Florence A New Foundation Model for Computer Vision
[multimodal deep-learning florence unicl contrast-loss omnivl clip align albef coca blip florence flava univlp swin-transformer roberta video meter This is my reading note for Florence: A New Foundation Model for Computer Vision. This paper proposes a foundation model for vision (image/video) and text based on UniCL loss. It uses Swin-transformer and Roberta for the encoder.
Introduction
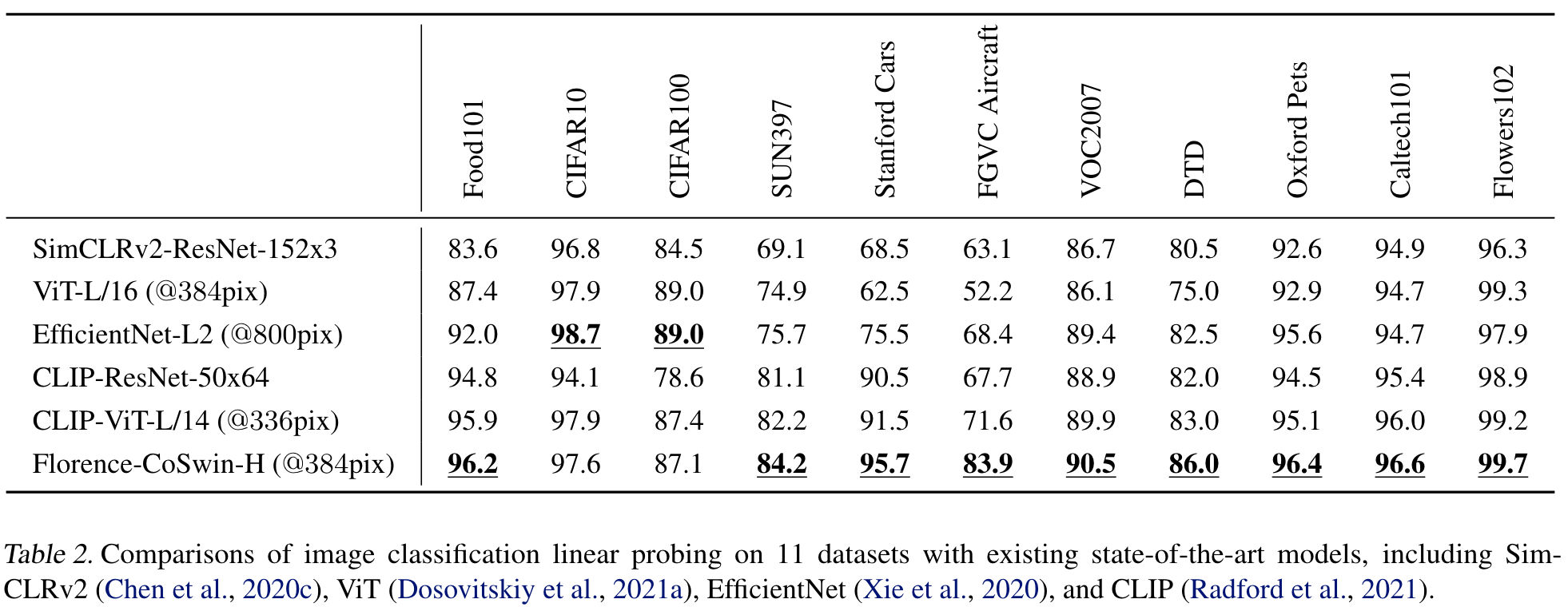
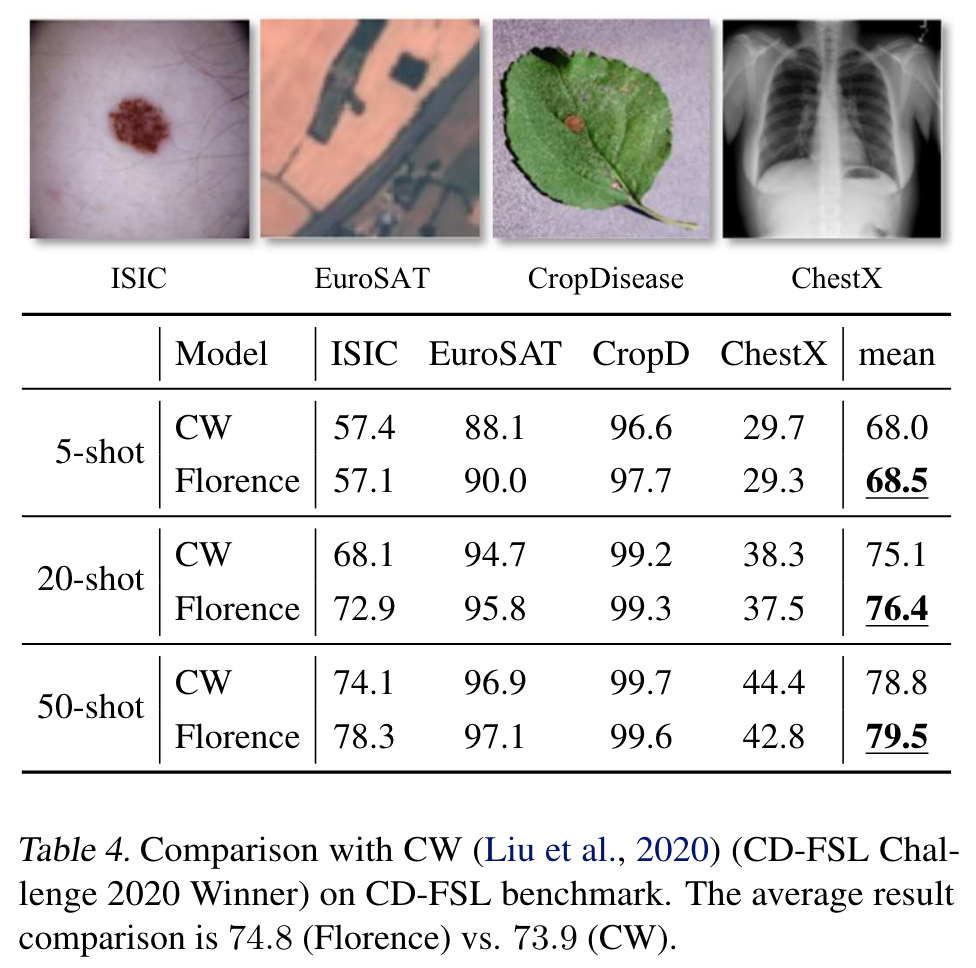
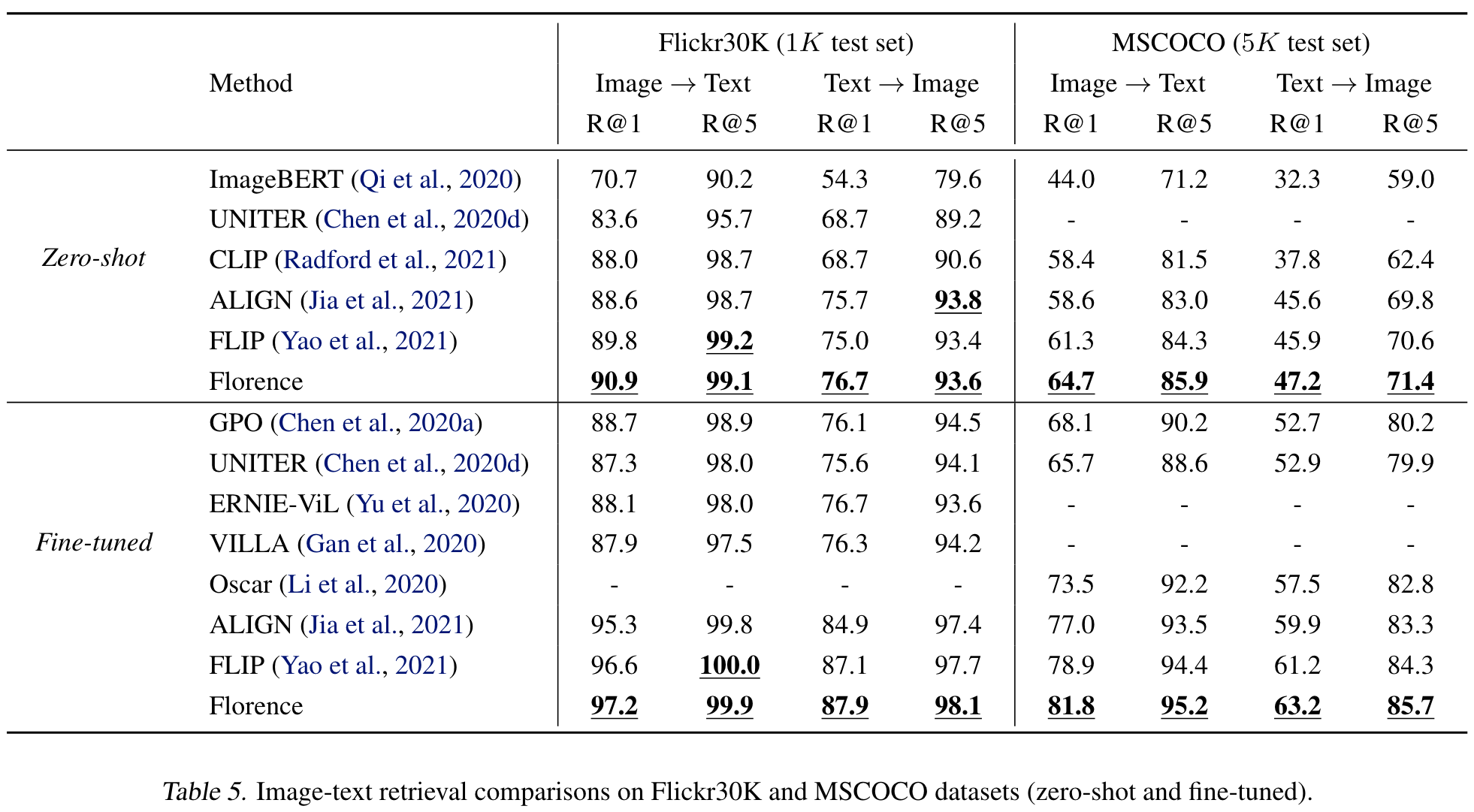
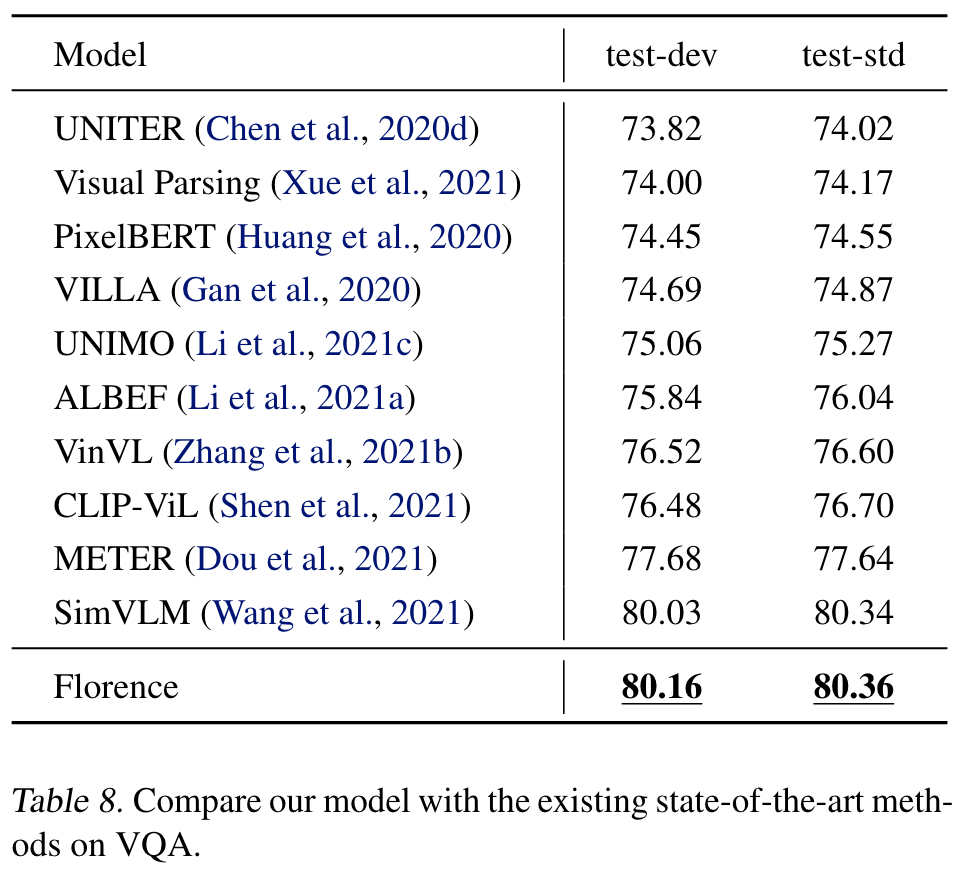
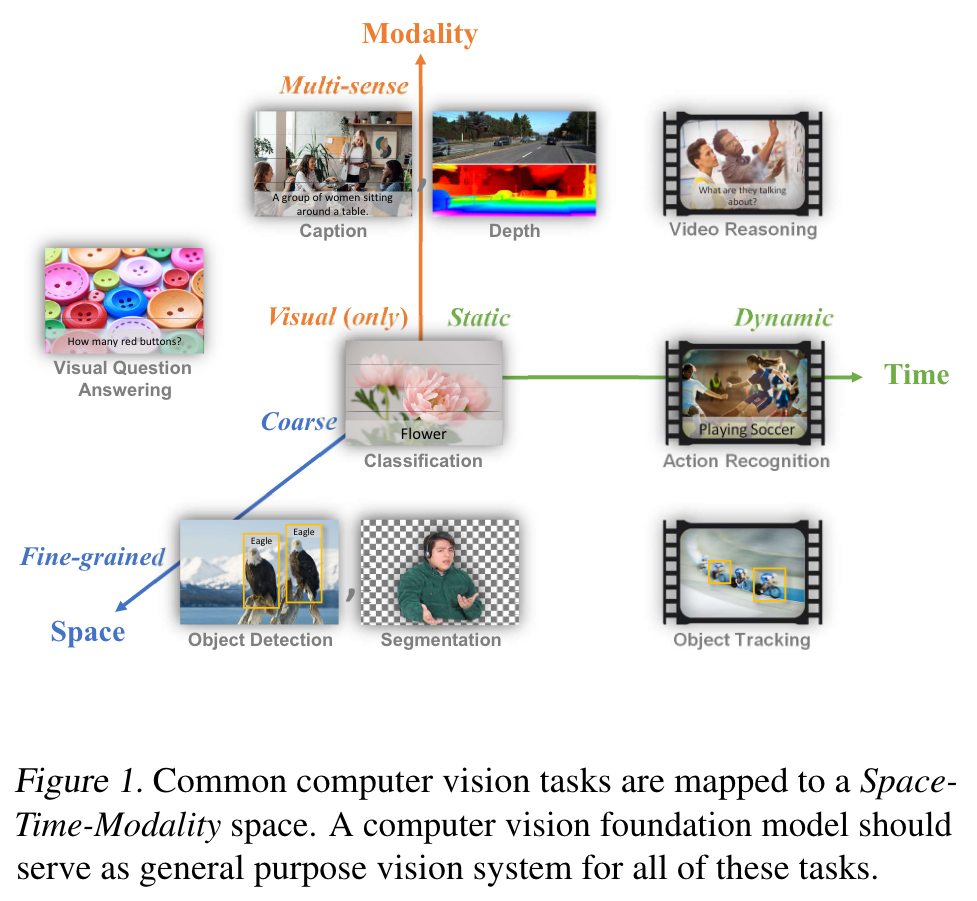
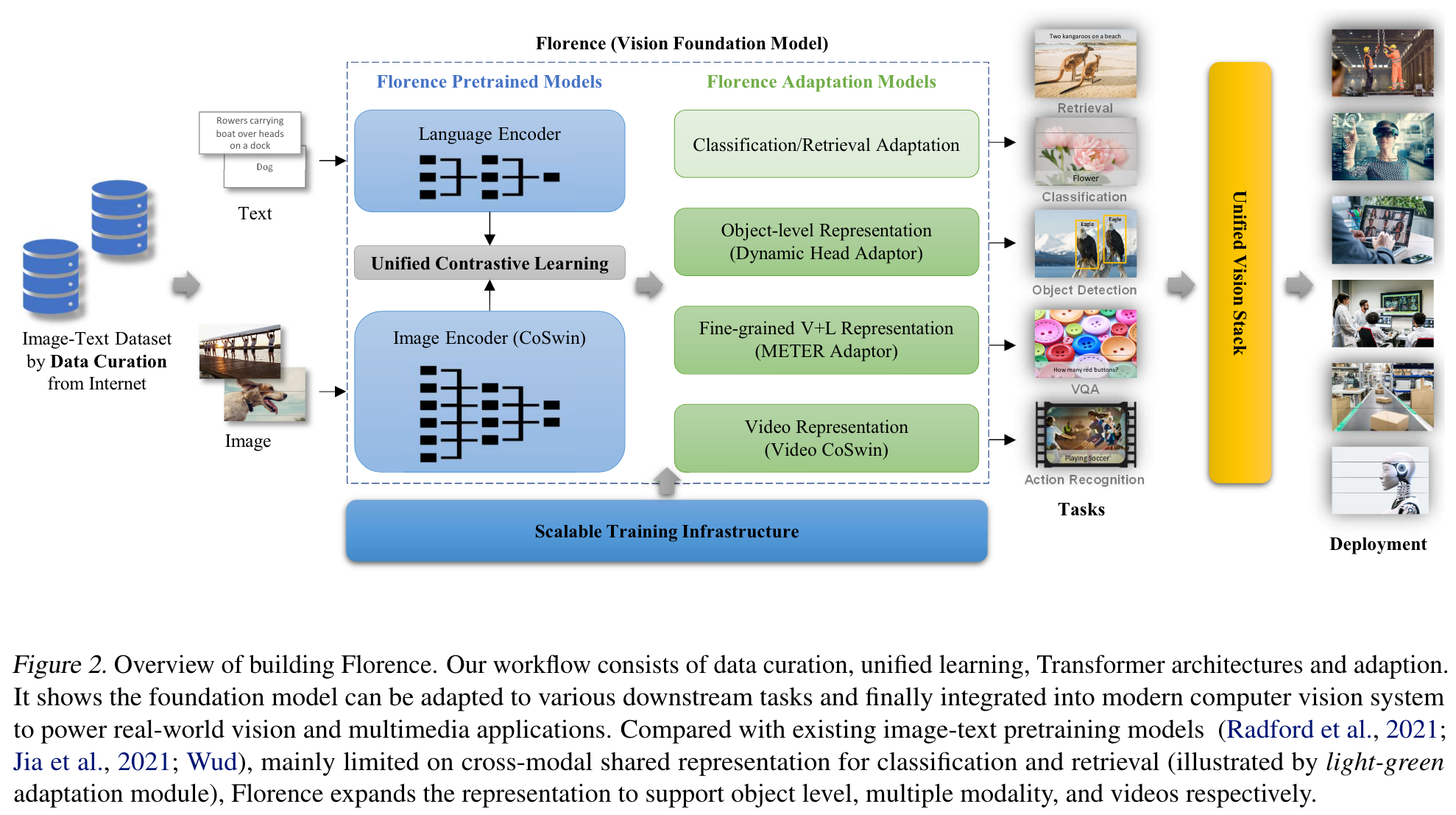
we introduce a new computer vision foundation model, Florence, to expand the representations from coarse (scene) to fine (object), from static (images) to dynamic (videos), and from RGB to multiple modalities (caption, depth). By incorporating universal visual-language representations from Web-scale image-text data, our Florence model can be easily adapted for various computer vision tasks, such as classification, retrieval, object detection, VQA, image caption, video retrieval and action recognition. (p. 1)
Approach
Dataset Curation
To improve data quality, we performed rigorous data filtering, similar to ALIGN (Jia et al., 2021), including a simple hash-based near-duplicate image removal, small-size image removal, image-text relevance, etc. In addition, we follow the sampling strategy introduced in (Radford et al., 2021; Ramesh et al., 2021) with the goal of achieving improved balance, informativeness, and learnability of the sampled dataset. The final form of the FLD-900M dataset consists of 900M images with 900M free-form texts (ranging from one word, phase to sentences), 9.7M unique queries, and 7.5B tokens in total. (p. 3)
Unified Image-Text Contrastive Learning
y is the language label (i.e. , hash key) indicating the index of unique language description in the dataset. Note that we only map identical language description to the same hash key, i.e. , language label. Thus, all image-text pairs mapped to the same label y are regarded as positive in our universal image-text contrastive learning. (p. 3)
Our empirical experiments indicate that long language descriptions with rich content would be more beneficial for image-text representation learning than short descriptions (e.g. , one or two words). We have to enrich the short description by generating prompt templates such as “A photo of the [WORD]”, “A cropped photo of [WORD]”, as data augmentation. During training, we randomly select one template to generate t for each short language description. (p. 4)
Although including generated language prompt might not affect classification accuracy, it hurts the performance in retrieval and visionlanguage tasks. To mitigate the negative effect from augmented prompts, our training is separated into two stages. In the first stage, we use all data including augmented texts for training; while in the second stage, we exclude all augmented data for continuing training. (p. 4)
The image size is 224 × 224 and the maximum language description length is truncated at 76. The batch size is 24, 576. (p. 4)
Transformer-based Florence Pretrained Models
Our Florence pretrained model uses a two-tower architecture: a 12-layer transformer (Vaswani et al., 2017) as language encoder, similar to CLIP (Radford et al., 2021), and a hierarchical Vision Transformer as the image encoder. The hierarchical Vision Transformer is a modified Swin Transformer (Liu et al., 2021a) with convolutional embedding, called CoSwin Transformer. Specifically, we replace the patch embedding and patch merging modules in the Swin Transformer (Liu et al., 2021a) with the convolutional embedding layers as described in CvT (Wu et al., 2021). We use the CoSwin Transformer with global average pooling to extract image features. Two linear projection layers are added on top of the image encoder and language encoder to match the dimensions of image and language features. (p. 4)
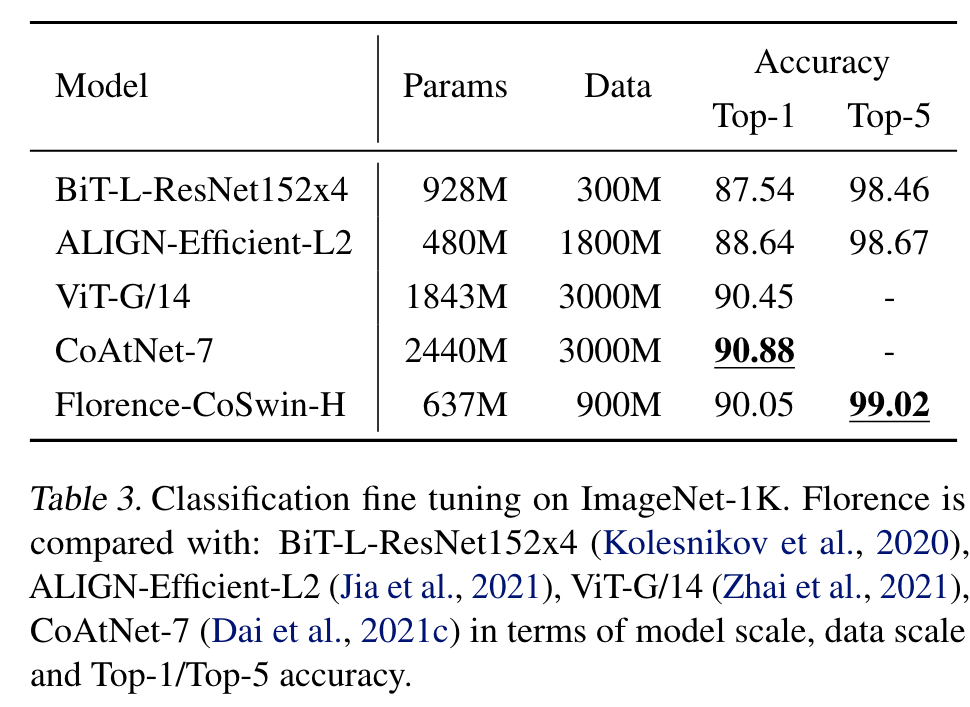
The model takes 10 days to train on 512 NVIDIA-A100 GPUs with 40GB memory per GPU. (p. 4)
Object-level Visual Representation Learning
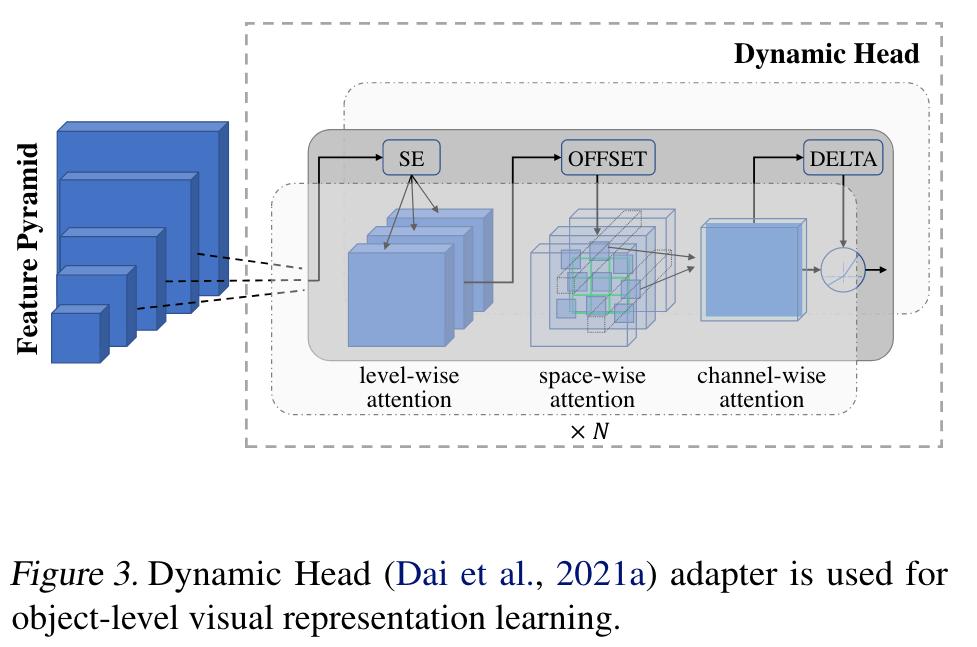
For this goal, we add an adaptor Dynamic Head (Dai et al., 2021a) (or Dynamic DETR (Dai et al., 2021b)), a unified attention mechanism for the detection head, to the pretrained image encoder (i.e. , CoSwin). We can continue visual representation learning from coarse (scene) to fine (object). (p. 4)
Based on the hierarchical structure of the image encoder CoSwin-H, we can get the output feature pyramids from the different scale levels. The feature pyramid scale levels can be concatenated and scaled-down or scaled-up into a 3-dimensional tensor with dimensions level × space × channel. The key idea of Dynamic Head (Dai et al., 2021a) is to deploy three attention mechanisms, each on one of the orthogonal dimensions of the tensor, i.e. , level-wise, spatialwise, and channel-wise. (p. 4)
Fine-Grained V+L Representation Learning
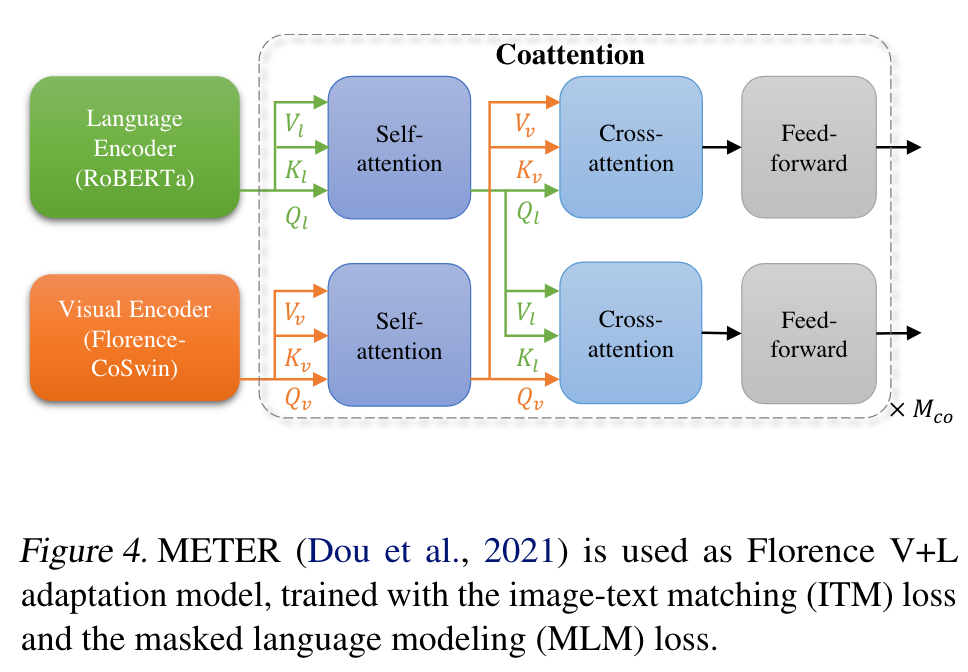
We use METER (Dou et al., 2021) adapter to expand to fine-grained vision-language representation. (p. 5)
In the Florence V+L adaptation model, we replace the image encoder of METER (Dou et al., 2021) with Florence pretrained model CoSwin, and use a pretrained Roberta (Liu et al., 2019) as the language encoder, shown in Figure 4. (p. 5)
Adaption to Video Recognition
- First, the image tokenization layer is replaced with a video tokenization layer. Accordingly, video CoSwin replaces the tokenization layer of CoSwin (in Section 2.3) from 2D convolutional layers to 3D convolutional layers, which converts each 3D tube into one token. (p. 5)
- Second, video CoSwin uses the 3D convolution-based patch merging operator instead of the 2D patch merging operator used in (Liu et al., 2021b). (p. 5)
- Third, we follow prior work (Liu et al., 2021b) to replace the 2D shifted window design with 3D shifted local windows in self-attention layers. (p. 5)
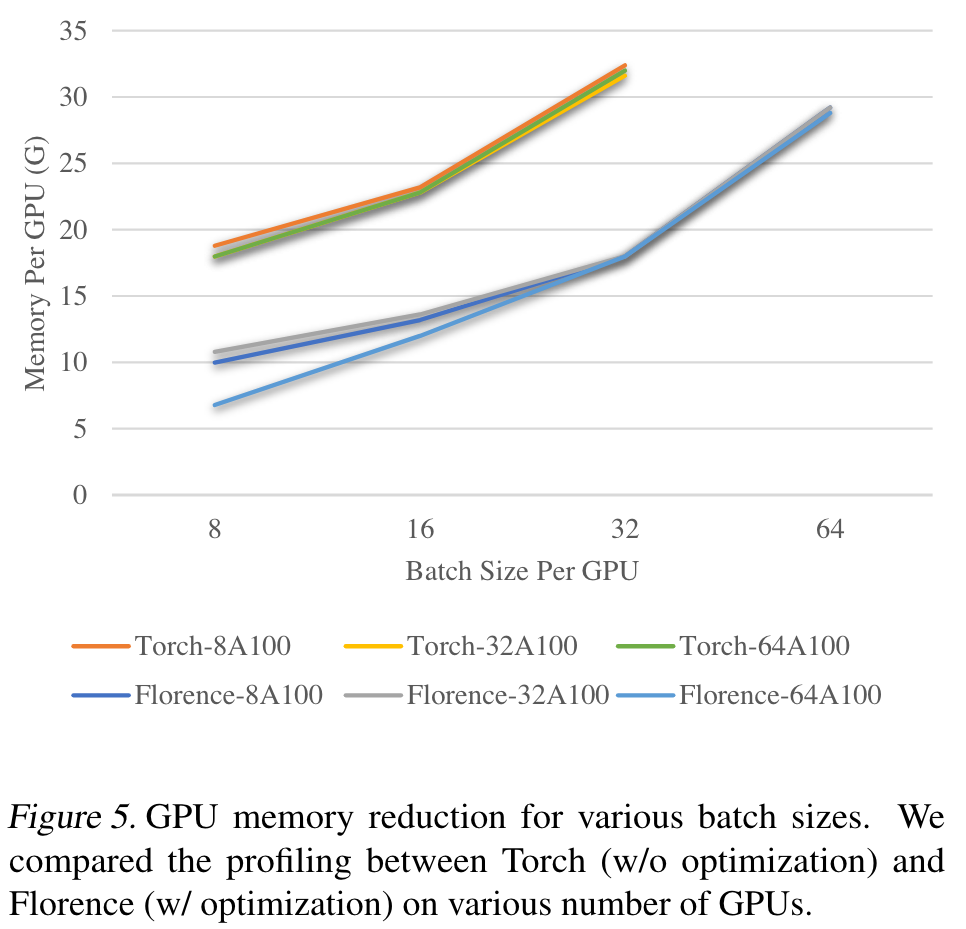
Scalable Training Infrastructure
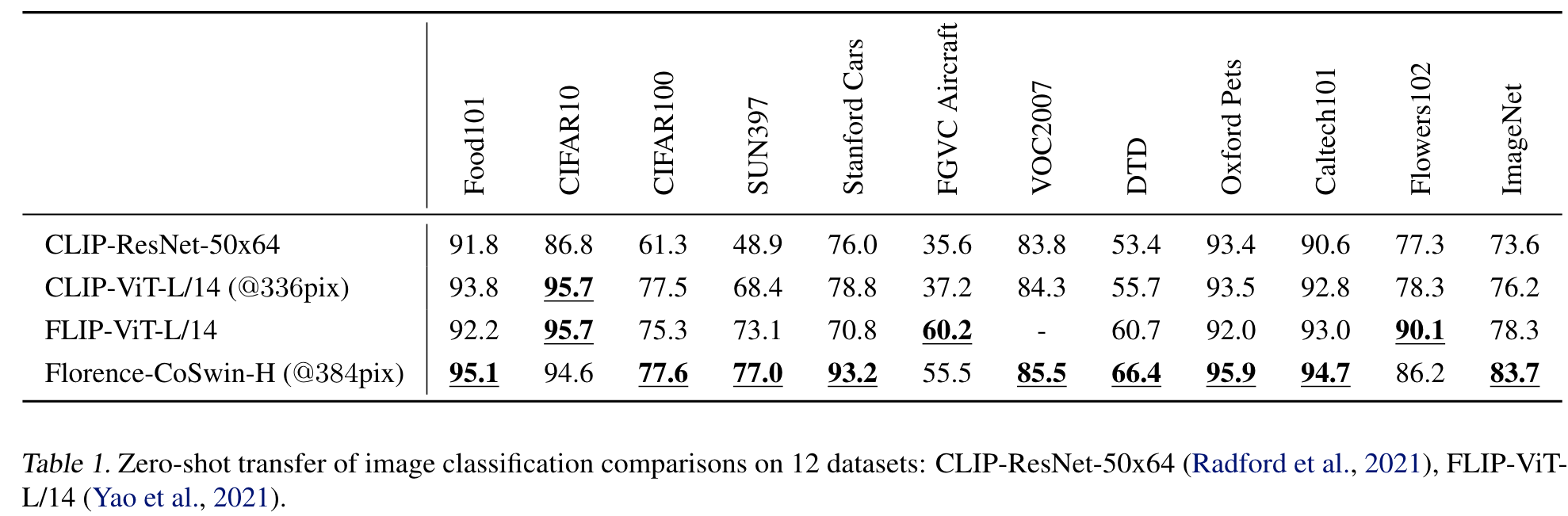
Experiments