Tag: swin-transformer
- Battle of the Backbones A Large-Scale Comparison of Pretrained Models across Computer Vision Tasks (29 Oct 2023)
This is my reading note for Battle of the Backbones: A Large-Scale Comparison of Pretrained Models across Computer Vision Tasks. This paper benchmarks different vision backbones and found that supervised ConvNext may show best performance. After it, supervised swin-transformer and clip based transformer is also very competitive. Different vision tasks shows highly correlated performance for different backbones.
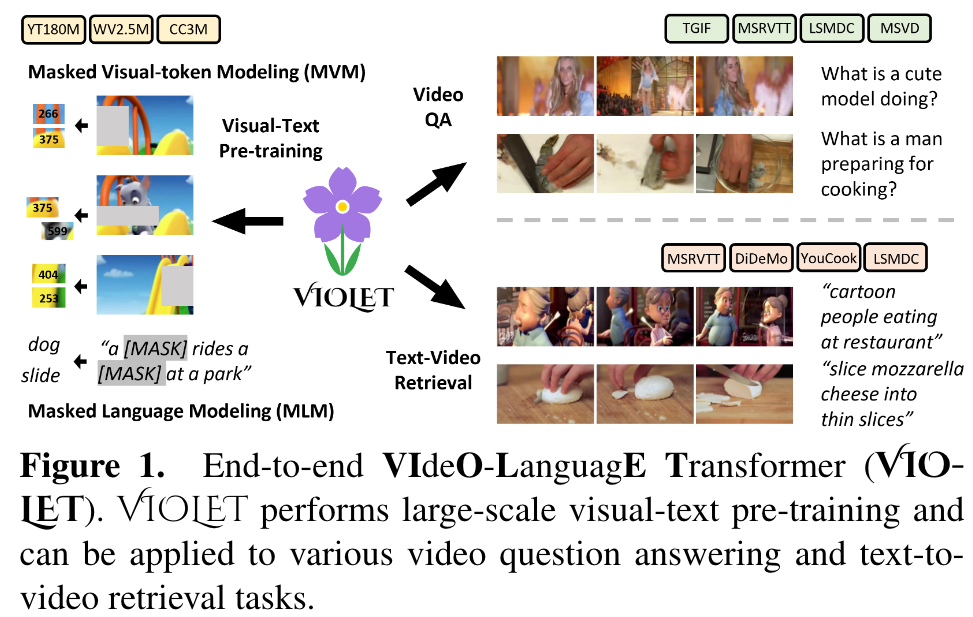
- VIOLET End-to-End Video-Language Transformers with Masked Visual-token Modeling (27 Oct 2023)
This is my reading note for VIOLET : End-to-End Video-Language Transformers with Masked Visual-token Modeling. This paper proposes a method to pre-train video-text model. The paper has two major innovations 1) use video SWIN transformer to extract the temporal features; 2) uses VQVAE to extract visual tokens and apply mask recovery on the tokens.
- Florence A New Foundation Model for Computer Vision (24 Oct 2023)
This is my reading note for Florence: A New Foundation Model for Computer Vision. This paper proposes a foundation model for vision (image/video) and text based on UniCL loss. It uses Swin-transformer and Roberta for the encoder.
- GIT A Generative Image-to-text Transformer for Vision and Language (16 Oct 2023)
This is my reading note for GIT: A Generative Image-to-text Transformer for Vision and Language. This paper proposes a image-text pre-training model. The model contains visual encoder and text decoder; the text decoder is based on self-attention, which takes concatenated text tokens and visual tokens as input.
- DiffusionDet Diffusion Model for Object Detection (06 Oct 2023)
This is my reading note for DiffusionDet: Diffusion Model for Object Detection. This paper formulates the object detection problem as a diffusion process: recover object bounding box from noisy estimation. The initial estimation could be from purely random Gaussian noise. One benefit of this method is that it could automatically handle different number of bounding boxes
- Coarse-to-Fine Vision-Language Pre-training with Fusion in the Backbone (22 Sep 2023)
This is my reading note for Coarse-to-Fine Vision-Language Pre-training with Fusion in the Backbone. This papers propose a two-stage pre-training strategy: (i) coarse-grained pre-training based on image-text data; followed by (ii) fine-grained pre-training based on image-text-box data.
- An Empirical Study of Training End-to-End Vision-and-Language Transformers (21 Sep 2023)
This is my reading note for An Empirical Study of Training End-to-End Vision-and-Language Transformers. This paper provides a good review and comparison of multi modality (video and text) model’s design choice.
- Tag2Text Guiding Vision-Language Model via Image Tagging (21 Jun 2023)
This is my reading note for Tag2Text: Guiding Vision-Language Model via Image Tagging. This paper proposes to add tag recognition to vision language model and shows improved performance.
- Swin Transformer (11 Apr 2021)
ViT provides the possibilities of using transformers along as a backbone for vision tasks. However, due to transformer conduct global self attention, where the relationships of a token and all other tokens are computed, its complexity grows exponentially with image resolution. This makes it inefficient for image segmentation or semantic segmentation task. To this end, twin transformer is proposed in Swin Transformer: Hierarchical Vision Transformer using Shifted Windows, which addresses the computation issue by conducting self attention in a local window and has multi-layers for windows at different resolution.