Video-ChatGPT Towards Detailed Video Understanding via Large Vision and Language Models
[video-chat clip multimodal llm video deep-learning video-chatgpt chatgpt transformer llava This is my reading note for ideo-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models. The paper extends chatGPT to understand the video. It’s based on LLAVA and CLIP. One of the key contribution is that is spatially and temporal pool the per frame visual feature from the clip visual encoder and finally concatenate them as features a video.

Introduction
Video-ChatGPT leverages an adapted LLM [1] that integrates the visual encoder of CLIP [6] with Vicuna [7] as a language decoder, fine-tuned on generated instructional image-text pairs. Our approach further adapts the desgin for spatiotemporal video modeling and fine-tunes the model on video-instruction data to capture temporal dynamics and frame-to-frame consistency relationships available in video data. In contrast to other concurrent works for video-based conversation [8, 9], Video-ChatGPT excels at temporal understanding, spatial consistency and contextual comprehension as demonstrated by our extensive evaluations. (p. i)
Different from VideoChat, we propose a novel human assisted and semi-automatic annotation framework for generation high quality instruction data for videos (see Sec. 4). Our simple and scalable architecture design utilizes pretrained CLIP [6] to generate spatiotemporal features which help Video-ChatGPT in generating meaningful video conversation. (p. iii)
Proposed Method
We adopt a similar approach, starting with the Language-aligned Large Vision Assistant (LLaVA)[1] as our foundation. (p. iii)
LLaVA is a LMM that integrates the visual encoder of CLIP [6] with the Vicuna language decoder [7] and is fine-tuned end-to-end on generated instructional vision-language data. We fine-tune this model using our video-instruction data, adapting it for video conversation task. (p. iii)
Architecture
We use CLIP ViT-L/14, which is pretrained using large-scale visual instruction tuning in LLaVa, as the visual encoder. However, LLaVa visual encoder is meant for images, which we modify to capture spatiotemporal representations in videos. (p. iii)
Frame-level embeddings are average-pooled along the temporal dimension to obtain a video-level temporal representation ti ∈ RN×D. This operation, referred to as temporal pooling, implicitly incorporates temporal learning through the aggregation of multiple frames. Similarly, the frame-level embeddings are average-pooled along the spatial dimension to yield the video-level spatial representation zi ∈ RT ×D. The temporal and spatial features are concatenated to obtain the video-level features vi, (p. iv)

A simple trainable linear layer g, projects these video-level features into the language decoder’s embedding space, transforming them into corresponding language embedding tokens (p. iv)
Video Instruction Tuning
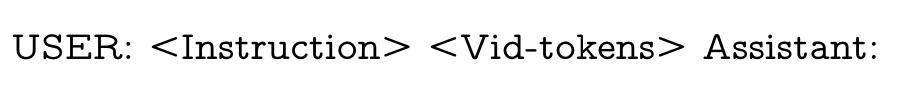
In this prompt, the Instruction represents a question pertaining to the video, randomly sampled from the training set of video-question-answer pairs. (p. iv)
The prediction answer Answer corresponds to the specific question asked. Throughout the training, the weights for both the video encoder and LLM remain frozen, and the model maximizes the likelihood of predicting tokens representing the answer by adapting the linear layer. (p. iv)
Video Instruction Data Generation
In this section, we discuss our data-focused approach, which uses both human-assisted and semi- automatic annotation methods to generate high-quality video instruction data. Our data collection involves two key methods. The human-assisted annotation, involves expert annotators analysing video content and providing detailed descriptions. This process generates data rich in context and detail, which helps our model understand complex aspects of video content. On the other hand, the semi-automatic annotation framework is more cost-effective and scalable. Leveraging state-of-the-art vision-language models, this method generates broad, high-volume annotations, thus increasing the quantity of data without compromising the quality substantially. (p. iv)

To ensure high-quality data and mitigate noise, we implement three key steps. First, we maintain a high prediction threshold for all off-the-shelf models to uphold accuracy. Second, we employ a specialized filtering mechanism that removes any frame-level caption from BLIP-2 or GRiT not matching with the Tag2Text frame-level tags. This process involves extracting words from the frame-level captions that are within the predefined Tag2Text tags vocabulary, and eliminating any captions that contain words not in the tags for a given frame. This strategy acts as an additional filtering layer, enriches the captions by integrating predictions from multiple models. In the third step, we merge frame-level captions and use the GPT-3.5 model to generate a singular, coherent video-level caption. This step augments the original ground truth caption with context from these models. (p. vi)
Experiments
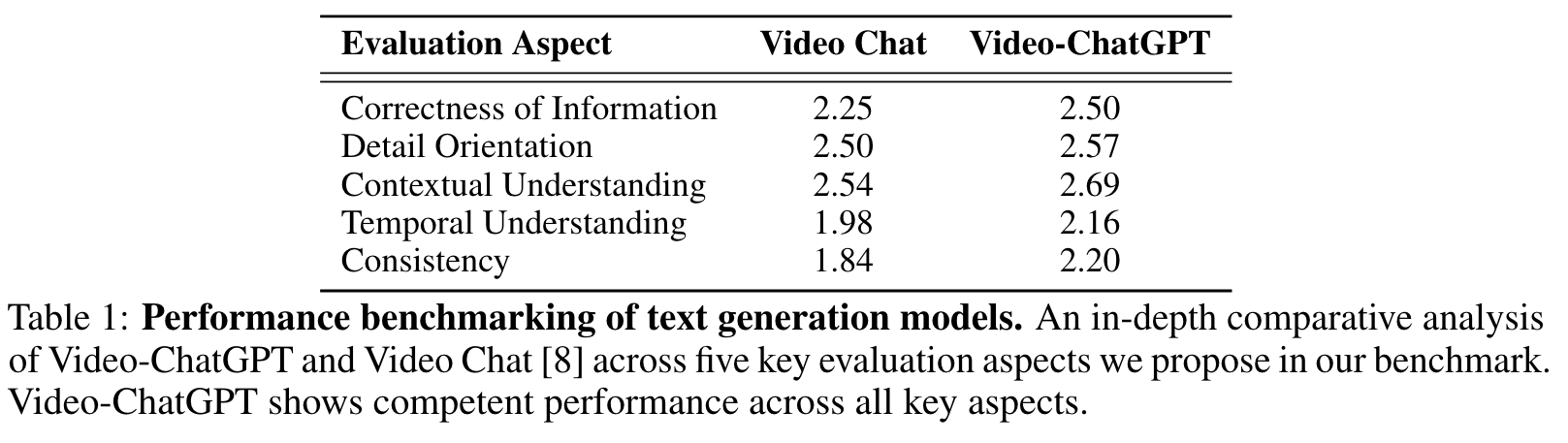
This pipeline assesses various capabilities of the model and assigns a relative score to the generated predictions on a scale of 1-5, in the following five aspects: (p. vii)
- Correctness of Information: We verify the accuracy of the generated text, ensuring it aligns with the video content and doesn’t misinterpret or misinform.
- Detail Orientation: We evaluate the depth of the model’s responses, looking for both completeness, meaning the model’s response covers all major points from the video, and specificity, denoting the inclusion of specific details rather than just generic points in the model’s response.
- Contextual Understanding: We assess the model’s understanding of the video’s context, checking if its responses aligns with the overall context of the video content.
- Temporal Understanding: We examine the model’s grasp of the temporal sequence of events in the video when answering questions.
- Consistency: We evaluate the model’s consistency across different but similar questions or different sections of the video. (p. vii)