NExT-GPT Any-to-Any Multimodal LLM
[blip-2 vicuna multimodal q-former image2image image-bind llava diffusion deep-learning visual-chatgpt text2image video-llama flamingo text2video panda-gpt llm gpt speech-gpt codi modality-switching-instruction-tunning transformer This is my reading note for NExT-GPT: Any-to-Any Multimodal LLM. This paper proposes a multiple modality model which could takes multiple modalities as input and output in multiple modalities as well. The paper leverage existing large language model, multiple modality encoder image bind) and multiple modality diffusion model. To Amish the spice of those components, a simple linear projection is used for input and transformer to the output.
Introduction
To fill the gap, we present an end-to-end general-purpose any-to-any MM-LLM system, NExT-GPT. We connect an LLM with multimodal adaptors and different diffusion decoders, enabling NExT-GPT to perceive inputs and generate outputs in arbitrary combinations of text, images, videos, and audio. By leveraging the existing well-trained highly-performing encoders and decoders, NExT-GPT is tuned with only a small amount of parameter (1%) of certain projection layers, which not only benefits low-cost training and also facilitates convenient expansion to more potential modalities. Moreover, we introduce a modality-switching instruction tuning (MosIT) and manually curate a high-quality dataset for MosIT, based on which NExT-GPT is empowered with complex cross-modal semantic understanding and content generation. (p. 1)
- The LLM not only directly generates text tokens but also produces unique “modality signal” tokens that serve as instructions to dictate the decoding layers whether & what modal content to output correspondingly (p. 2)
- we take advantage of the existing pre-trained high-performance encoders and decoders, such as Q-Former [43], ImageBind [25] and the state- of-the-art latent diffusion models [68, 69, 8, 2, 51, 33]. (p. 2)
- For the feature alignment across the three tiers, we consider fine-tuning locally only the input projection and output projection layers, with an encoding-side LLM-centric alignment and decoding- side instruction-following alignment (p. 2)
- Furthermore, to empower our any-to-any MM-LLM with human-level capabilities in complex cross-modal generation and reasoning, we introduce a modality-switching instruction tuning (termed Mosit), equipping the system with sophisticated cross-modal semantic understanding and content generation. (p. 2)
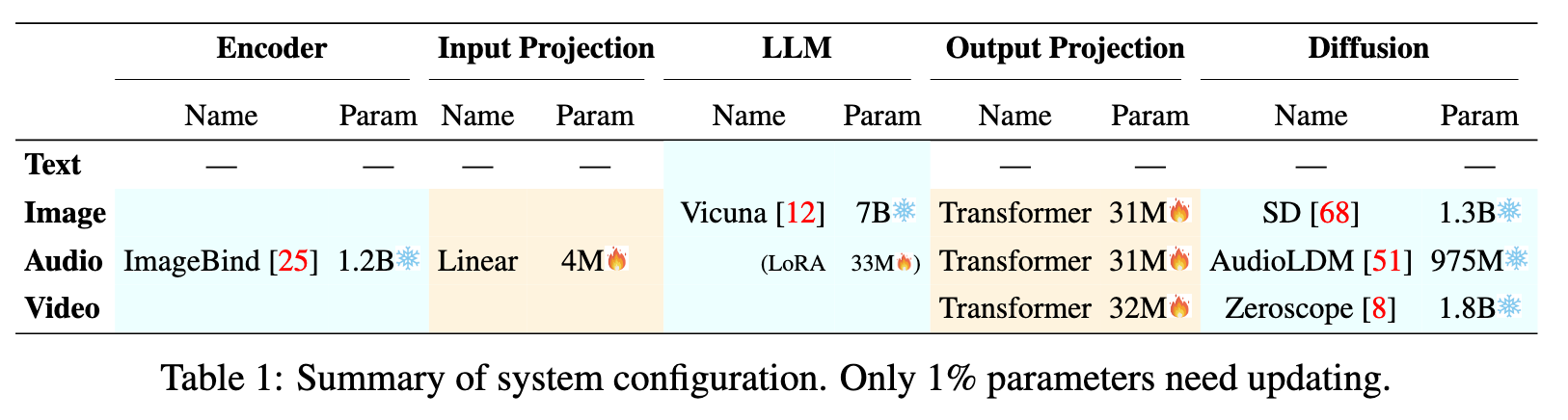
- Employing the LoRA technique [32], we fine-tune the overall NExT-GPT system on MosIT data, updating the projection layers and certain LLM parameters. (p. 3)
Related Work
A notable approach involves employing adapters that align pre-trained encoders in other modalities to textual LLMs. This endeavor has led to the rapid development of multimodal LLMs (MM-LLMs), such as BLIP-2 [43], Flamingo [1], MiniGPT-4 [110], Video-LLaMA [104], LLaVA [52], PandaGPT [77], SpeechGPT [103]. Nevertheless, most of these efforts pay the attention to the multimodal content understanding at the input side, lacking the ability to output content in multiple modalities more than texts (p. 2)
Lately, CoDi [78] has made strides in implementing the capability of simultaneously processing and generating arbitrary combinations of modalities, while it lacks the reasoning and decision-making prowess of LLMs as its core, and also is limited to the simple paired content generation. On the other hand, some efforts, e.g., visual-ChatGPT [88] and HuggingGPT [72] have sought to combine LLMs with external tools to achieve approximately the ‘any-to-any’ multimodal understanding and generation. Unfortunately, these systems suffer from critical challenges due to the complete pipeline architecture. First, the information transfer between different modules is entirely based on discrete texts produced by the LLM, where the cascade process inevitably introduces noise and propagates errors. More critically, the entire system only leverages existing pre-trained tools for inference only. Due to the lack of overall end-to-end training in error propagation, the capabilities of content understanding and multimodal generation can be very limited, especially in interpreting intricate and implicit user instructions. In a nutshell, there is a compelling need for constructing an end-to-end MM-LLM of arbitrary modalities. (p. 2)
On the one hand, most of the researchers build fundamental MM-LLMs by aligning the well-trained encoders of various modalities to the textual feature space of LLMs, so as to let LLMs perceive other modal inputs [35, 110, 76, 40]. For example, Flamingo [1] uses a cross-attention layer to connect a frozen image encoder to the LLMs. BLIP-2 [43] employs a Q-Former to translate the input image queries to the LLMs. LLaVA [52] employs a simple projection scheme to connect image features into the word embedding space. There are also various similar practices for building MM-LLMs that are able to understand videos (e.g., Video-Chat [44] and Video-LLaMA [104]), audios (e.g., SpeechGPT [103]), etc. Profoundly, PandaGPT [77] achieves a comprehensive understanding of six different modalities simultaneously by integrating the multimodal encoder, i.e., ImageBind [25]. (p. 3)
To achieve LLMs with both multimodal input and output, some thus explore employing LLMs as decision-makers, and utilizing existing off-the- shelf multimodal encoders and decoders as tools to execute multimodal input and output, such as Visual visual-ChatGPT [88], HuggingGPT [72], and AudioGPT [34]. As aforementioned, passing messages between modules with pure texts (i.e., LLM textual instruction) under the discrete pipeline scheme will inevitably introduce noises. Also lacking comprehensive tuning across the whole system significantly limits the efficacy of semantics understanding (p. 4)
Overall Architecture
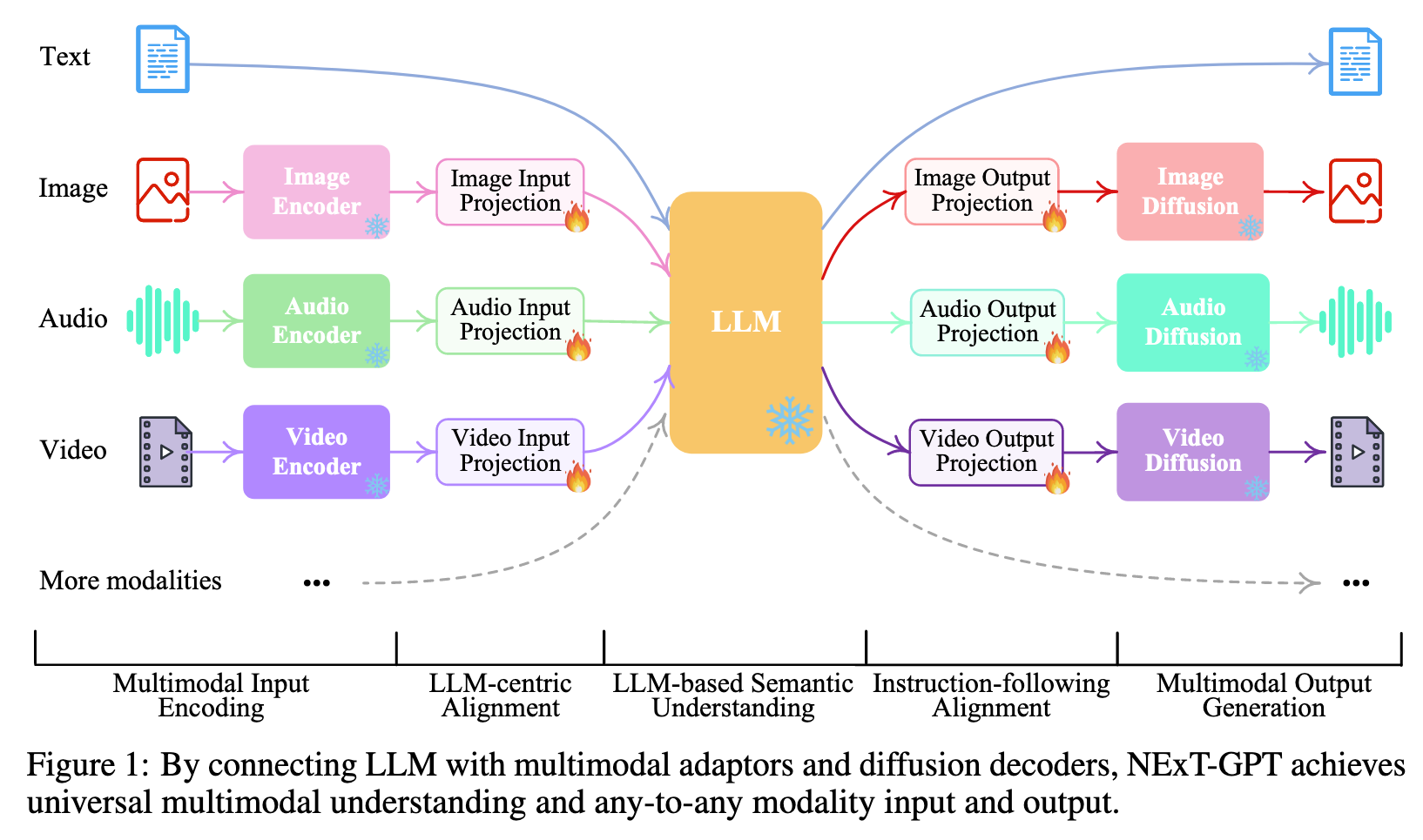
Multimodal Encoding Stage
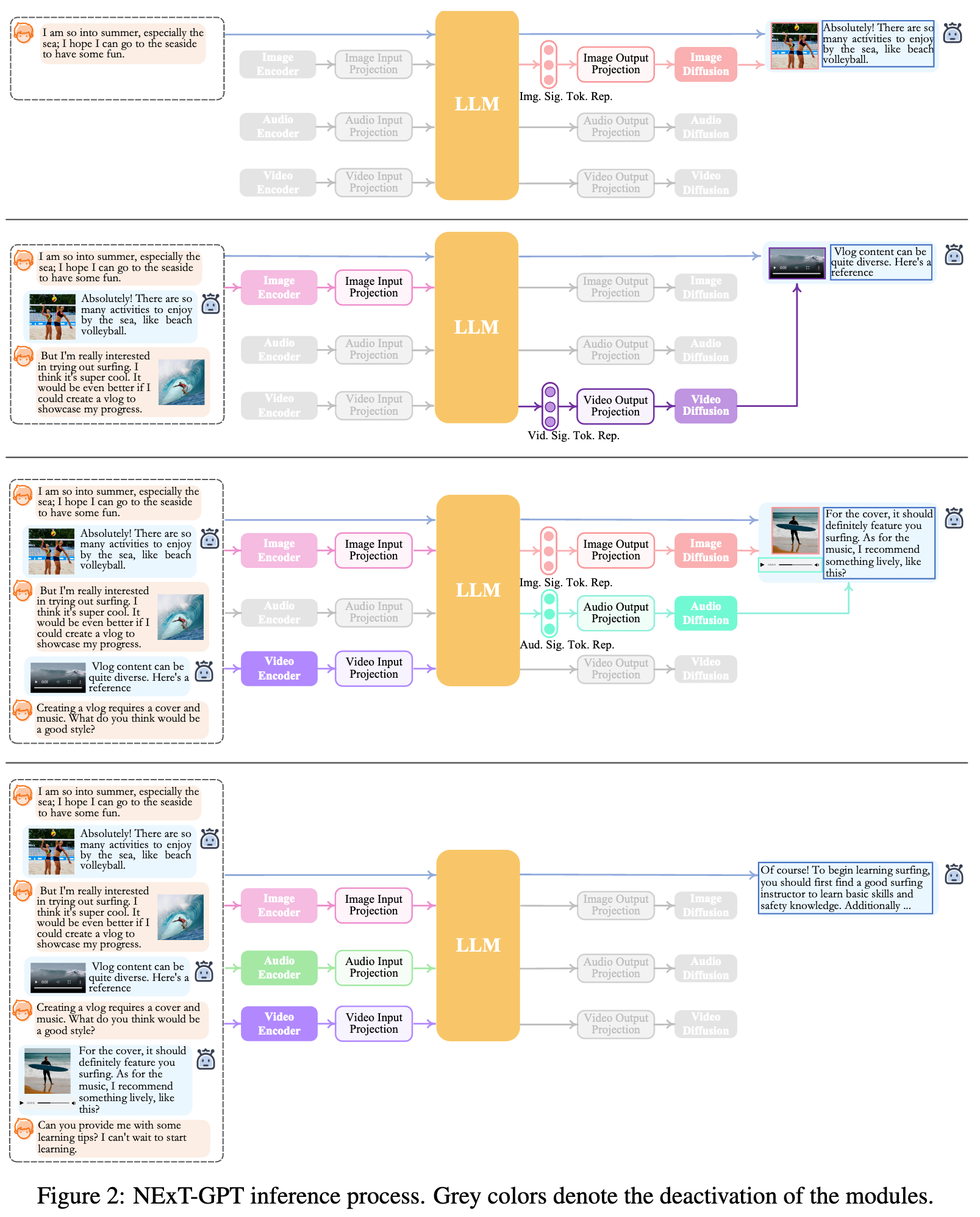
Here we take advantage of the ImageBind [25], which is a unified high-performance encoder across six modalities. Then, via the linear projection layer, different input representations are mapped into language-like representations that are comprehensible to the LLM. (p. 5)
LLM Understanding and Reasoning Stage
LLM takes as input the representations from different modalities and carries out semantic understanding and reasoning over the inputs. It outputs 1) the textual responses directly, and 2) signal tokens of each modality that serve as instructions to dictate the decoding layers whether to generate multimodal contents, and what content to produce if yes. (p. 5)
Multimodal Generation Stage
Receiving the multimodal signals with specific instructions from LLM (if any), the Transformer-based output projection layers map the signal token representations into the ones that are understandable to following multimodal decoders. Technically, we employ the current off-the-shelf latent conditioned diffusion models of different modal generations, i.e., Stable Diffusion (SD)3 for image synthesis [68], Zeroscope4 for video synthesis [8], and AudioLDM5 for audio synthesis [51]. The signal representations are fed into the condition encoders of the conditioned diffusion models for content generation. (p. 5)
Lightweight Multimodal Alignment Learning
To bridge the gap between the feature space of different modalities, and ensure fluent semantics understanding of different inputs, it is essential to perform alignment learning for NExT-GPT. Since we design the loosely-coupled system with mainly three tiers, we only need to update the two projection layers at the encoding side and decoding side. (p. 5)
Encoding-side LLM-centric Multimodal Alignment
Following the common practice of existing MM-LLMs, we consider aligning different inputting multimodal features with the text feature space To accomplish the alignment, we prepare the ‘X-caption’ pair (‘X’ stands for image, audio, or video) data from existing corpus and benchmarks. We enforce LLM to produce the caption of each input modality against the gold caption. Figure 3(a) illustrates the learning process. (p. 6)
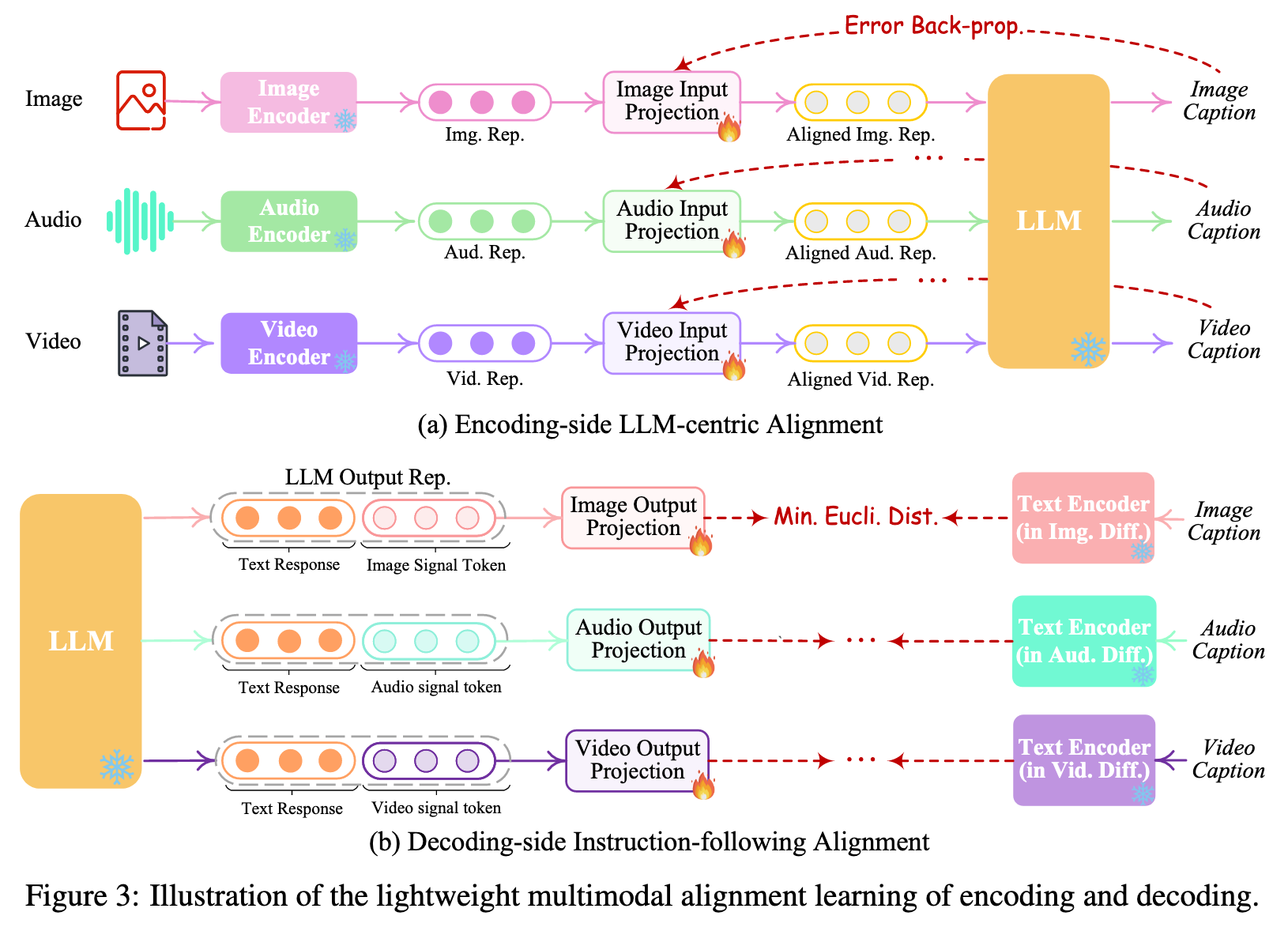
Decoding-side Instruction-following Alignment
Our main purpose is to align the diffusion models with LLM’s output instructions. However, performing a full-scale alignment process between each diffusion model and the LLM would entail a significant computational burden. Thus, we consider minimizing the distance between the LLM’s modal signal token representations (after each Transformer-based project layer) and the conditional text representations of the diffusion models. Since only the textual condition encoders are used (with the diffusion backbone frozen), the learning is merely based on the purely captioning texts, i.e., without any visual or audio inputs. This also ensures highly lightweight training. (p. 6)
Modality-switching Instruction Tuning
Instruction Tuning
Despite aligning both the encoding and decoding ends with LLM, there remains a gap towards the goal of enabling the overall system to faithfully follow and understand users’ instructions and generate desired multimodal outputs. To address this, further instruction tuning (IT) [97, 77, 52] is deemed necessary to enhance the capabilities and controllability of LLM. IT involves additional training of overall MM-LLMs using ‘(INPUT, OUTPUT)’ pairs, where ‘INPUT’ represents the user’s instruction, and ‘OUTPUT’ signifies the desired model output that conforms to the given instruction.
Technically, we leverage LoRA [32] to enable a small subset of parameters within NExT-GPT to be updated concurrently with two layers of projection during the IT phase. As illustrated in Figure 4, when an IT dialogue sample is fed into the system, the LLM reconstructs and generates the textual content of input (and represents the multimodal content with the multimodal signal tokens). The optimization is imposed based on gold annotations and LLM’s outputs. In addition to the LLM tuning, we also fine-tune the decoding end of NExT-GPT. We align the modal signal token representation encoded by the output projection with the gold multimodal caption representation encoded by the diffusion condition encoder. Thereby, the comprehensive tuning process brings closer to the goal of faithful and effective interaction with users. (p. 7)
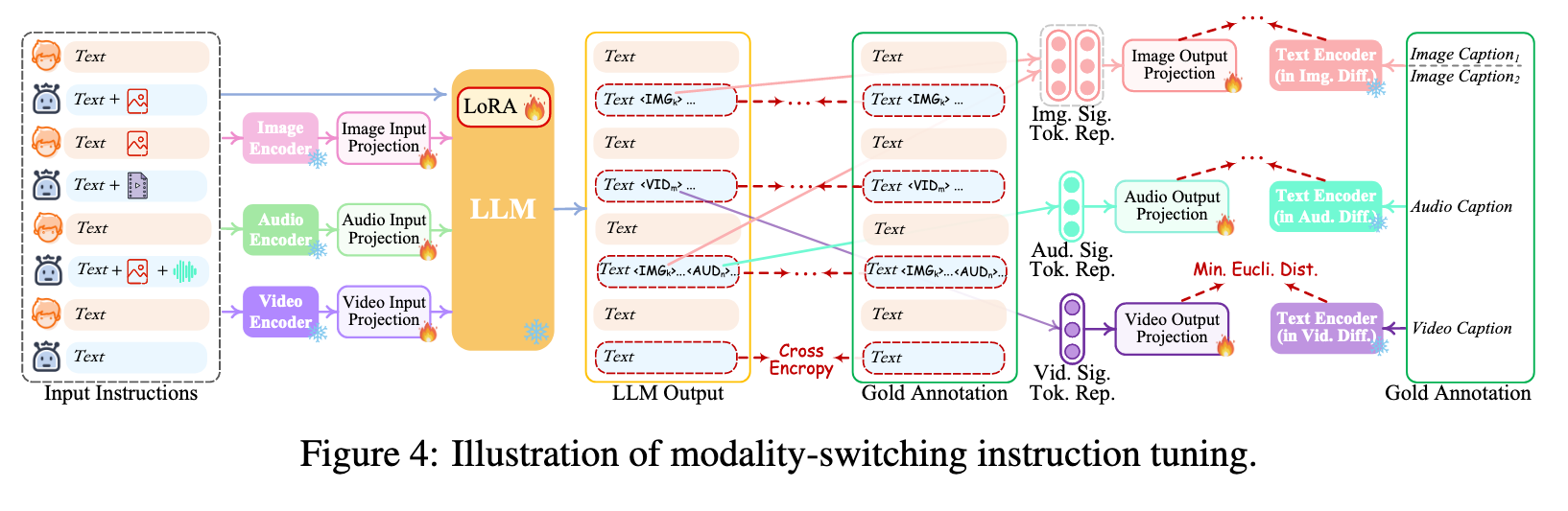
Instruction Dataset
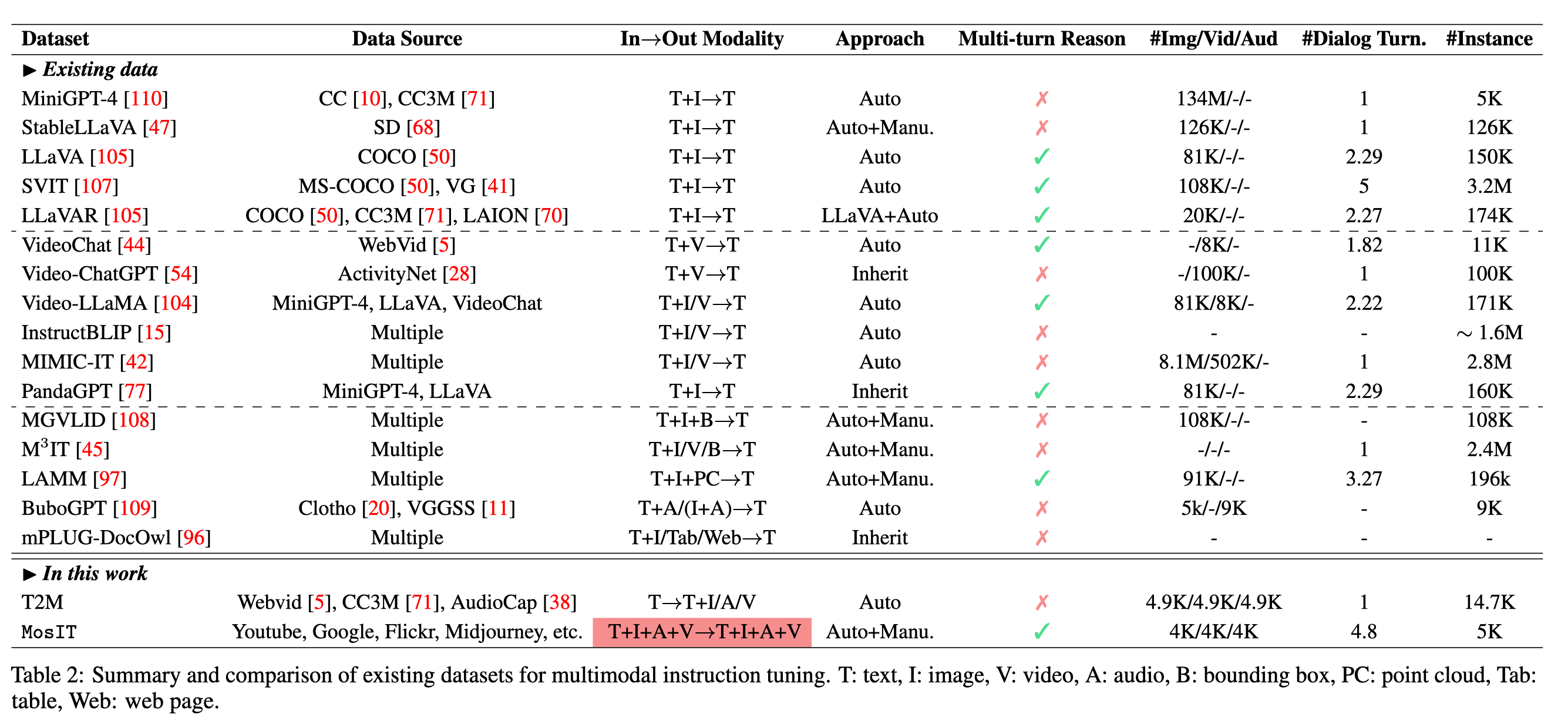
Specifically, we design some template dialogue examples between a ‘Human’ role and a ‘Machine’ role, based on which we prompt the GPT-4 to generate more conversations under various scenarios with more than 100 topics or keyword Whenever containing multimodal contents (e.g., image, audio, and video) in the conversations, we look for the best-matched contents from the external resources, including the retrieval systems, e.g., Youtube7, and even AIGC tools, e.g., Stable-XL (p. 7). Midjourney8. After human inspections and filtering of inappropriate instances, we obtain a total of 5K dialogues in low quality (p. 9)
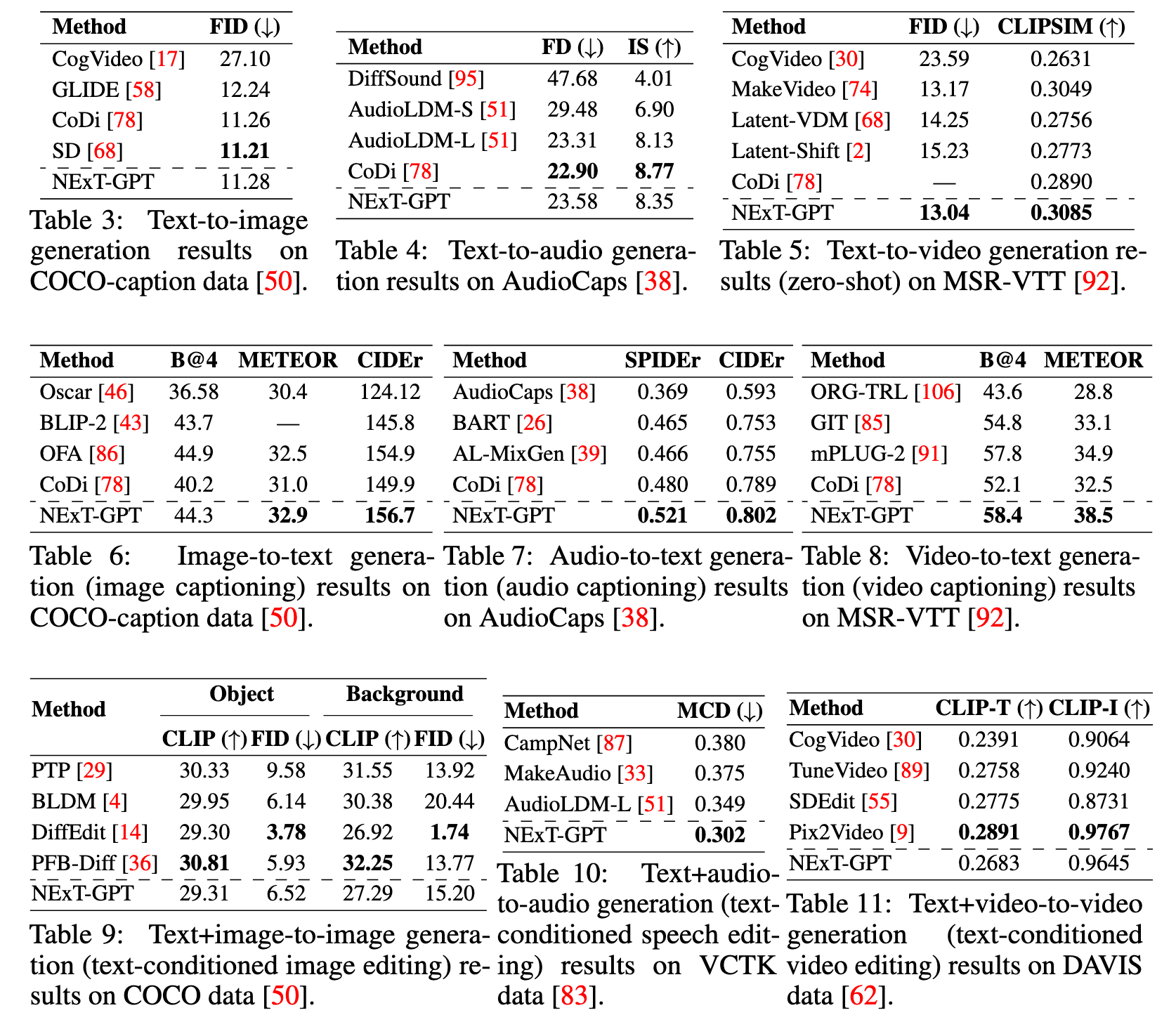
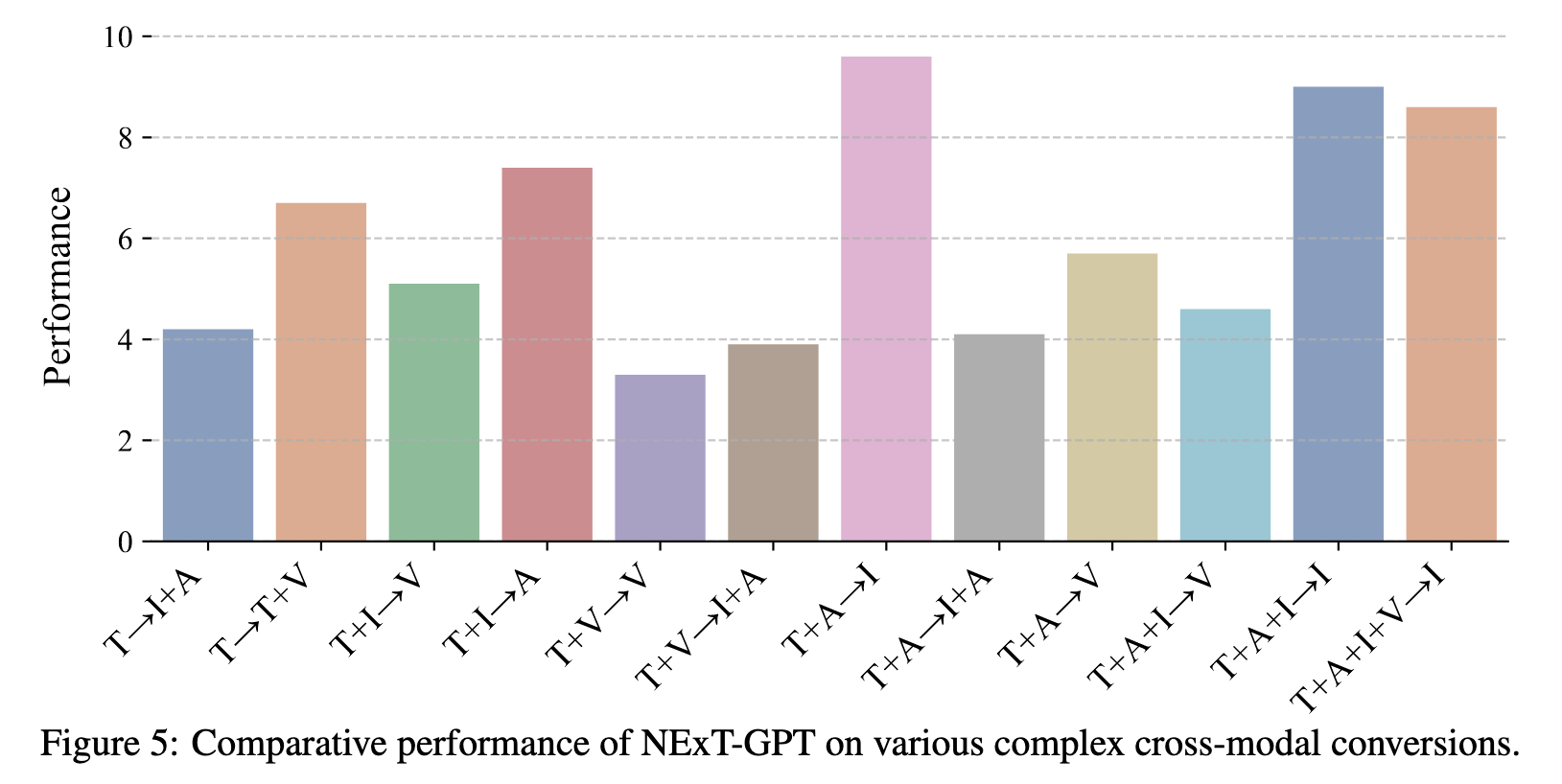
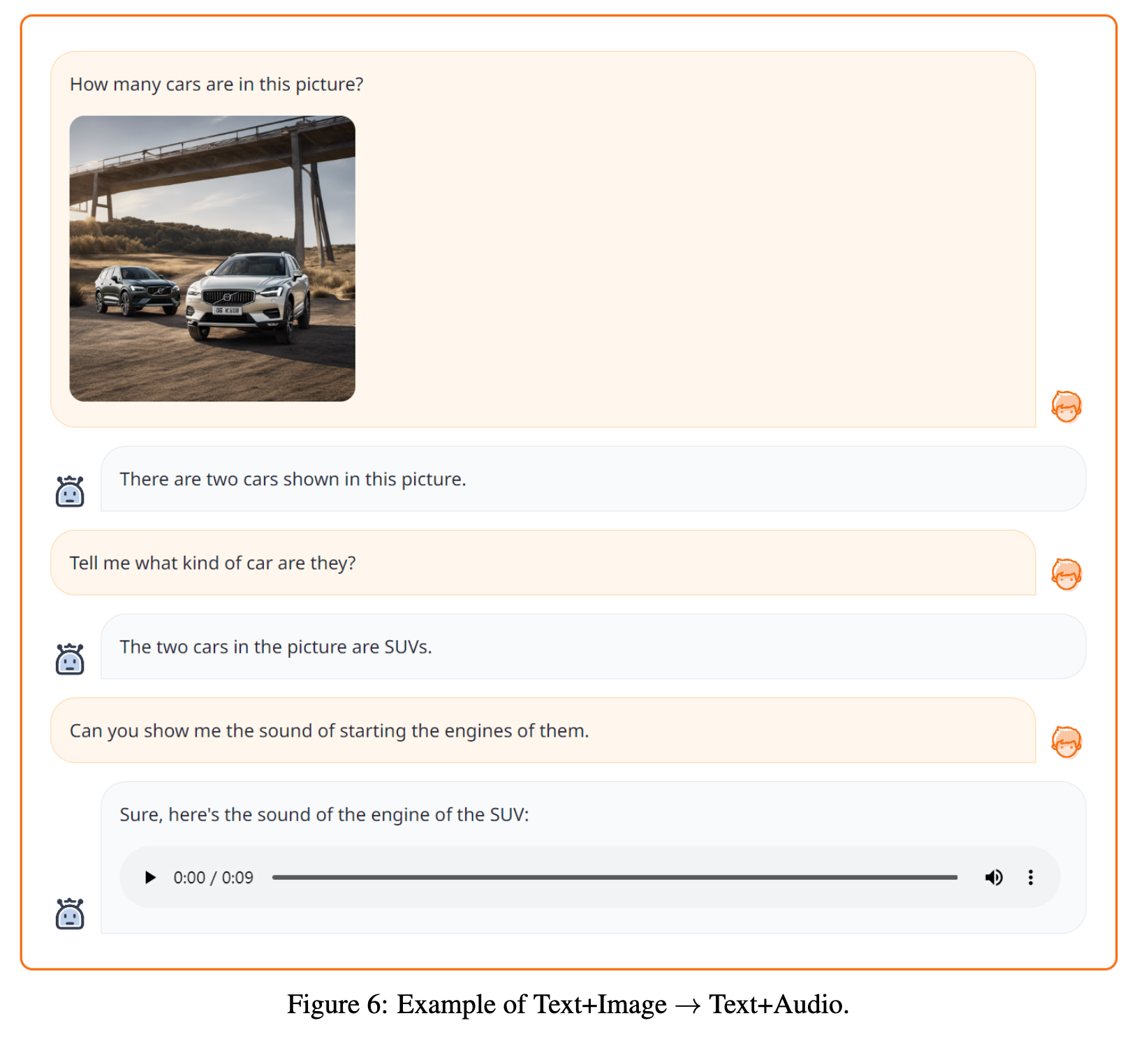
Experiment