Word-As-Image for Semantic Typography
[dream-booth siggraph vector-graph live clip-draw post-script diffusion score-distillation-sampling deep-learning text2image true-type vector-ascent style-clip-draw diffvg svg vector-fusion sds sktech-rnn This is my reading note for Word-As-Image for Semantic Typography. This paper utilized the differential rendering for vector graph to train a diffusion model to generate vector graph for a given text. Check my note for related paper in # VectorFusion Text-to-SVG by Abstracting Pixel-Based Diffusion Models

Introduction
We rely on the remarkable ability of recent large pretrained language-vision models to distill textual concepts visually. We target simple, concise, black-and-white designs that convey the semantics clearly. Our method optimizes the outline of each letter to convey the desired concept, guided by a pretrained Stable Diffusion model. We incorporate additional loss terms to ensure the legibility of the text and the preservation of the style of the font. (p. 1)
Existing methods in the field of text stylization often rely on raster textures [Yang et al. 2018], place a manually created style on top of the strokes segmentation [Berio et al. 2022], or deform the text into a pre-defined target shape [Zou et al. 2016] (see Figure 3). Only a few works [Tendulkar et al. 2019; Zhang et al. 2017] deal with semantic typography, and they often operate in the raster domain and use existing icons for replacement (see Figure 3E). (p. 1)
Given an input word, our method is applied separately for each letter, allowing the user to later choose the most likeable combination for replacement. We represent each letter as a closed vectorized shape, and optimize its parameters to reflect the meaning of the word, while still preserving its original style and design.
We rely on the prior of a pretrained Stable Diffusion model [Rombach et al. 2021] to connect between text and images, and utilize the Score Distillation Sampling approach [Poole et al. 2022] (see Section 3) to encourage the appearance of the letter to reflect the provided textual concept. Since the Stable Diffusion model is trained on raster images, we use a differentiable rasterizer [Li et al. 2020] that allows to backpropagate gradients from a raster-based loss to the shape’s parameters.
To preserve the shape of the original letter and ensure legibility of the word, we utilize two additional loss functions. The first loss regulates the shape modification by constraining the deformation to be as-conformal-as-possible over a triangulation of the letter’s shape. The second loss preserves the local tone and structure of the letter by comparing the low-pass filter of the resulting rasterized letter to the original one. (p. 2)
Related Work
Commonly, a latent feature space of font’s outlines is constructed, represented as outline samples [Balashova et al. 2019; Campbell and Kautz 2014] or parametric curve segments. Tendulkar et al. [2019] replace letters in a given word with clip-art icons describing a given theme (see Figure 3E). To choose the most suitable icon for replacement, an autoencoder is used to measure the distance between the letter and icons from the desired class. Similarly, Zhang et. al [2017] replace stroke-like parts of one or more letters with instances of clip art to generate ornamental stylizations. An example is shown in Figure 3C. (p. 2)

Background
Fonts and Vector Representation
Modern typeface formats such as TrueType [Penney 1996] and PostScript [Inc. 1990] represent glyphs using a vectorized graphic representation of their outlines. Specifically, the outline contours are typically represented by a collection of lines and Bézier or B-Spline curves. (p. 3)
Score Distillation
During training, the gradients are back-propagated to the NeRF parameters to gradually change the 3D object to fit the text prompt. Note that the gradients of the UNet are skipped, and the gradients to modify the Nerf’s parameters are derived directly from the LDM loss. (p. 3)
VectorFusion
Recently, VectorFusion [Jain et al. 2022] utilized the SDS loss for the task of text-to-SVG generation. The proposed generation pipeline involves two stages. Given a text prompt, first, an image is generated using Stable Diffusion (with an added suffix to the prompt), and is then vectorized automatically using LIVE [Ma et al. 2022]. This defines an initial set of parameters to be optimized in the second stage using the SDS loss. At each iteration, a differentiable rasterizer [Li et al. 2020] is used to produce a 600 × 600 image, which is then augmented as suggested in CLIPDraw [Frans et al. 2021] to get a 512 × 512 image 𝑥𝑎𝑢𝑔. Then 𝑥𝑎𝑢𝑔 is fed into the pretrained encoder E of Stable Diffusion to produce the corresponding latent code 𝑧 = E (𝑥𝑎𝑢𝑔). The SDS loss is then applied in this latent space (p. 4)
Check my note for related paper in # VectorFusion Text-to-SVG by Abstracting Pixel-Based Diffusion Models
Proposed Method
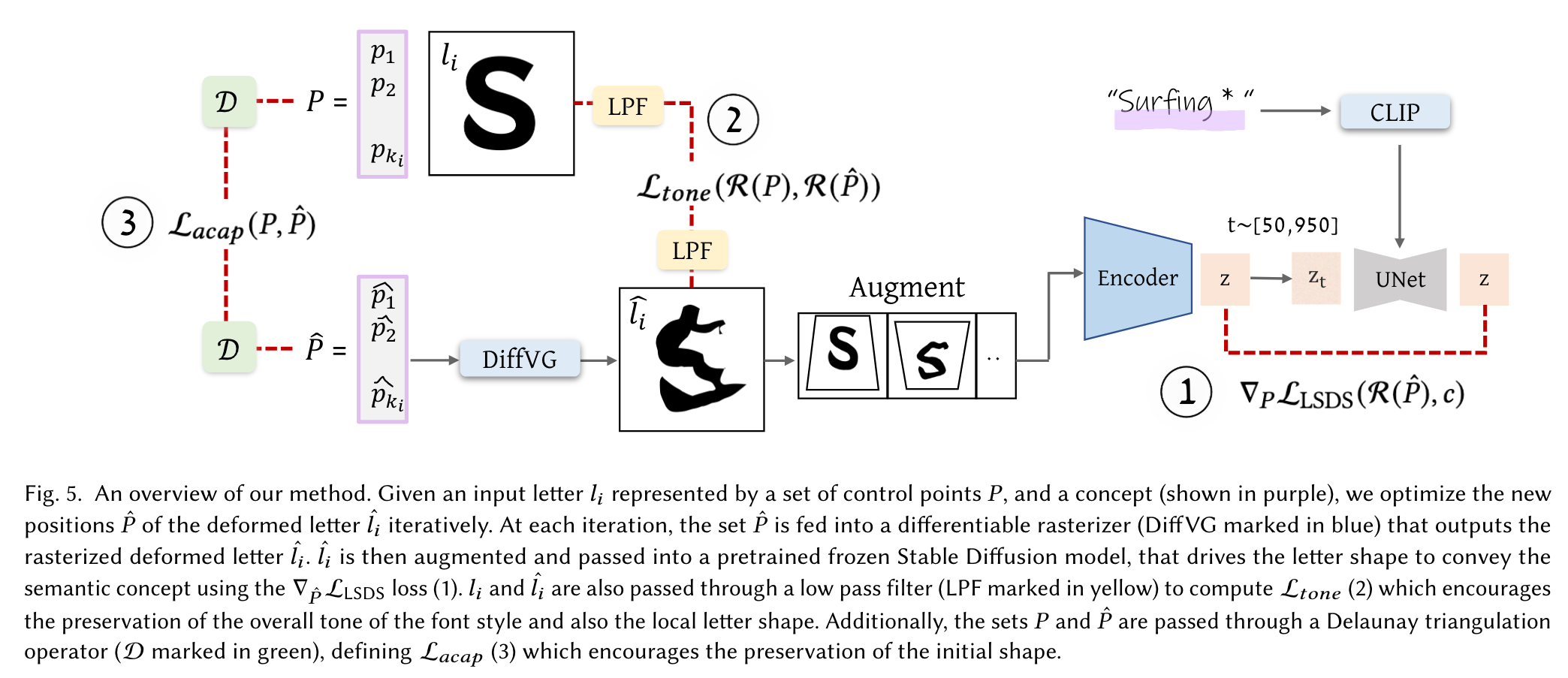
Given a word 𝑊 represented as a string with 𝑛 letters {𝑙1, …𝑙𝑛}, our method is applied to every letter𝑙𝑖 separately to produce a semantic visual depiction of the letter. The user can then choose which letters to replace and which to keep in their original form. (p. 4)
Letter Representation
We use the FreeType font library [FreeType 2009] to extract the outline of each letter. We then translate each outline into a set of cubic Bézier curves, to have a consistent representation across different fonts and letters, and to facilitate the use of diffvg [Li et al. 2020] for differentiable rasterization. (p. 4)
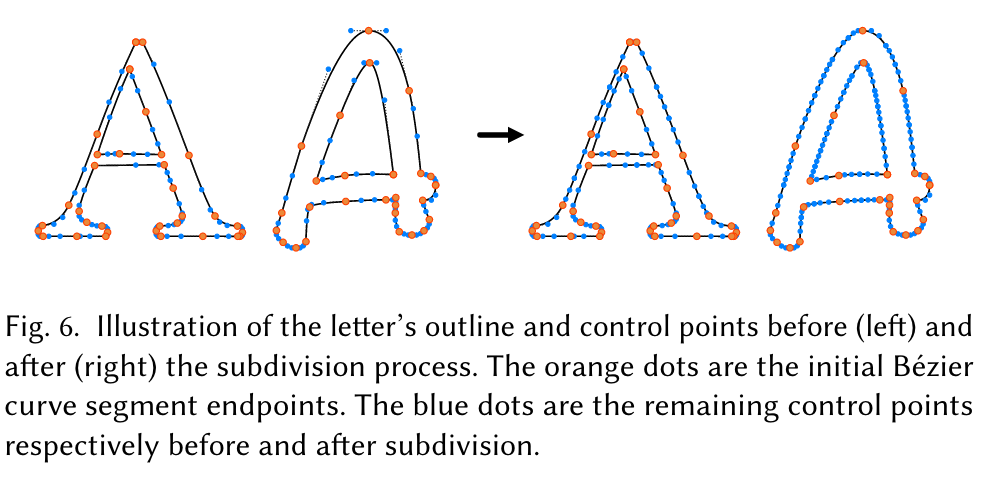
We have found that the initial number of control points affects the final appearance significantly: as the number of control points increases, there is more freedom for visual changes to occur. Therefore, we additionally apply a subdivision procedure to letters containing a small number of control points (p. 4)
Optimization
To preserve the shape of each individual letter and ensure the legibility of the word as a whole, we use two additional loss functions to guide the optimization process. The first loss limits the overall shape change by defining as-conformal-as-possible constraint on the shape deformation. The second loss preserves the overall shape and style of the font by constraining the tone (i.e. amount of dark vs. light areas in local parts of the shape) of the modified letter not to diverge too much from the original letter (see Section 4.3). (p. 5)
Loss Functions
As-Conformal-As-Possible Deformation Loss
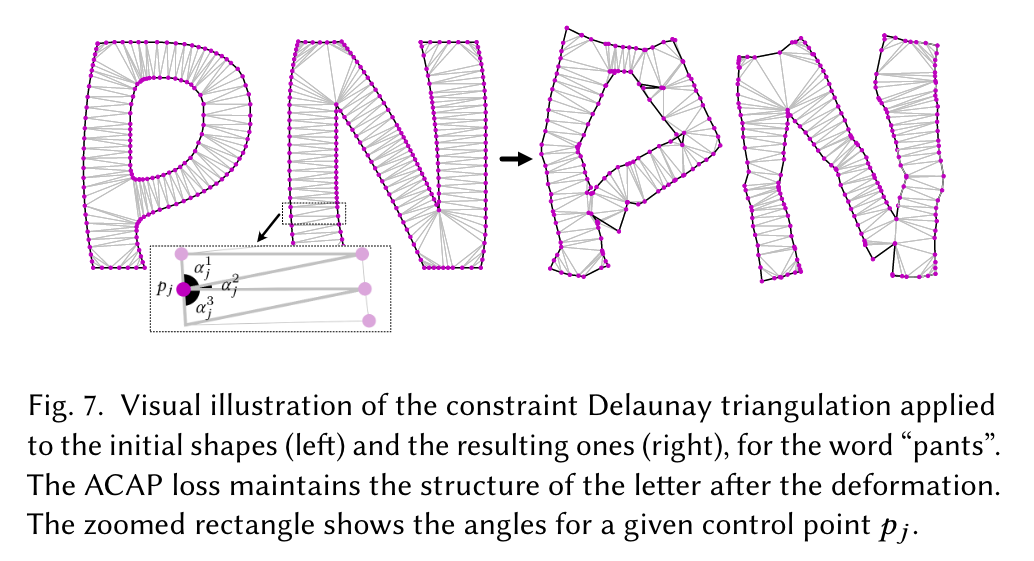
The ACAP loss encourages the induced angles of the optimized shape ˆ 𝑃 not to deviate much from the angles of the original shape 𝑃, and is defined as the L2 distance between the corresponding angles: (p. 5)
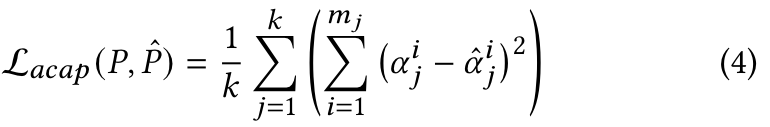
Tone Preservation Loss.

This term constrains the tone (amount of black vs. white in all regions of the shape) of the adjusted letter not to deviate too much from tone of the original font’s letter. Towards this end, we apply a low pass filter (LPF) to the rasterized letter (before and after deformation) and compute the L2 distance between the resulting blurred letters: (p. 5)
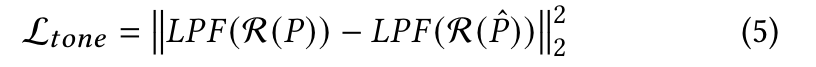
Weighting
Therefore, we adjust the weight of L𝑡𝑜𝑛𝑒 to kick-in only after some semantic deformation has occurred. We define 𝛽𝑡 as follows: (p. 6)
Experiment
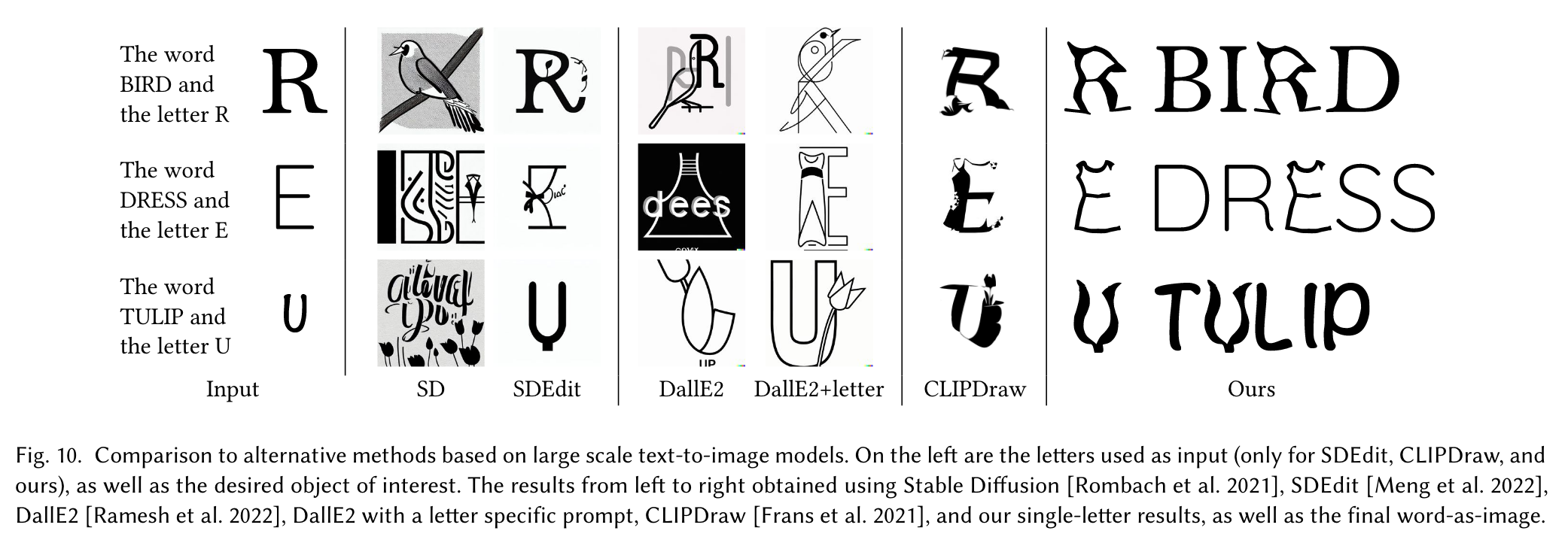
Before we feed the rasterized 600𝑥600 letter image into the Stable Diffusion model, we apply random augmentations as proposed in CLIPDraw [Frans et al. 2021]. Specifically, perspective transform with a distortion scale of 0.5, with probability 0.7, and a random 512𝑥512 crop. We add the suffix “a [word]. minimal flat 2d vector. lineal color. trending on artstation.” to the target word 𝑊 , before feeding it into the text encoder of a pretrained CLIP model. (p. 12)

Ablation
When less control points are used (𝑃𝑜 is the original number of control points), we may get insufficient variations, such as for the gorilla. However, this can also result in more abstract depictions, such as the ballerina. A (p. 7)
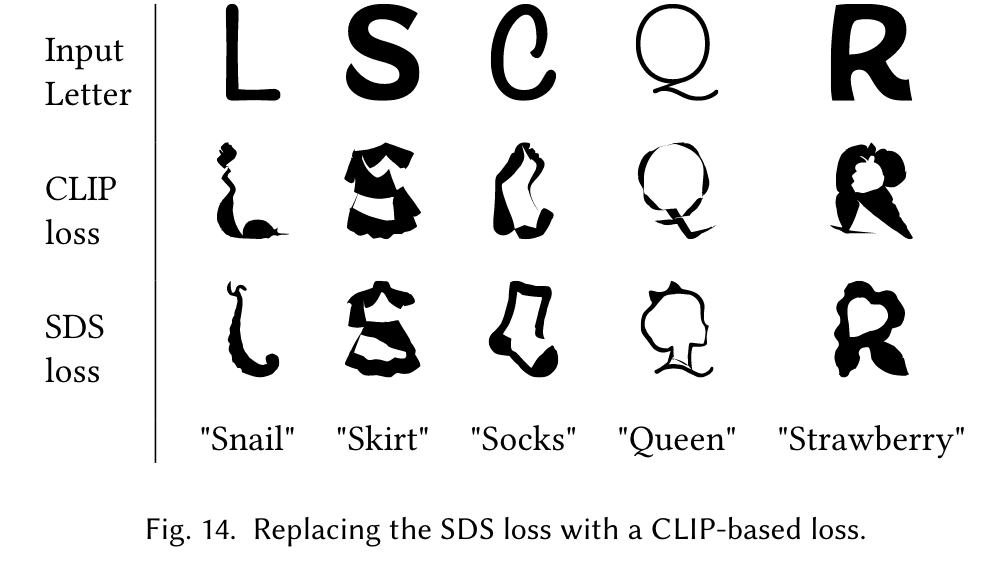
Although the results obtained with CLIP often depict the desired visual concept, we find that using Stable Diffusion leads to smoother illustrations, that capture a wider range of semantic concepts. (p. 7)