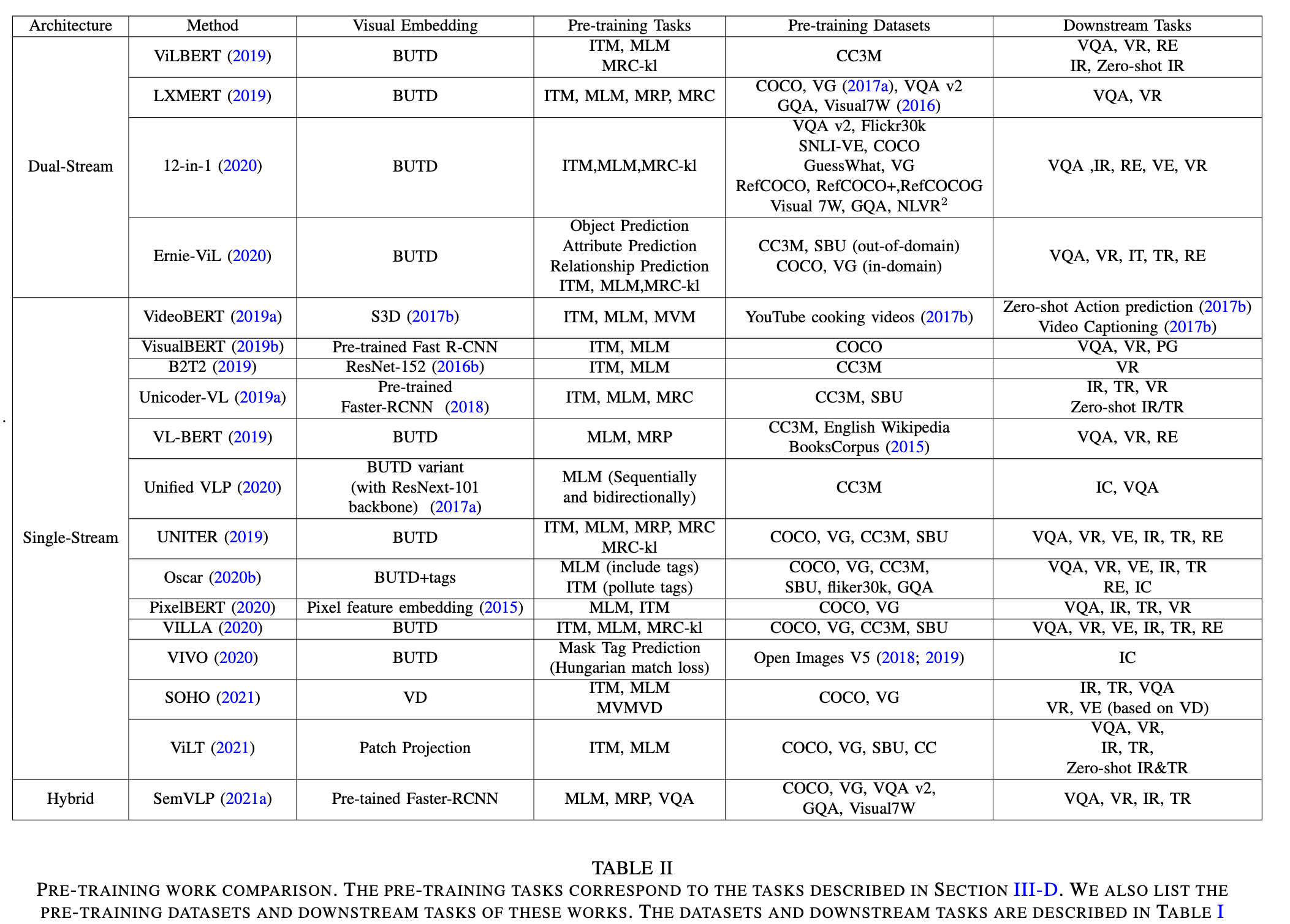
Single Stream Models
The primary idea is to feed visual and textual tokens into a single-stream model built upon BERT (Devlin et al., 2018). Textual tokens are extracted by converting video speech into text with an automatic speech recognition approach, and visual tokens are acquired by extracting features from video clips using a convolutional backbone. (p. 10)
Dual Stream Models
ViLBERT (Lu et al., 2019) and LXMBERT (Tan and Bansal, 2019) are pioneering works to extend BERT to dual-stream VLP models. They are pre-trained on the Conceptual Captions dataset (Sharma et al., 2018) and leverage a pre-trained Faster R-CNN model (Ren et al., 2017) to detect regions as visual tokens. (p. 10)
Early Attempts to Bridge Modality Gap
To enable both generation and understanding tasks, Zhou et al. (2020) proposed a unified vision-language pre-training approach. It introduces two mask schemes namely bidirectional attention mask and sequence-to-sequence mask to empower understanding and generation tasks, respectively. (p. 11)
VILLA (Gan et al., 2020) introduced adversarial training at the embedding level of visual and textual tokens based on the design of UNITER (Chen et al., 2019). It performs adversarial training by adding perturbations in the embedding space as regularization and yields decent performance improvement. (p. 11)
Improve Aligned Representation
As VLP models are limited by inadequate well-aligned (image, caption) pairs, VIVO (Hu et al., 2020) proposed to scale up pre-training using a large amount of (image, tag) pairs. VIVO adopts a Hungarian matching loss to perform masked tag prediction, which enables visual vocabulary learning and improves the model generalization ability to describe novel objects in downstream tasks. (p. 12)
SCALE UP MODELS AND DATA
Visual Understanding
CLIP learns to recognize paired image and text. Given a batch of N (image-text) pairs, the goal is to predict which of the N × N possible pairs are matched pairs (positive samples) and which are unmatched pairs (negative samples). After pre-training, CLIP can perform zero-shot image classification by using phrases such as ”a photo of” plus a category name as prompts to tell the model which categories an input image is the most similar to. (p. 12)
ALIGN outperforms CLIP on many zero-shot visual tasks, which proves that a larger dataset leads to better performance. (p. 12)
FUTURE TRENDS
VL+Knowledge
Many VL tasks require common sense and factual information beyond training datasets. However, most VLP models do not have a mechanism to consume extra knowledge. (p. 13)
ERNIE (Sun et al., 2019b) proposed a multi-stage knowledgebased masking strategy. Instead of directly adding knowledge embedding, it masks language in three levels, which are basiclevel, phrase-level, and entity-level masking. For entity-level masking, the model masks a whole entity rather than a sub-word. Such entities include persons, locations, organizations, products, etc. (p. 13) %% end annotations %%
%% Import Date: 2023-10-10T23:49:15.101-07:00 %%