MaMMUT A Simple Architecture for Joint Learning for MultiModal Tasks
[bert masked-language-modeling clip tubevit multimodal video coca align deep-learning constrast-loss florence transformer flava casual-masking filip focal-loss This is my reading note for MaMMUT: A Simple Architecture for Joint Learning for MultiModal Tasks. The paper proposes an efficient multi modality model. it proposes to unify generative loss (masked language modeling) and contrast loss via a two pass training process. One pass is for generate loss which utilizes casual attention model in text decoder and the other pass is bidirectional text decoding. The order of two passes are shuffled during the training.

Introduction
We propose a novel paradigm of training with a decoder-only model for multimodal tasks, which is surprisingly effective in jointly learning of these disparate vision-language tasks. This is done with a simple model, called MaMMUT. It consists of a single vision encoder and a text decoder, and is able to accommodate contrastive and generative learning by a novel two-pass approach on the text decoder Furthermore, the same architecture enables straightforward extensions to open-vocabulary object detection and videolanguage tasks (p. 1)
Large foundational vision-language models, which are designed to be extended to multiple downstream tasks, follow two main training strategies, typically exemplified by disjoint architectures. Some vision-language pre-training approaches apply a contrastive loss, in a dual-encoder style architecture, e.g. CLIP, Align, Florence (Radford et al., 2021; Jia et al., 2021; Yuan et al., 2021). Contrastive training has been shown to produce strong backbones, which lead to successful image understanding and cross-modal retrieval tasks, e.g. image-to-text or text-to-image retrieval. (p. 1)
Alternatively, the autoregressive and masked token modeling objectives, well known from language modeling, are very popular with vision-language models for text generation. They are often referred to as split-captioning objectives. The split-captioning training is typically beneficial to text-generative tasks e.g. VQA (Agrawal et al., 2015). (p. 1)
The most common architectures used in these scenarios are the encoder-decoder ones, which use a separate vision and text encoders, or a joint vision-text encoder, before a joint decoder, applying decoding losses from language learning (Cho et al., 2021; Chen et al., 2022; Piergiovanni et al., 2022a; Wang et al., 2021; 2022c). Architectures with cross-attention over frozen or partly frozen language models have also been popular (Alayrac et al., 2022). (p. 1)
We here propose a simple approach to unify contrastive learning, localization aware, and autoregressive captioning pretraining, by using a single language decoder and an image encoder. To address the challenge of reconciling the unconditional sequence-level representation learning needed for contrastive learning with the token-conditioned next-token prediction, we propose a two-pass learning strategy using the text decoder. In one pass of the training, we utilize cross attention and causal masking to learn the caption generation task, where the text features can attend to the image features and predict the tokens in sequence; in the other pass we disable the cross-attention and causal masking, which learns the contrastive task without visibility into the image features. We further modify the contrastive training objective to be localization-aware, further equipping the model for object detection tasks. (p. 2)
Related Work
Several prior works proposed approaches to combine contrastive and generative vision-language pre-training, on the premise of two-tower models and cross-attention or cross-modal masking to align the modalities (Li et al., 2021; Singh et al., 2022; Li et al., 2022a; 2023; Yu et al., 2022). ALBEF (Li et al., 2021) applies a contrastive loss to an image and text encoder models and adds a decoder for generative tasks. BLIP-2 (Li et al., 2023) leverages an off-the-shelf frozen image encoder and large language model for generative learning. Similar to ALBEF (Li et al., 2021), CoCa (Yu et al., 2022) uses a language generation rather than masked language modeling objective. Furthermore, a second decoder uses cross-attention to connect image representations with text to generate the output text. I (p. 3)
A number of video foundational models have been proposed (Zellers et al., 2021; Fu et al., 2021; Alayrac et al., 2022; Wang et al., 2022f;c; Cheng et al., 2022; Luo et al., 2020). The Flamingo model (Alayrac et al., 2022) extends a large frozen language model, with image and video inputs to deliver impressive results. VIOLET (Fu et al., 2021) uses masked language and masked-video modeling for joint video-text learning. Other approaches extend a pre-trained image-language model, adapting it to video (Wang et al., 2022b; Yan et al., 2022; Piergiovanni et al., 2023b), where a common approach is to just accumulate features from individual frames of the video. (p. 4)
Florence (Yuan et al., 2021) does an adaptation with 3D kernels to the SWIN transformer (Liu et al., 2021), and OmniVL (Wang et al., 2022c) uses the Timesformer model (Gedas Bertasius, 2021), which preserve the temporal information, however the adaptation is generally more complex. Combining contrastive and captioning losses in video is also a popular technique. For example, InternVideo (Wang et al., 2022f) proposed a combination of a masked video encoder-decoder and a cross-modal constrastive dual encoder in a video foundational model. In contrast, while we perform only a light fine-tuning over a image-language pre-trained model, our approach outperforms the above-mentioned more sophisticated and better-trained video models. (p. 4)
Proposed Method
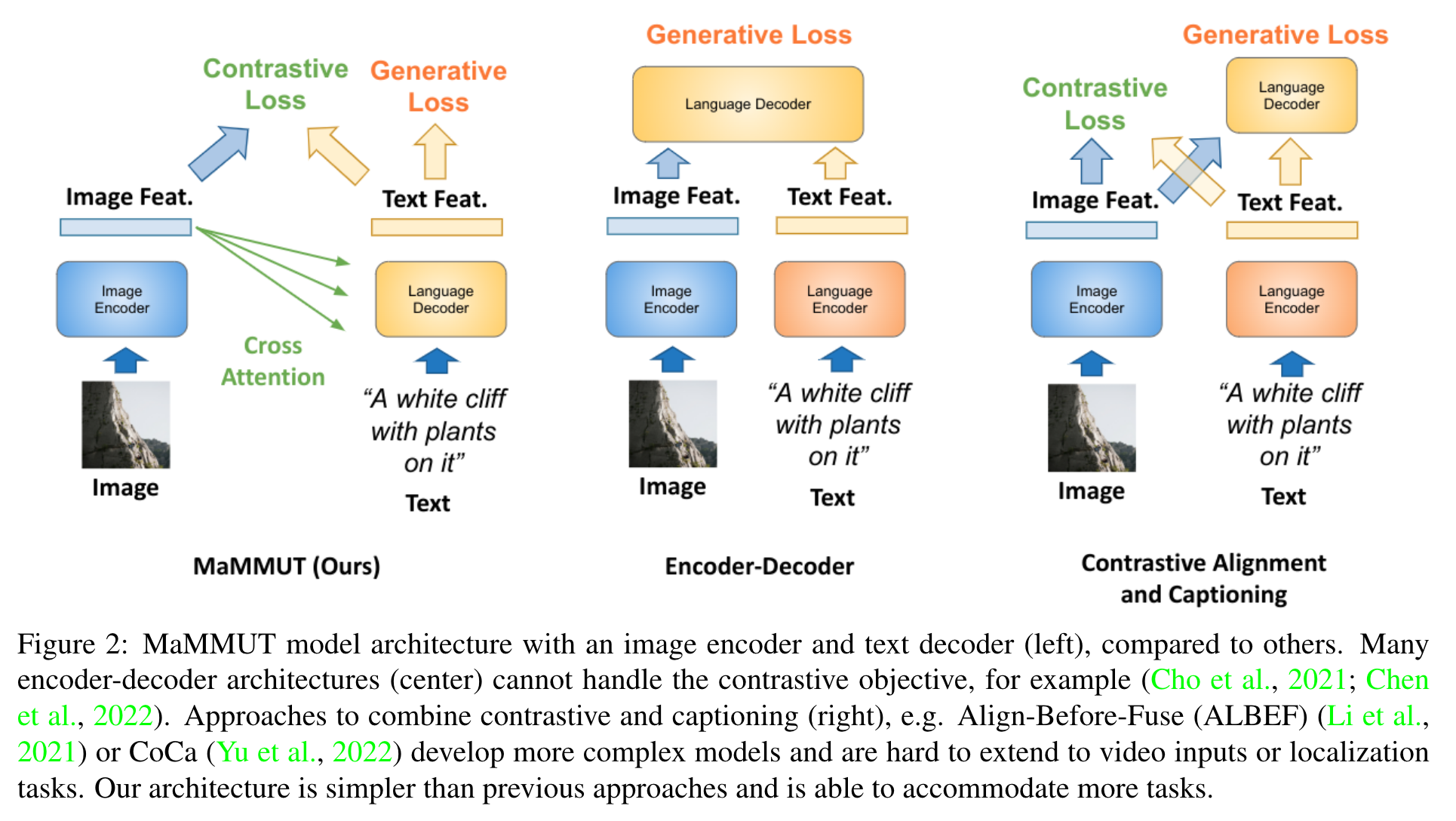
MaMMUT Architecture
MaMMUT is an intuitive and simple architecture for multimodal tasks, which consists of a single vision-encoder and a single text-decoder (see left of Figure 2). The MaMMUT architecture utilizes cross attention to fuse visual representation with text features anywhere in the decoder layers. (p. 5)
Decoder-only Two-Pass learning
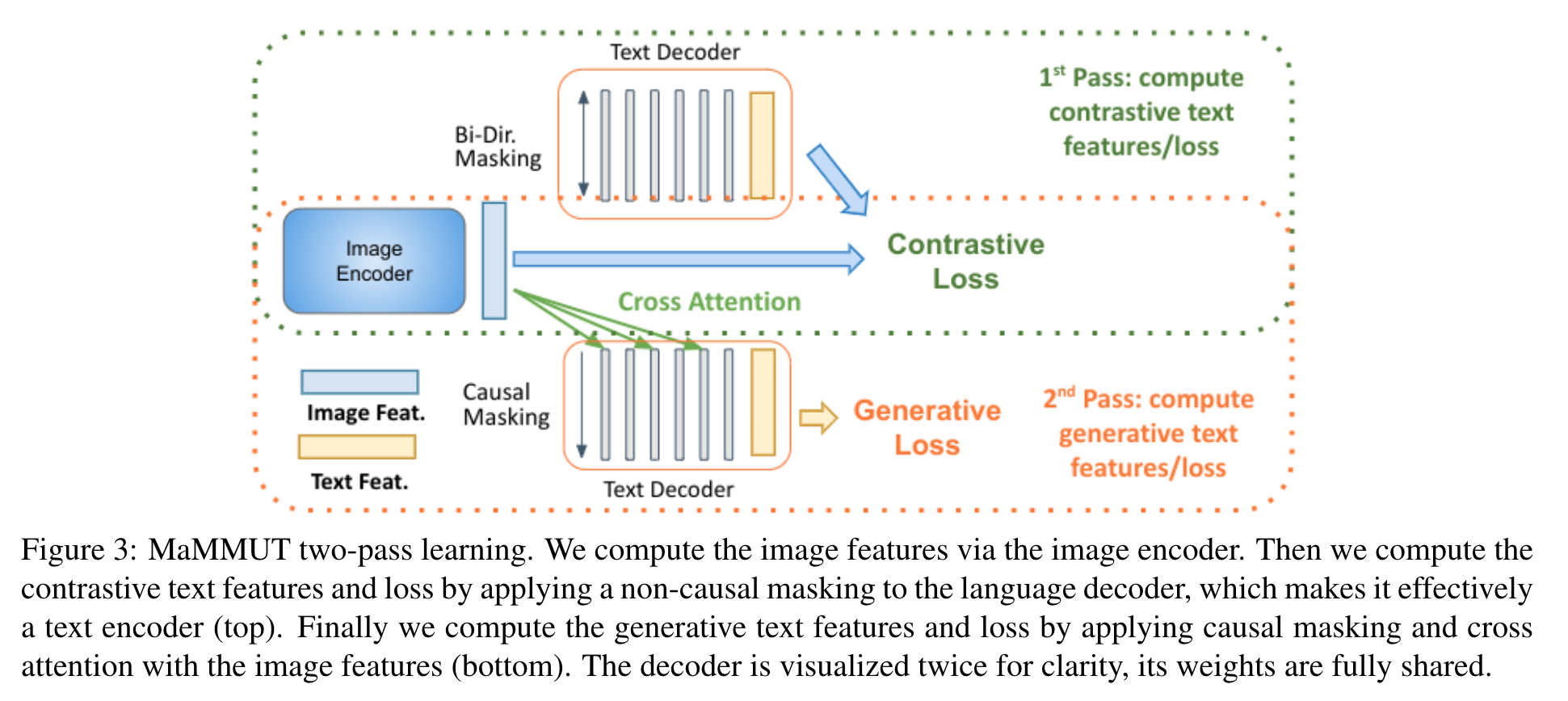
We propose a two-pass approach to jointly learn the two types of text representations by the same model. During the first pass, to learn the contrastive task, we enable bi-directional masking within the decoder. The text features should not see the image features (which characterizes dual-encoder contrastive learner), but can attend to all tokens at once to produce the sequence-level representation. On the second pass, we utilize cross attention and causal masking to learn the caption generation task. The text features can attend to the image features and predict the tokens in a sequence (see Figure 3). All text-decoder weights are shared and gradients are aggregated from the two passes during training. The two passes are done interchangeably during training so their order is not important. (p. 5)
We insert M cross-attention layers into N text decoder layers, where M ≈ N/2 . The ratio M/N represents a trade-off between model capacity and text-generative capability, where higher M tends to benefit the text-generation tasks The same decoder features are average-pooled to represent the whole sequence (li). (p. 5)
Pretraining Losses
Focal Constrast Loss
The focal loss (Lin et al., 2017) presents a compelling alternative as it allows us to finely tune the weights assigned to challenging examples, demonstrating improved performances for object classification or detection scenarios. It has been recently shown, that applying focal loss achieves very competitive performance with significantly smaller batch size for contrastive learning (Kim et al., 2023). (p. 6)
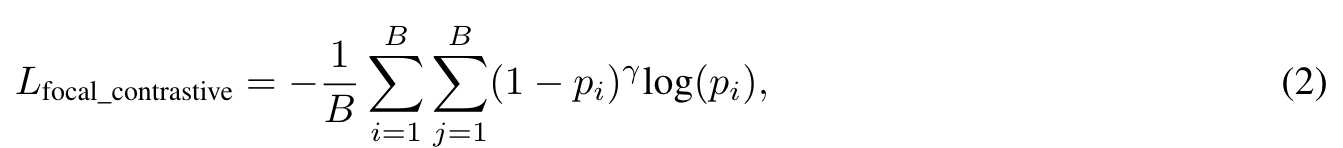
Learning from Scratch with Noisy Image-Text Supervision
MaMMUT is pretrained end-to-end from scratch, without relying on any prior training or external sources. We use only a web alt-text dataset (Jia et al., 2021) for training. As the image encoder is typically the computation bottleneck in contrastive learning (Radford et al., 2021), our pretraining approach incurs only a relatively light overhead in training efficiency over a pure contrastive learner (Radford et al., 2021) (≈ 16%). This is highly desirable as scaling up model and data size have shown consistent benefits in contrastive and captioning pretraining (Radford et al., 2021; Chen et al., 2022; Alayrac et al., 2022). (p. 7)
Learned Positional Embeddings for Localization Awarenesss
But for detection finetuning, recognition occurs at the region level, requiring the full-image positional embeddings to generalize to regions not seen during pretraining. To address this gap, we adopted the Cropped Positional Embedding (Kim et al., 2023). The idea is to up-sample the positional embeddings from the pretraining image size (e.g., 224) to the detection task image size (e.g., 1024). Then, a randomly cropped and resized region from the up-sampled positional embeddings is used as the image-level positional embedding during pretraining. This method trains the model to view each image not as a full image, but as a region crop from a larger, unknown image, which better matches the downstream use case of detection where recognition occurs at the region level instead of the image level. (p. 7)
MaMMUT for Video Tasks
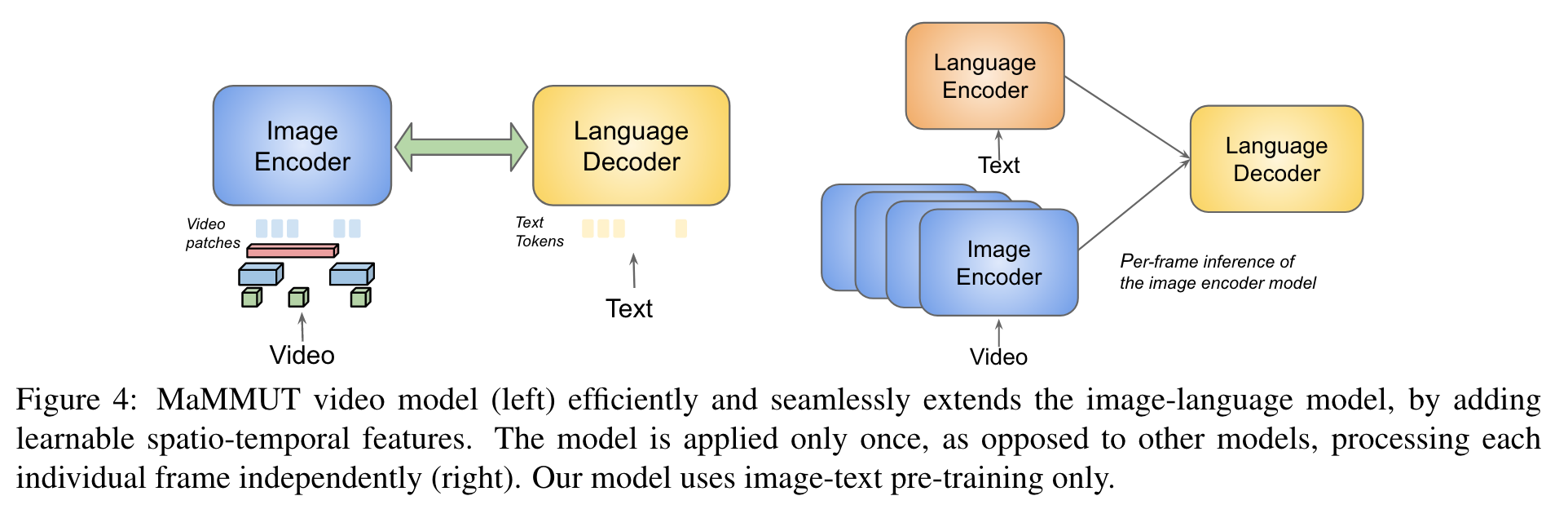
Our video model is an efficient and seamless extension to the main image-language model, based on the TubeViT idea (Piergiovanni et al., 2023a). It extracts video tubes which are then projected to patches similar to 2D image projections (Figure 4, left). (p. 8)
One main challenge is that TubeViT requires fixed position embedding, whereas this does not match well with the learned positional embeddings of the main encoder. Since the video tubes are sparse and can overlap, TubeViT found that the fixed position embeddings were important. To enable those here, we propose using both position embeddings, and adding a weighted connection to the newly added fixed embeddings. Next, we use the same 2D patches, but at a sparse temporal stride, and finally add the tube projections following the settings used in TubeViT. All these tokens are concatenated together, and passed through the shared ViT backbone (p. 8)
Experiment
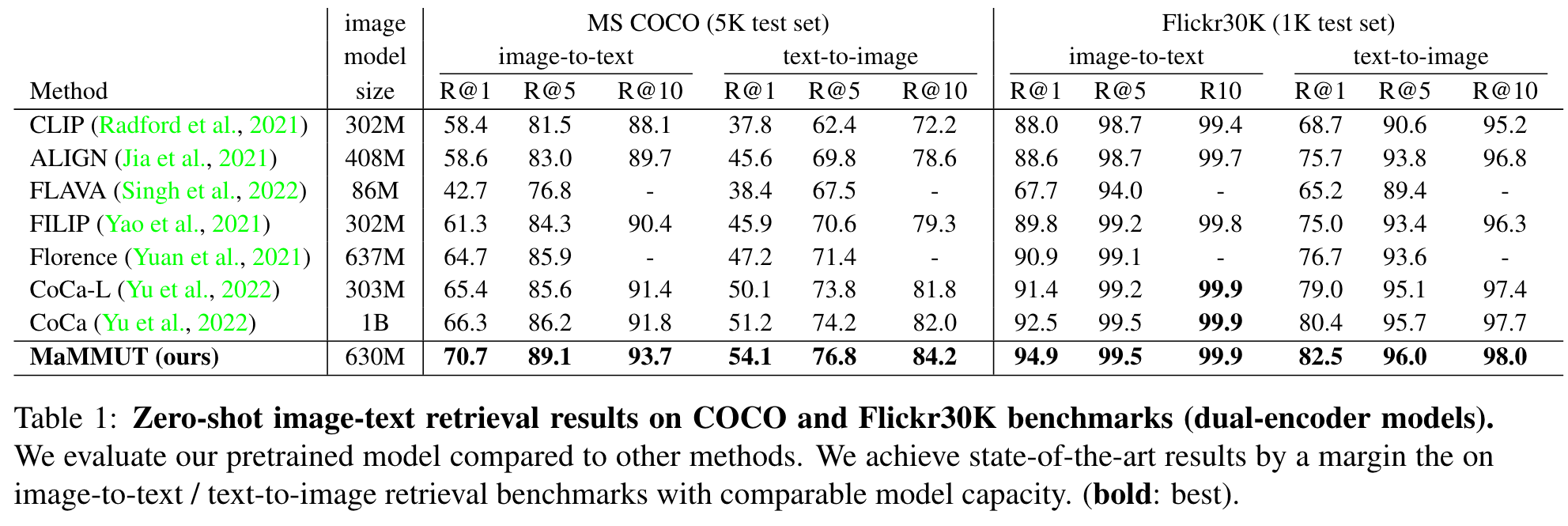
Ablation studies
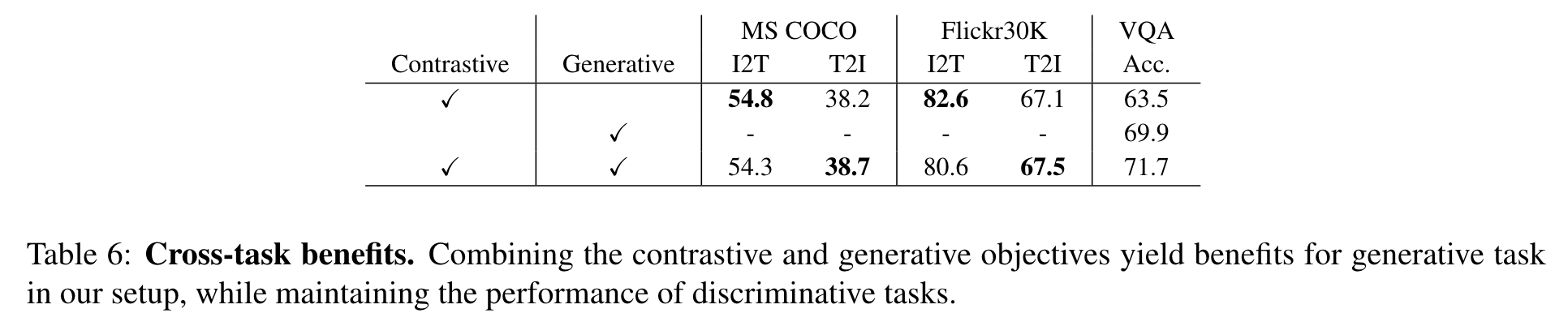
Cross-task benefits
We find that joint training is generally favorable to tasks, but it affects tasks differently (Table 6). (p. 11)
Cross-attention Design
Cross-attention provide an efficient means for communication between the two modalities. We find that tasks indeed perform better under different circumstances. Specifically, cross-attention is preferred for text generative tasks, but not as much for contrastive ones. (p. 11)

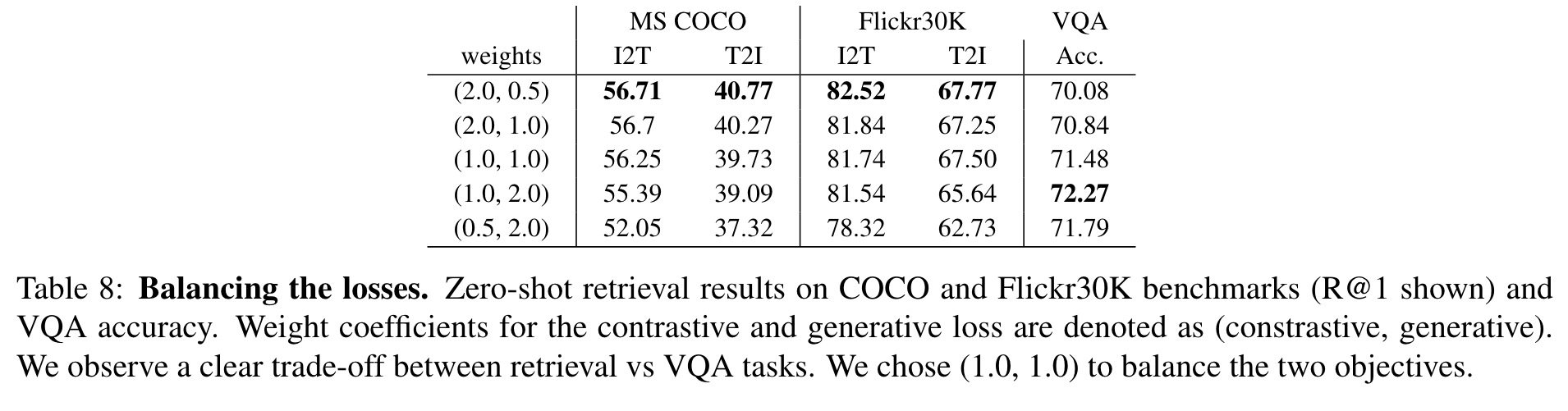
Balancing contrastive-vs-generative losses
We observe that the two objectives indeed have competitive behaviors. In the rest of the experiments, we pick equal weights over these two losses, as we observe that it gives more advantage to the VQA performance, whereas the retrieval does not suffer as much. (p. 11)
Scaling Image Encoder

We present the results of scaling image encoder in Table 9, where we confirm increasing the capacity of image encoder yields consistent improvement. (p. 12)
Video Model Ablations
We explore the effects of removing gated connections, the fixed embeddings and even the video feature inputs. As seen, their importance increases in that order, where the addition of video tubes to process the video are of highest importance. This is not surprising as they learn the spatio-temporal video information (p. 12)
