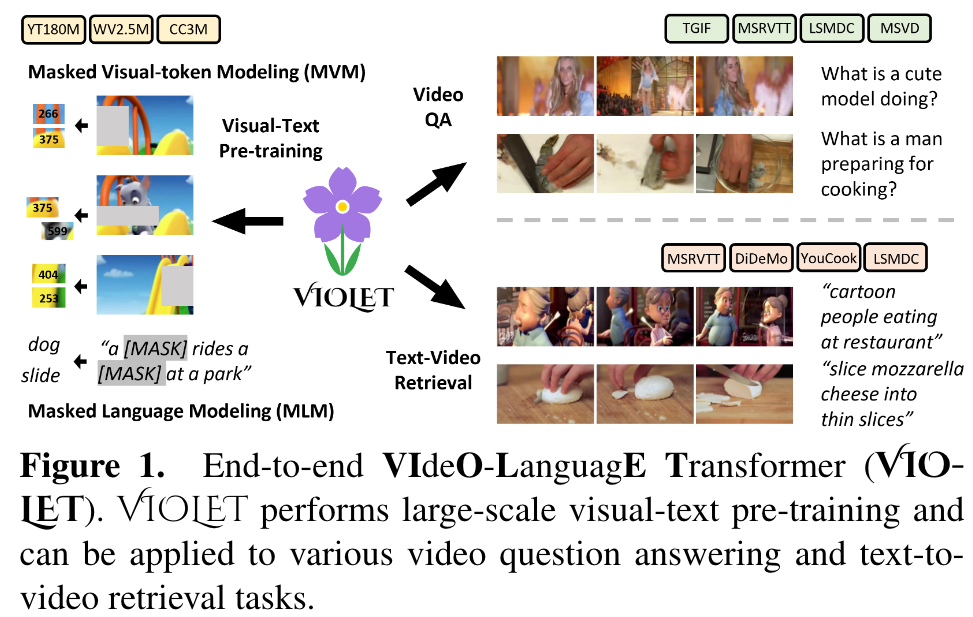
VIOLET End-to-End Video-Language Transformers with Masked Visual-token Modeling
[multimodal deep-learning video violet swin-transformer vq-vae masked-language-modeling masked-image-modeling masked-visual-token-modeling frozen clip-bert clip4clip vidoe-clip hero avlnet clip vatt This is my reading note for VIOLET : End-to-End Video-Language Transformers with Masked Visual-token Modeling. This paper proposes a method to pre-train video-text model. The paper has two major innovations 1) use video SWIN transformer to extract the temporal features; 2) uses VQVAE to extract visual tokens and apply mask recovery on the tokens.
Introduction
To make it computationally feasible, prior works tend to “imagify” video inputs, i.e., a handful of sparsely sampled frames are fed into a 2D CNN, followed by a simple mean-pooling or concatenation to obtain the overall video representations. Although achieving promising results, such simple approaches may lose temporal information that is essential for performing downstream VidL tasks. (p. 1)
we design a new pretraining task, Masked Visual-token Modeling (MVM), for better video modeling. Specifically, the original video frame patches are “tokenized” into discrete visual tokens, and the goal is to recover the original visual tokens based on the masked patches (p. 1)
However, these methods still treat video frames as static images, and rely heavily on cross-modal fusion module to capture both temporal dynamics in videos and the alignment between visual and textual elements simultaneously. (p. 1)
In terms of model architecture, instead of naive mean pooling or concatenation over a sequence of individual frame features, VIOLET contains Video Swin Transformer that models video temporal explicitly for VidL learning [21,22]. (p. 2)
By using the pre-trained discrete VAE [26] from DALLE [27], we “tokenize” the video frames into discrete visual tokens, which can be used to reconstruct the original video frames. During pre-training, we mask out some proportions of the video input along both spatial and temporal dimensions, and the model learns to recover the discrete visual tokens of these masked patches. (p. 2)
Proposed Method
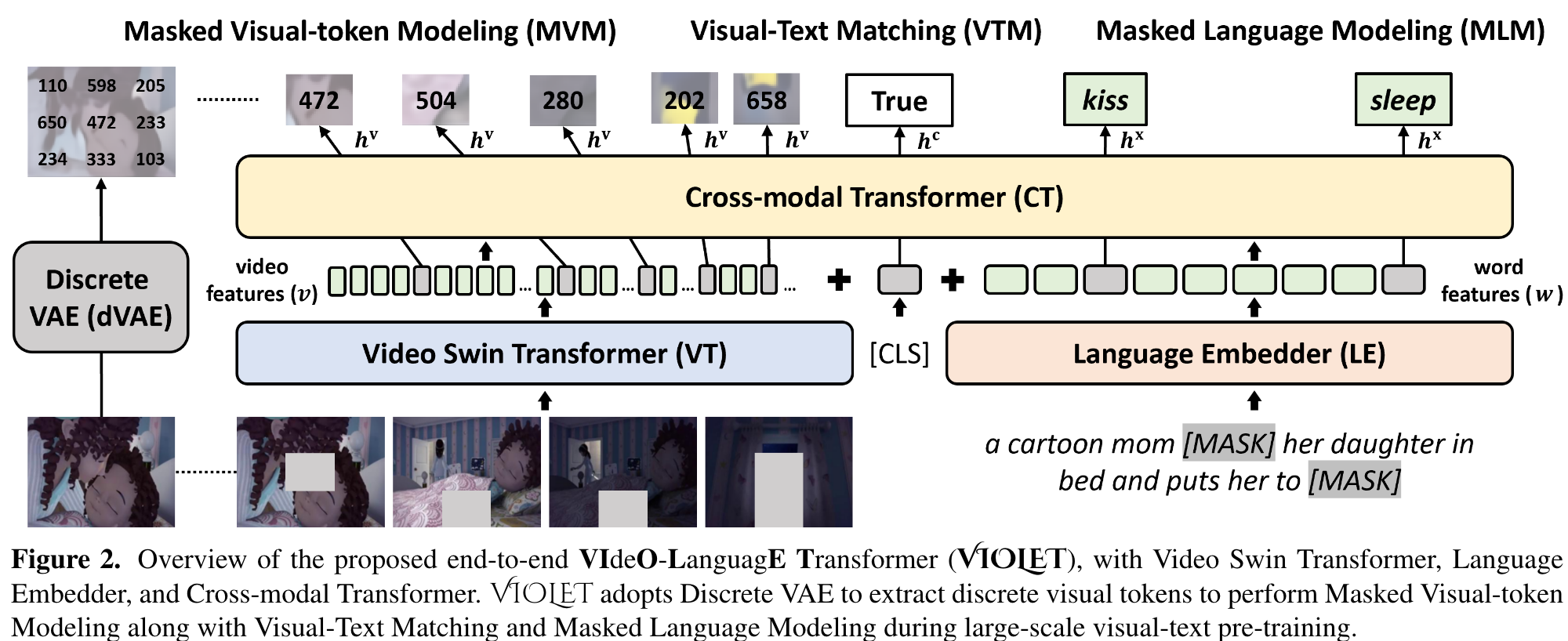
Model Architecture
Video Swin Transformer (VT)
The multi-layer 3D-shifted window [22] then considers different levels of spatial-temporal attention over these video patch embeddings. We add learnable positional embedding p^v to u, including spatial p_s ∈ R^{H×W ×d} and temporal ordering p^t ∈ R^{T ×d}, and extracts the video features v: (p. 3)
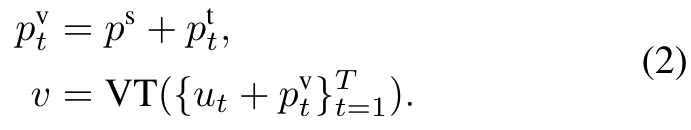
Cross-modal Transformer (CT)
We concatenate the video and text representations after position embedding as the input sequence to CT. In addition, a special [CLS] token is added to compute the global VidL representation, used in pretraining and downstream finetuning. (p. 4)
Pre-training Tasks
To benefit from large-scale data [19, 25, 74], we incorporate three pre-training tasks, including our proposed Masked Visual-token Modeling. Masked Language Modeling [5, 23, 24] predicts the masked word tokens to improve language reasoning with the aid of visual perception. Masked Visual-token Modeling recovers the masked video patches to enhance the video scene understanding. VisualText Matching [18, 24, 25] learns the alignments between video and text modality, improving the cross-modal fusion. (p. 4)
Masked Visual-token Modeling (MVM)
MVM aims at recovering the visual tokens q of those masked video patches v from the corresponding joint VidL features hv. hv is fed into a FC layer (FC^MVM) and projected to the discrete visual token space for classification (p. 4)
Masking Strategy of MLM and MVM
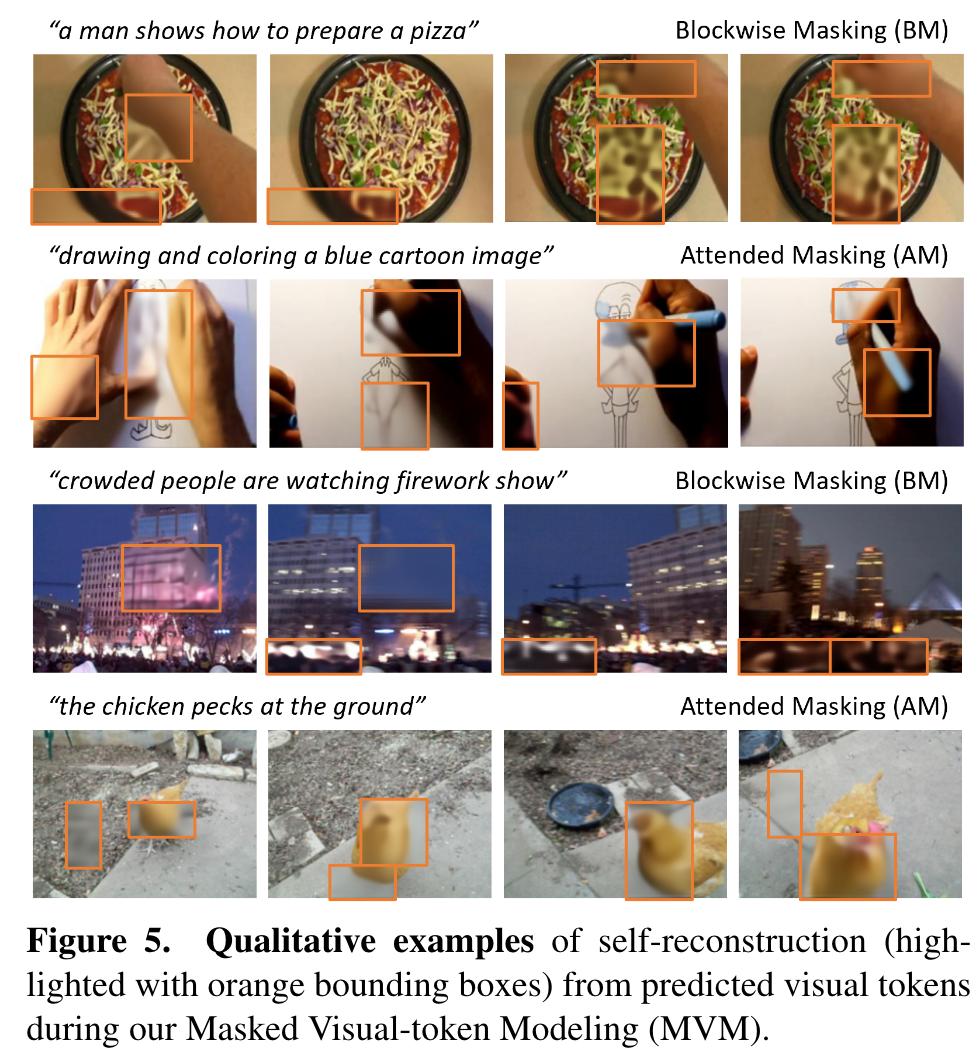
We introduce a combination of Blockwise Masking and Attended Masking to amplify the effectiveness of MLM and MVM (p. 4)

- Blockwise Masking (BM): To make MVM more challenging, we adopt Blockwise Masking [70, 71] that masks blocks of video patches along spatial-temporal dimension rather than independently masking randomly sampled patches for each frame. (p. 5)
- Attended Masking tries to put more weights on the more important elements based on the attention weights computed by Cross-modal Transformer (CT). A similar idea has been explored in [19] for MLM. In this paper, we extend AM to both visual and textual modalities. We first keep the video-text inputs intact, feed them into CT to compute the attention weights, to decide which portions in video and text are more important. We then select the top 15% of most-attended tokens to be masked in both video and text inputs to perform MVM and MLM. (p. 5)
Experiments
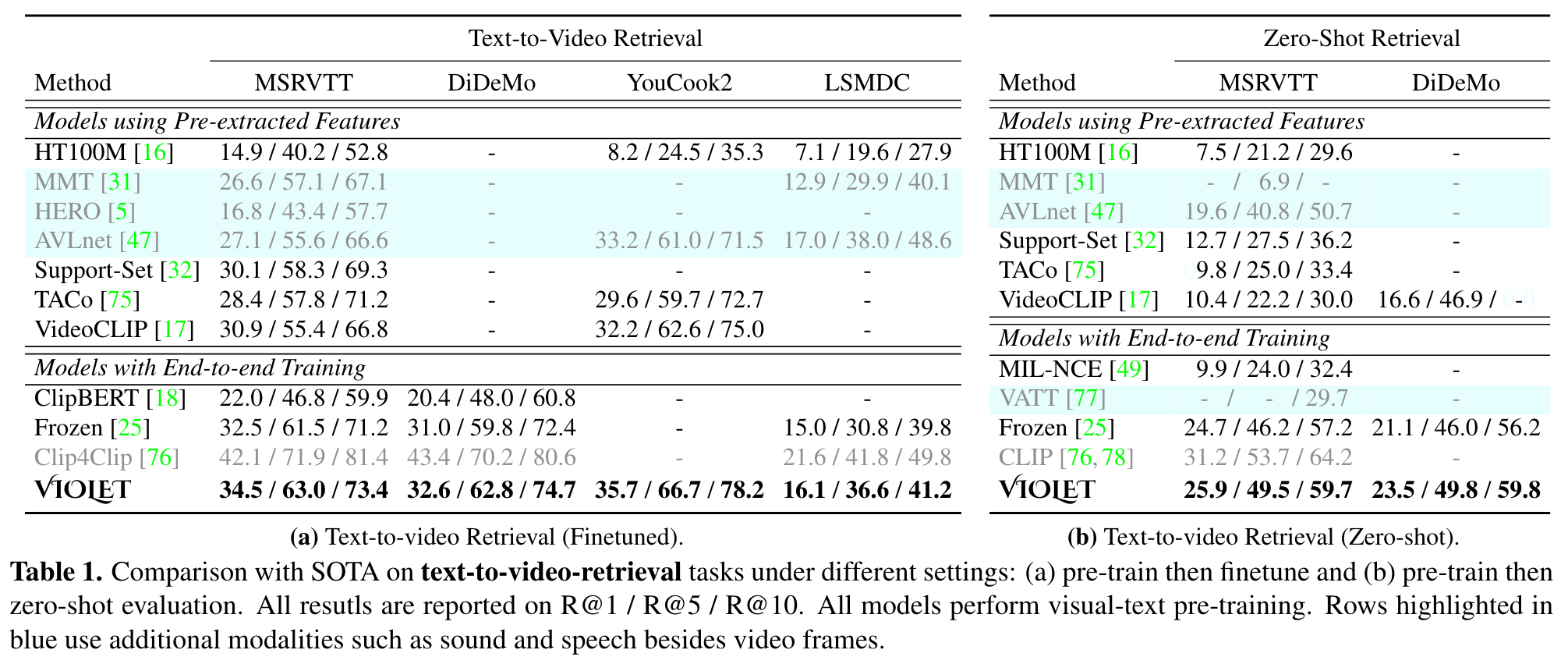
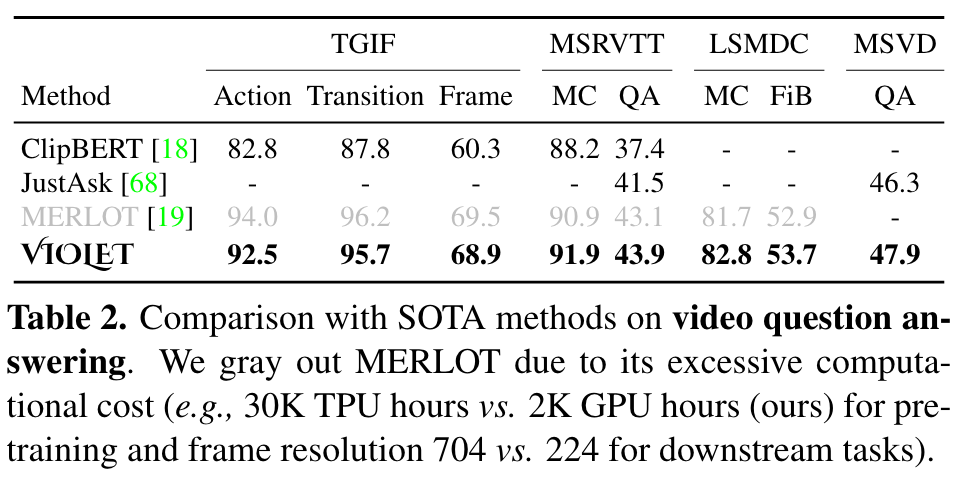
Ablation