Improved Baselines with Visual Instruction Tuning
[qwen-vl multimodal llm blip qformer deep-learning instruct-blip llava flamingo This is my reading note for Improved Baselines with Visual Instruction Tuning. This paper shows how to improve the performance of LLAVA with simple methods.
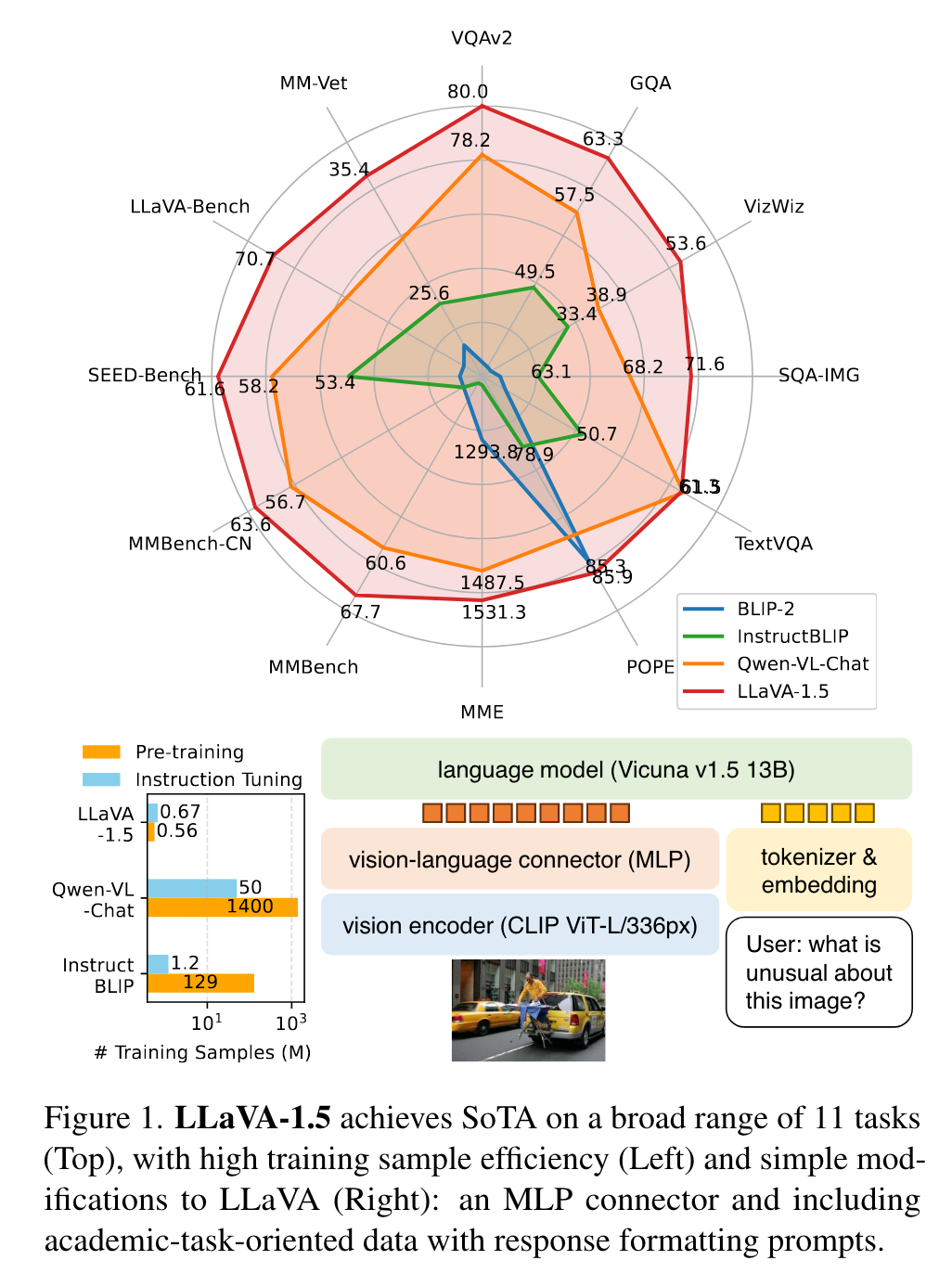
Introduction
In this note, we show that the fully-connected vision-language cross-modal connector in LLaVA is surprisingly powerful and data-efficient. (p. 1)
We report that two simple improvements, namely, an MLP cross-modal connector and incorporating academic task related data such as VQA, are orthogonal to the framework of LLaVA, and when used with LLaVA, lead to better multimodal understanding capabilities. In contrast to InstructBLIP [9] or Qwen-VL [2], which trains specially designed visual resamplers on hundreds of millions or even billions of image-text paired data, LLaVA uses the simplest architecture design for LMMs and requires only training a simple fully-connected projection layer on merely 600K image-text pairs. (p. 1)
Background
LLaVA [28] is perhaps the simplest architecture for LMMs. Optionally, visual resamplers (e.g. Qformer [24]) are used to reduce the number of visual patches [2, 9, 49]. Training an instruction-following LMM usually follows a two-stage protocol. First, the vision-language alignment pretraining stage leverages image-text pairs to align the visual features with the language model’s word embedding space. Earlier works utilize relatively few image-text pairs (e.g. ∼600K [28] or ∼6M [49]), while some recent works pretrain the visionlanguage connector for a specific language model on a large amount of image-text pairs (e.g. 129M [9] and 1.4B [2]), to maximize the LMM’s performance. Second, the visual instruction tuning stage tunes the model on visual instructions, to enable the model to follow users’ diverse requests on instructions that involve the visual contents. (p. 2)
For visual instruction tuning, LLaVA [28] is the pioneer to leverage text-only GPT-4 to expand the existing COCO [27] bounding box and caption dataset to a multimodal instruction-following dataset that contains three types of instruction-following data: conversational-style QA, detailed description, and complex reasoning. (p. 2)
Improved Baselines of LLaVA
Overview
As the initial work of visual instruction tuning, LLaVA has showcased commendable proficiency in visual reasoning capabilities, surpassing even more recent models on diverse benchmarks for real-life visual instructionfollowing tasks, while only falling short on academic benchmarks that typically require short-form answers (e.g. singleword). The latter was attributed to the fact that LLaVA has not been pretrained on large-scale data, as other approaches do. (p. 2)
We show that the LLaVA’s architecture is powerful and dataefficient for visual instruction tuning, and achieves the best performance using significantly less compute and training data than all other methods. (p. 2)
Response formatting prompts
We find that the inability [5] to balance between shortand long-form VQA for approaches like InstructBLIP [9] is mainly due to the following reasons. First, ambiguous prompts on the response format. For example, Q: {Question} A: {Answer}. Such prompts do not clearly indicate the desirable output format, and can overfit an LLM behavorially to short-form answers even for natural visual conversations. Second, not finetuning the LLM. The first issue is worsened by InstructBLIP only finetuning the Qformer for instruction-tuning. It requires the Qformer’s visual output tokens to control the length of the LLM’s output to be either long-form or short-form, as in prefix tuning [25], but Qformer may lack the capability of properly doing so, due to its limited capacity compared with LLMs like LLaMA. See Table 6 for a qualitative example. (p. 2)
To address this, we propose to use a single response formatting prompt that clearly indicates the output format, to be appended at the end of VQA questions when promoting short answers: Answer the question using a single word or phrase. We empirically show that when LLM is finetuned with such prompts, LLaVA is able to properly adjust the output format according to the user’s instructions (p. 2)
MLP vision-language connector
Inspired by the improved performance in self-supervised learning by changing from a linear projection to an MLP [7, 8], we find that improving the vision-language connector’s representation power with a twolayer MLP can improve LLaVA’s multimodal capabilities, compared with the original linear projection design. (p. 3)
Academic task oriented data
We further include additional academic-task-oriented VQA datasets for VQA, OCR, and region-level perception, to enhance the model’s capabilities in various ways, (p. 3)
Additional scaling
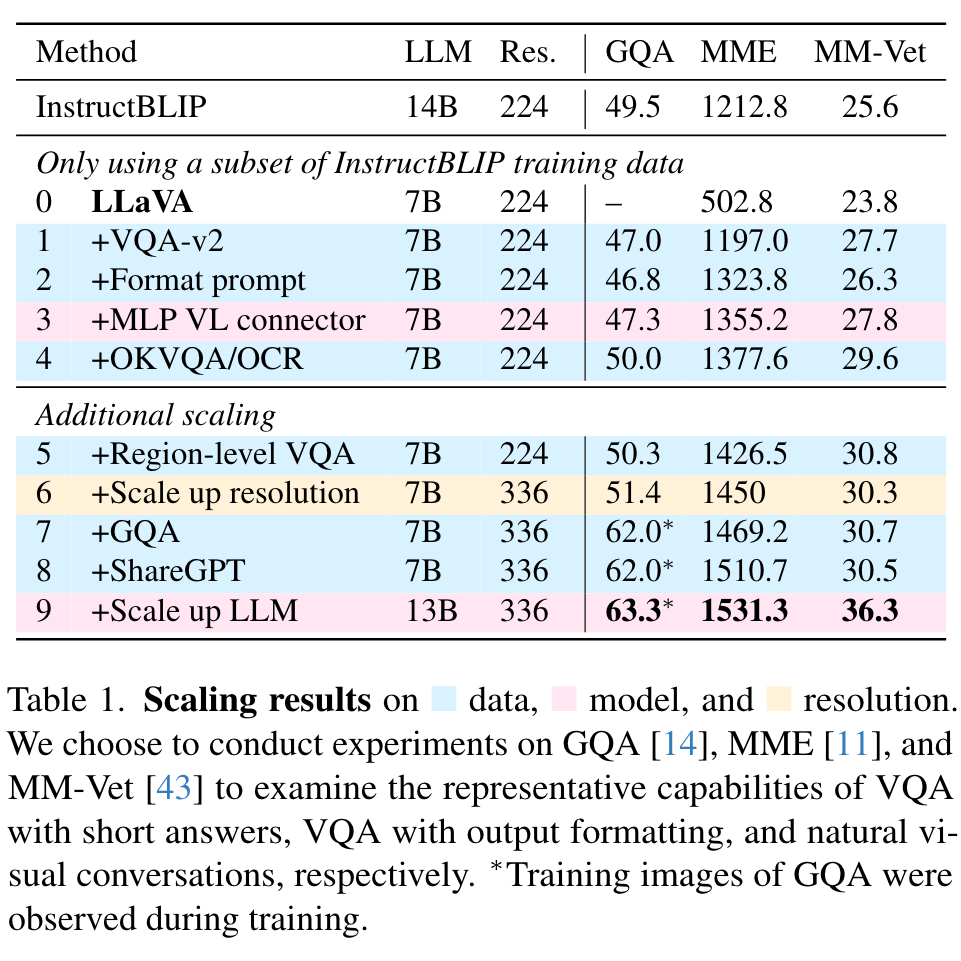
on MM-Vet shows the most significant improvement when scaling the LLM to 13B, suggesting the importance of the base LLM’s capability for visual conversations. (p. 3)
Discussion
Comparison with SoTA
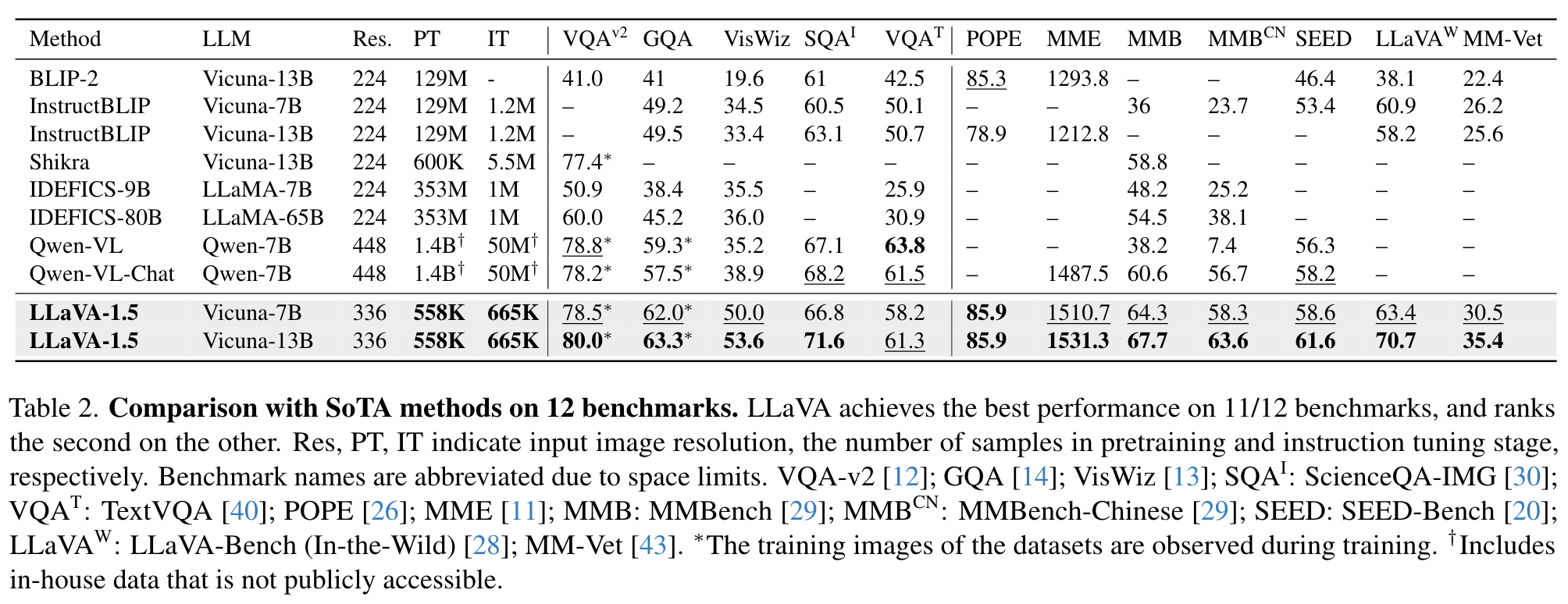
We show that it achieves the best performance across 11 out of 12 benchmarks, despite using magnitudes smaller pretraining and instruction tuning data compared with other methods [2, 9]. It is encouraging that LLaVA-1.5 achieves the best performance with the simplest architecture, academic compute and public datasets, and yields a fully-reproducible and affordable baseline for future research. The results also suggest that visual instruction tuning plays a more important role in improving an LMM’s capabilities than pretraining, and raises questions upon the common belief that LMMs require significant amount of vision-language alignment pretraining [2, 9, 24], despite that the vision encoders (e.g. CLIP [36], OpenCLIP [16], EVA-CLIP [10], etc.) are already pretrained on web-scale image-text paired dataset (p. 3)
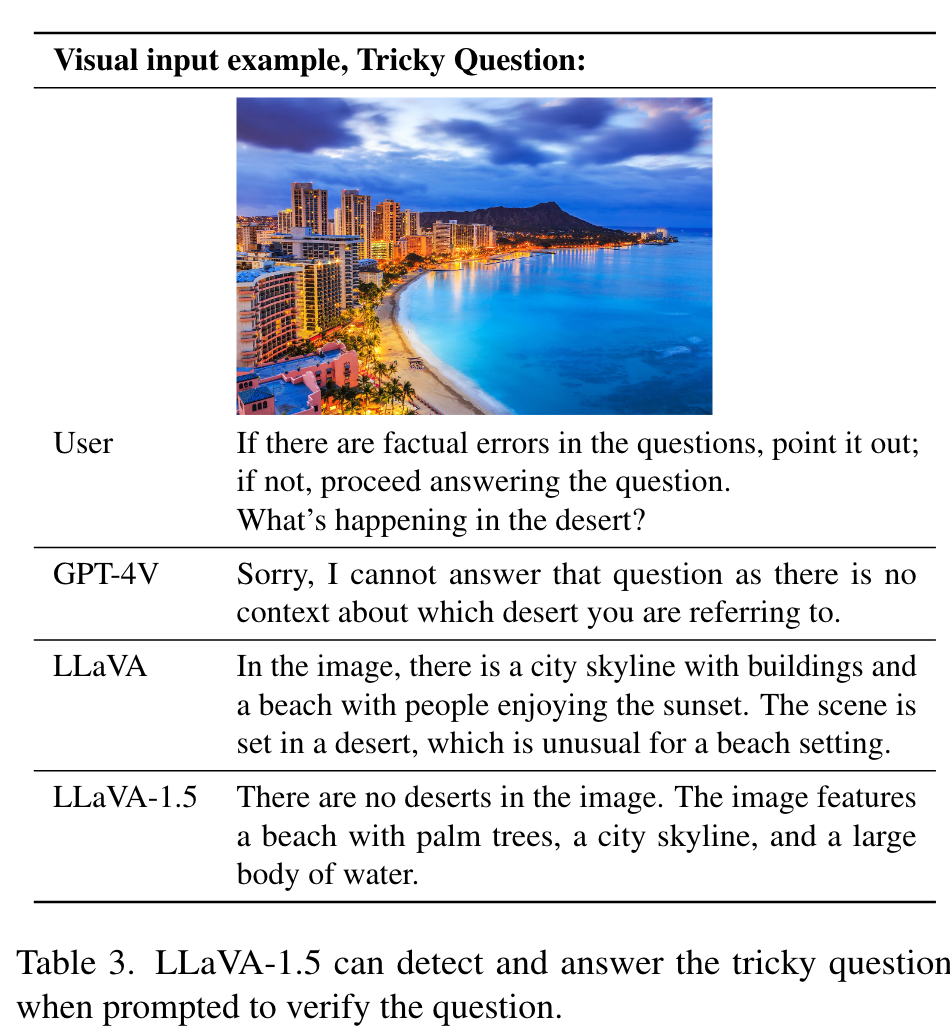
Zero-shot format instruction generalization
Although LLaVA-1.5 is only trained with a limited number of format instructions, it generalizes to others. (p. 3)
Zero-shot multilingual capability
Though LLaVA-1.5 is not finetuned for multilingual multimodal instruction following at all, we find that it is capable of following multilingual instructions, partly due to the multilingual language instructions in ShareGPT [38]. (p. 4)
Limitations
Despite the promising results demonstrated by LLaVA-1.5, several limitations must be acknowledged. First, LLaVA utilizes full image patches, potentially prolonging each training iteration. While visual resamplers [2, 9, 24] reduce the number of visual patches in LLMs, they currently cannot achieve convergence as efficiently as LLaVA with a comparable amount of training data, probably due to more trainable parameters in the resamplers. The development of a sample-efficient visual resampler could pave the way for future scaling-up of instruction-following multimodal models. Second, LLaVA-1.5 is not yet capable of processing multiple images due to the lack of such instruction-following data, and the limit of the context length. Third, although LLaVA1.5 exhibits proficiency in following complex instructions, its problem-solving capabilities can still be limited in certain domains, which could be improved with a more capable language model and with high-quality, targeted visual instruction tuning data. Finally, despite its significantly reduced propensity for hallucination, LLaVA is not exempt from producing hallucinations and occasionally disseminating misinformation, and should be used with caution in critical applications (e.g. medical). (p. 4)

