Qwen-VL A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
[global-attention bert clip pali multimodal llm blip2 object-detection blip query-transformer vit align qformer ablef deep-learning window-attention coca This is my reading note for Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond. This paper proposes a vision-language model capable of vision grounding and image text reading. To do that, it considers visual grounding and OCR tasks in pre-training. In architecture, the paper uses Qformer from BLIP2.

Introduction
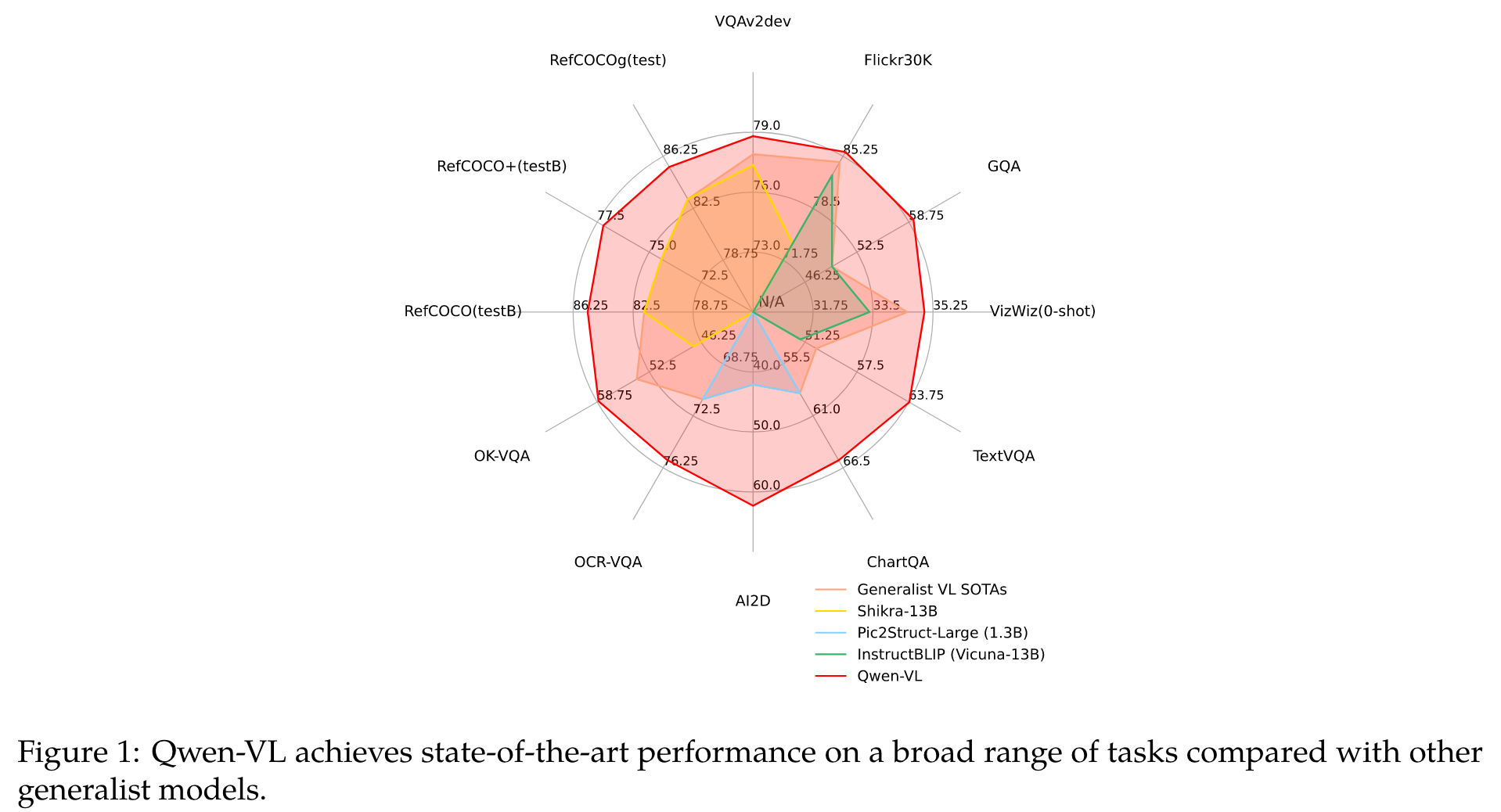
Beyond the conventional image description and question-answering, we implement the grounding and text-reading ability of Qwen-VLs by aligning image-caption-box tuples. (p. 1)
the majority of open-source LVLMs remain perceiving the image in a coarse-grained approach and lacking the ability to execute fine-grained perception such as object grounding or text reading. (p. 2)
We empower the LLM basement with visual capacity by introducing a new visual receptor including a language-aligned visual encoder and a positionaware adapter. (p. 3)
Methodology
Model Architecture
Visual Encoder
The visual encoder of Qwen-VL uses the Vision Transformer (ViT) (Dosovitskiy et al., 2021) architecture, initialized with pre-trained weights from Openclip’s ViT-bigG (Ilharco et al., 2021). During both training and inference, input images are resized to a specific resolution. The visual encoder processes images by splitting them into patches with a stride of 14, generating a set of image features. (p. 3)
Position-aware Vision-Language Adapter
To alleviate the efficiency issues arising from long image feature sequences, Qwen-VL introduces a vision-language adapter that compresses the image features. This adapter comprises a single-layer cross-attention module initialized randomly. The module uses a group of trainable vectors (Embeddings) as query vectors and the image features from the visual encoder as keys for crossattention operations. This mechanism compresses the visual feature sequence to a fixed length of 256. (p. 3)
2D absolute positional encodings are incorporated into the cross-attention mechanism’s query-key pairs to mitigate the potential loss of positional details during compression. (p. 4)

Inputs and Outputs
Image Input
Images are processed through the visual encoder and adapter, yielding fixed-length sequences of image features. To differentiate between image feature input and text feature input, two special tokens ( and </img>) are appended to the beginning and end of the image feature sequence respectively, signifying the start and end of image content. (p. 4)
Bounding Box Input and Output
To enhance the model’s capacity for fine-grained visual understanding and grounding, Qwen-VL’s training involves data in the form of region descriptions, questions, and detections. Differing from conventional tasks involving image-text descriptions or questions, this task necessitates the model’s accurate understanding and generation of region descriptions in a designated format. For any given bounding box, a normalization process is applied (within the range [0, 1000) and transformed into a specified string format: “(Xtopleft, Ytopleft), (Xbottomright, Ybottomright)”. The string is tokenized as text and does not require an additional positional vocabulary. To distinguish between detection strings and regular text strings, two special tokens (
Training
Pre-Training
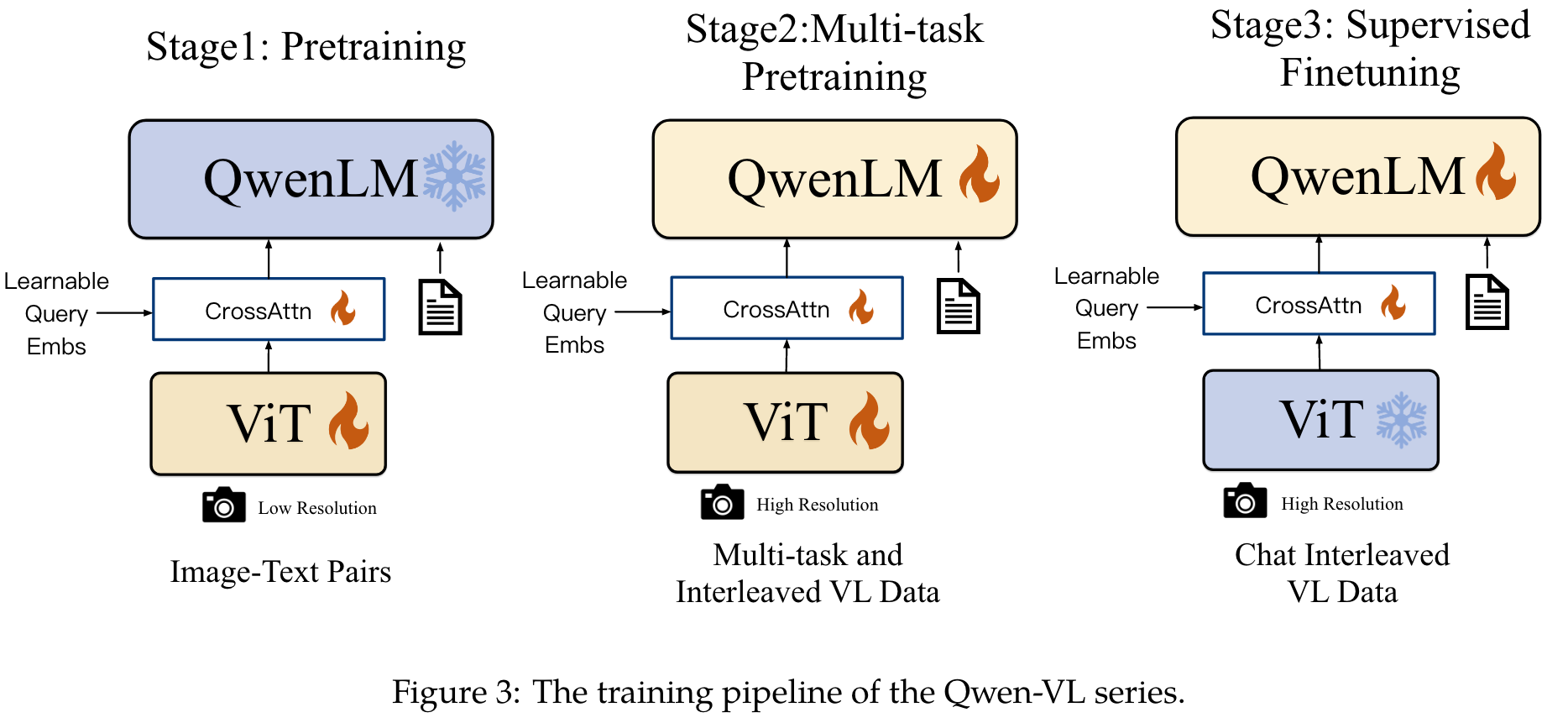
In the first stage of pre-training, we mainly utilize a large-scale, weakly labeled, web-crawled set of image-text pairs (p. 5)
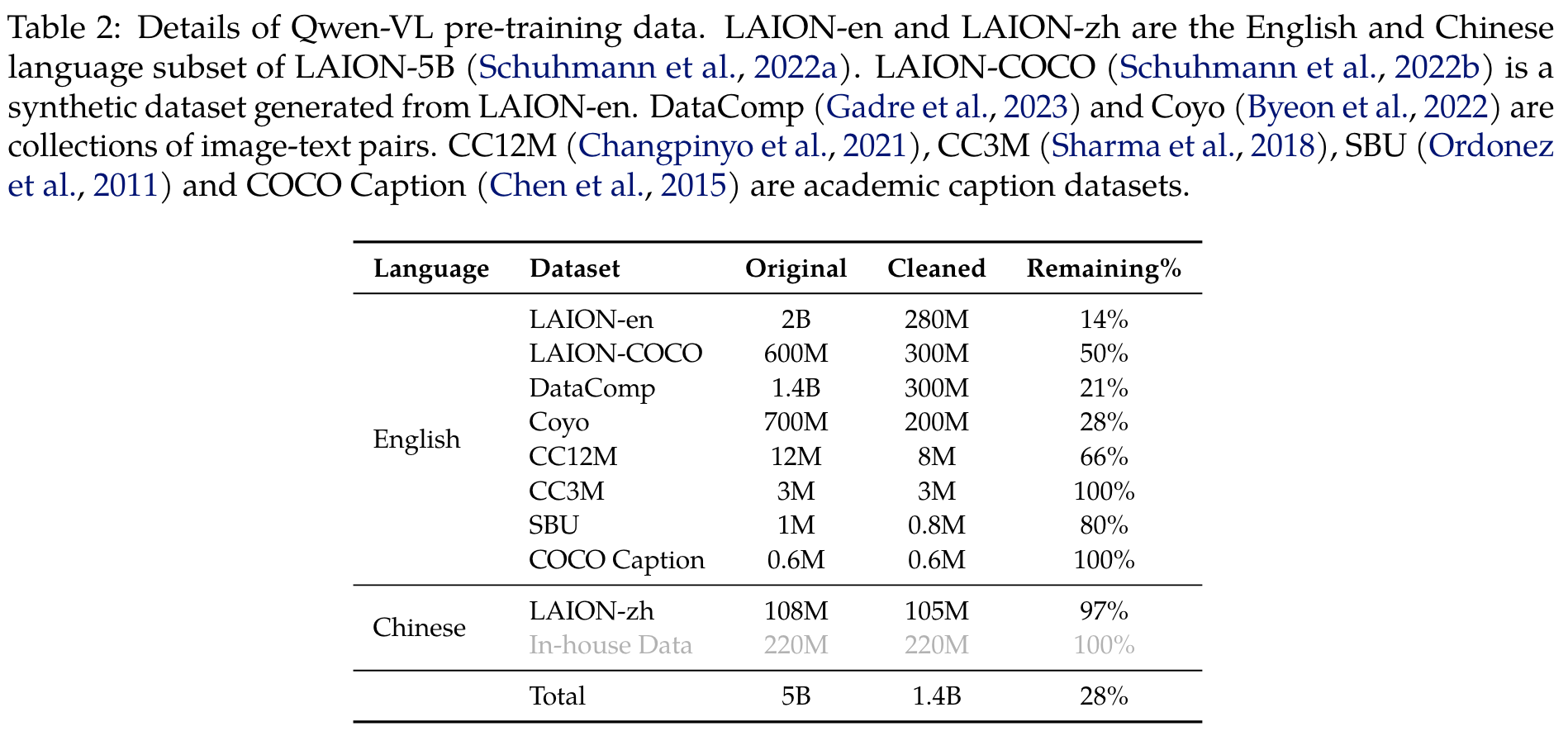
We freeze the large language model and only optimize the vision encoder and VL adapter in this stage. The input images are resized to 224 × 224. The training objective is to minimize the cross-entropy of the text tokens. The maximum learning rate is 2e−4 and the training process uses a batch size of 30720 for the image-text pairs, and the entire first stage of pre-training lasts for 50,000 steps, consuming approximately 1.5 billion image-text samples. (p. 5)
Multi-task Pre-training
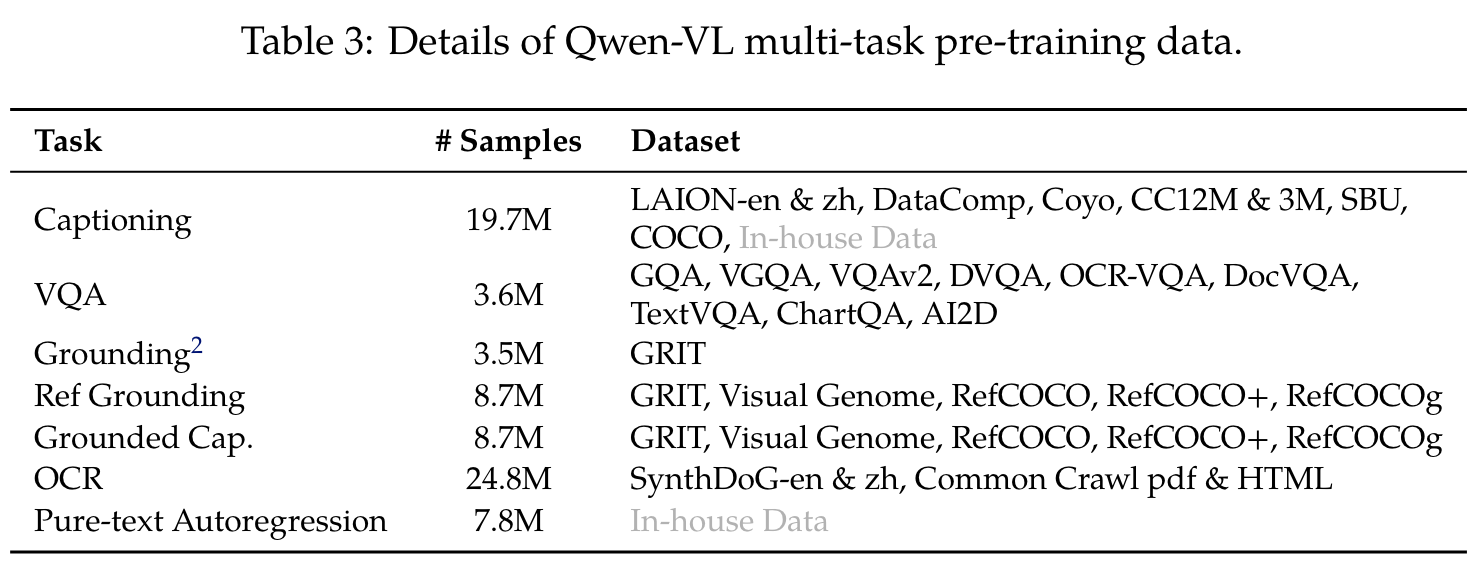
In the second stage of multi-task pre-training, we introduce high-quality and fine-grained VL annotation data with a larger input resolution and interleaved image-text data. As summarized in Table 3, we trained Qwen-VL on 7 tasks simultaneously. (p. 5)

We increase the input resolution of the visual encoder from 224 × 224 to 448 × 448, reducing the information loss caused by image down-sampling. (p. 6)
Supervised Fine-tuning
During this stage, we finetuned the Qwen-VL pre-trained model through instruction fine-tuning to enhance its instruction following and dialogue capabilities, resulting in the interactive Qwen-VL-Chat model. The multi-modal instruction tuning data primarily comes from caption data or dialogue data generated through LLM self-instruction, which often only addresses single-image dialogue and reasoning and is limited to image content comprehension. We construct an additional set of dialogue data through manual annotation, model generation, and strategy concatenation to incorporate localization and multi-image comprehension abilities into the Qwen-VL model. (p. 6)
Additionally, we mix multi-modal and pure text dialogue data during training to ensure the model’s universality in dialogue capabilities. The instruction tuning data amounts to 350k. In this stage, we freeze the visual encoder and optimize the language model and adapter module. (p. 6)
Evaluation
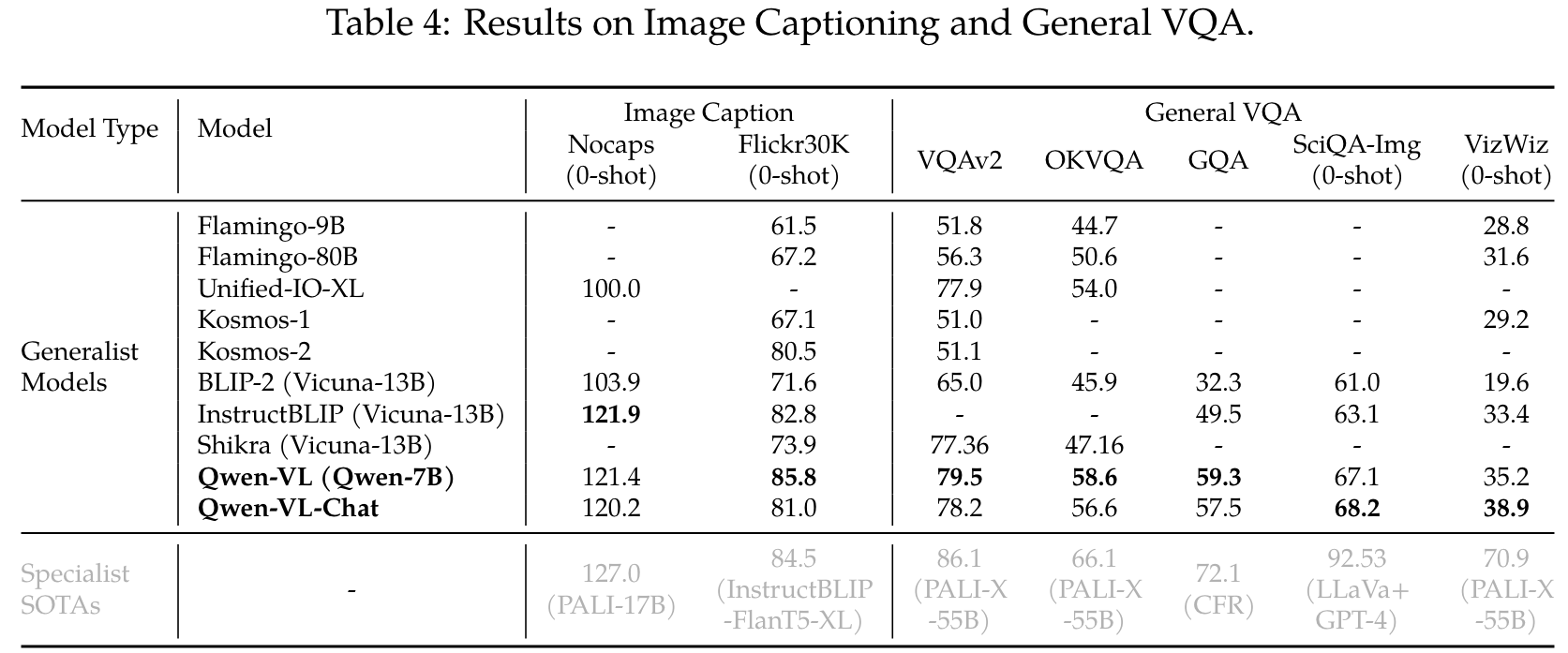
Refer Expression Comprehension
Specifically, the refer expression comprehension task requires the model to localize the target object under the guidance of a description. (p. 7)
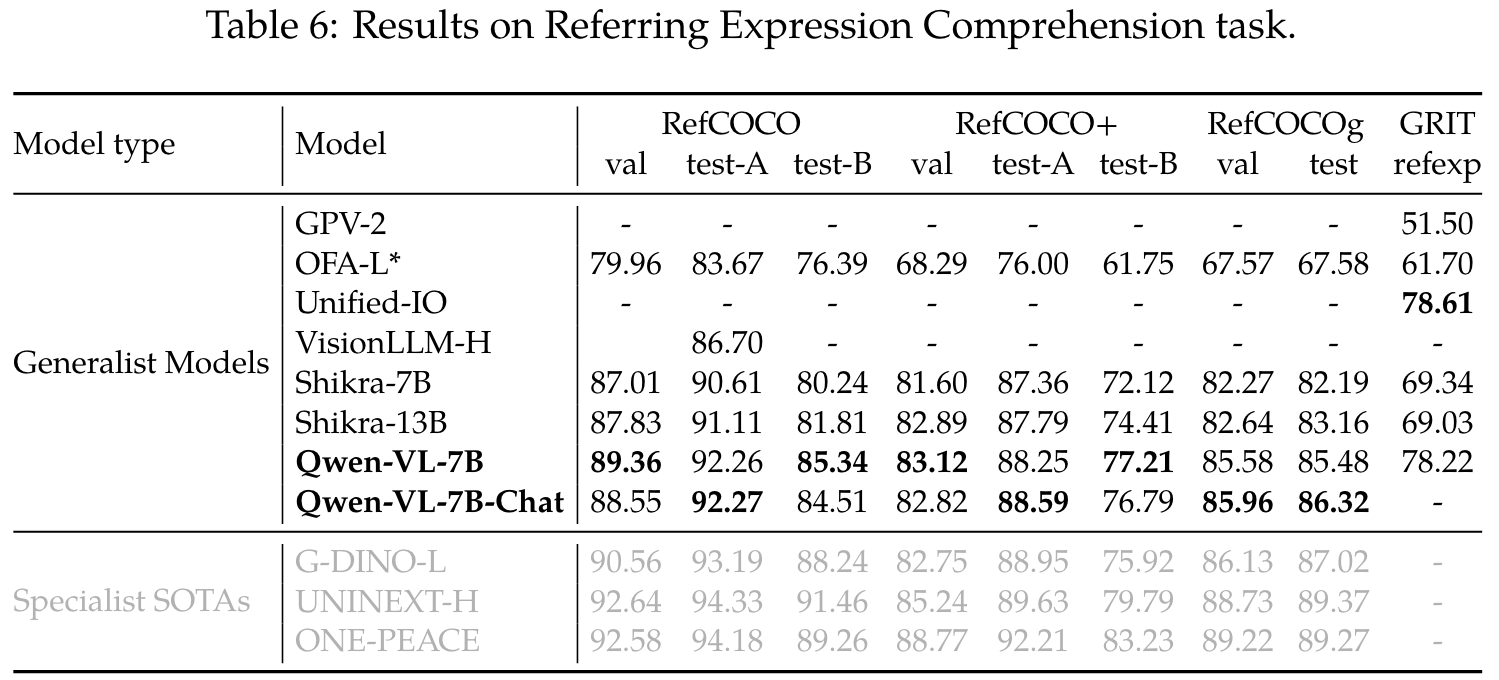
Few-shot Learning on Vision-Language Tasks
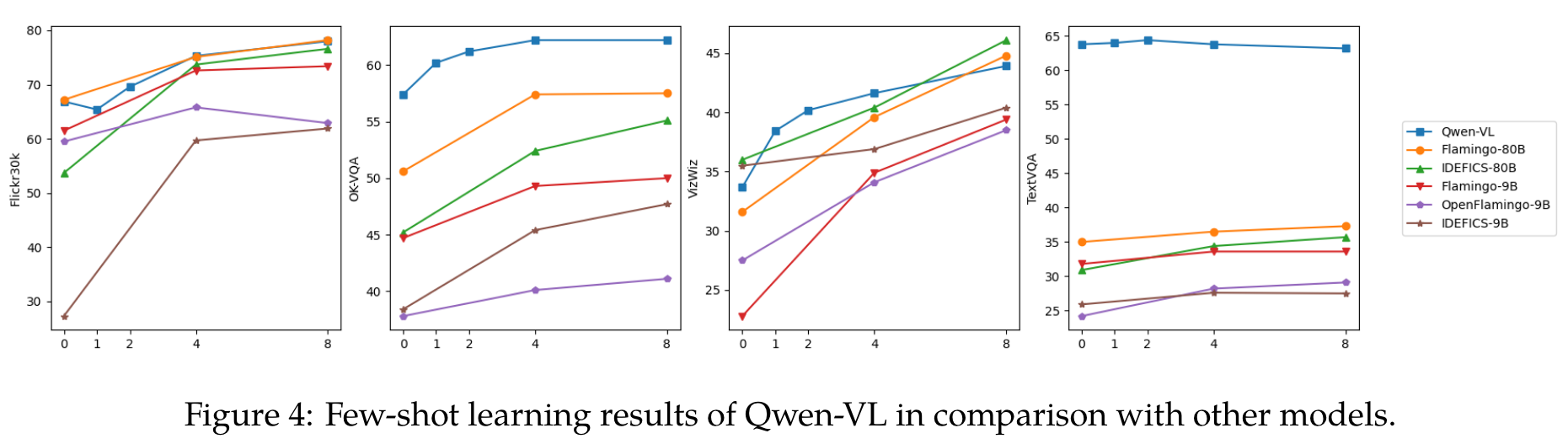
Instruction Following in Real-world User Behavior
Ablation: Window Attention vs Global Attention for Vision Transformer
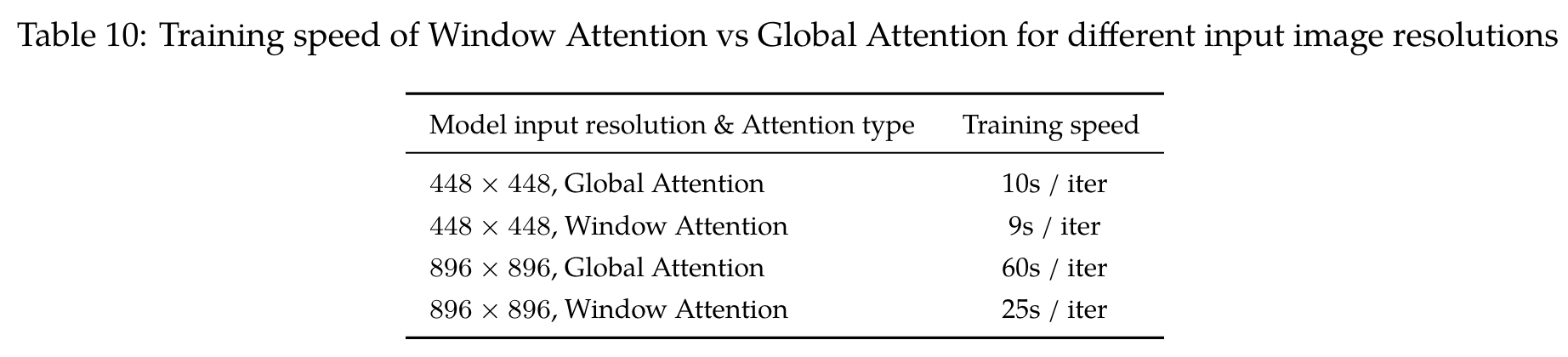
As shown in Figure 8 and Table 10, the loss of the model is significantly higher when Window Attention instead of Vanilla Attention is used. And the training speeds for both of them are similar. Therefore, we decided to use Vanilla Attention instead of Window Attention for the Vision Transformer when training Qwen-VL. (p. 22)