Tag: clip
Contrastive Language-Image Pre-Training is a machine learning technique that involves training a model to understand and relate language (text) and image data through a process of contrastive learning. This approach encourages the model to learn how to associate text and images in a meaningful way by contrasting positive pairs (correct associations) against negative pairs (incorrect associations). During training, the model learns to embed both text and image data in a shared space, making it capable of performing tasks that require connecting and understanding text and images together, such as image captioning or visual question-answering. This technique has shown promise in bridging the gap between textual and visual information, facilitating applications in computer vision and natural language understanding.- Inject Semantic Concepts into Image Tagging for Open-Set Recognition (16 Nov 2023)
This is my reading note for Inject Semantic Concepts into Image Tagging for Open-Set Recognition. This paper proposes an image tagging method based on CLIP. The major innovation is the introduction of image tag alignment loss which aligns image feature to the tag description feature. The tag descriptor is generated by LLM to describe the tog in a few sentences
- SAM-CLIP Merging Vision Foundation Models towards Semantic and Spatial Understanding (15 Nov 2023)
This is my reading note for SAM-CLIP: Merging Vision Foundation Models towards Semantic and Spatial Understanding. This paper proposes a method to combine clip and Sam to perform zero shot semantic segmentation. To combined model merges the vision encoder of Sam and clip, but freezes the other encoders and heads. To avoid catastrophe forgetting, The paper uses two stage method, in first stage, only CLIP’S head is fine tuned; in second stage, the shared vision encode and two heads are fine tuned in a multi task way.
- mPLUG-Owl2 Revolutionizing Multi-modal Large Language Model with Modality Collaboration (11 Nov 2023)
This is my reading note for mPLUG-Owl2: Revolutionizing Multi-modal Large Language Model with Modality Collaboration. This paper proposes a method to unify visual and text data for multi modal model. To this end, it uses QFormer to extract visual information and concatenate to text and feed to LLM. However, it separates the projection layer and layer norm for visual and text. This paper is similar to COGVLM.
- CogVLM Visual Expert for Pretrained Language Models (10 Nov 2023)
This is my reading note for CogVLM: Visual Expert for Pretrained Language Models. This paper proposes a vision language model similarly to mPLUG-OWL2. To avoid impacting the performance of LLM, it proposes a visual adapter which adds visual specific projection layer to each attention and feed forward layer.
- CoVLM Composing Visual Entities and Relationships in Large Language Models Via Communicative Decoding (07 Nov 2023)
This is my reading note for CoVLM: Composing Visual Entities and Relationships in Large Language Models Via Communicative Decoding. This paper proposes a vision language model to improve the capabilities of modeling composition relationship of objects across visual and text. To do that, it interleaves between language model generating special tokens and vision object detector detecting objects from image.
- The effectiveness of MAE pre-pretraining for billion-scale pretraining (05 Nov 2023)
This is my reading note for The effectiveness of MAE pre-pretraining for billion-scale pretraining. This paper proposes a pre-pretraining method: starts with MAE and then hashtag based week supervised learning. It shows improvement on over 10 vision tasks and scales by model size as well as dataset size.
- TiC-CLIP Continual Training of CLIP Models (02 Nov 2023)
This is my reading note for TiC-CLIP: Continual Training of CLIP Models. This paper studies the problem of how a model performs as the dataset evolve over time. It then proposes the best solutions base on benchmark, which is fine tuned the existing model on the whole dataset, include both new and old data.
- Battle of the Backbones A Large-Scale Comparison of Pretrained Models across Computer Vision Tasks (29 Oct 2023)
This is my reading note for Battle of the Backbones: A Large-Scale Comparison of Pretrained Models across Computer Vision Tasks. This paper benchmarks different vision backbones and found that supervised ConvNext may show best performance. After it, supervised swin-transformer and clip based transformer is also very competitive. Different vision tasks shows highly correlated performance for different backbones.
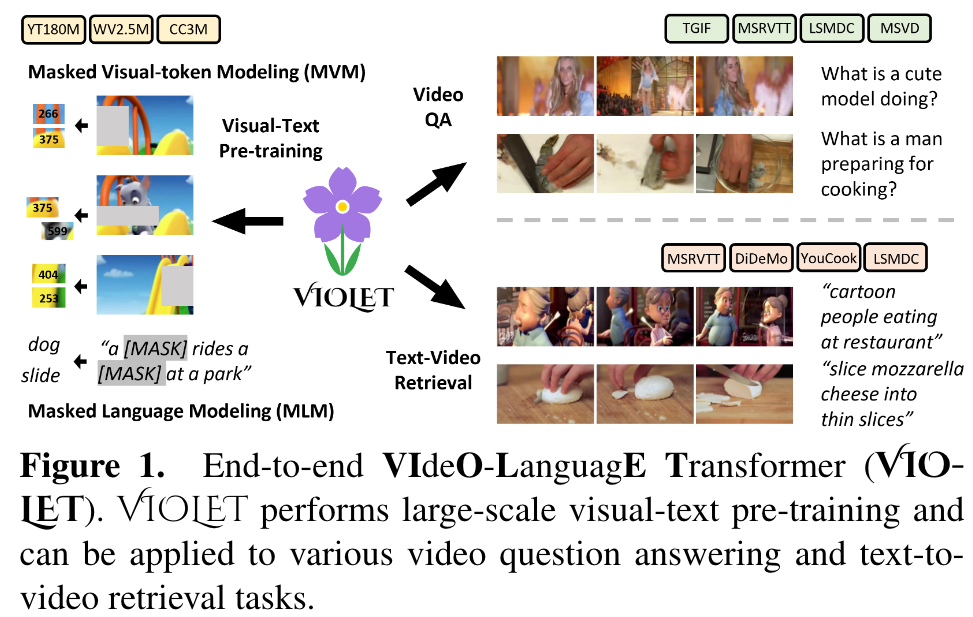
- VIOLET End-to-End Video-Language Transformers with Masked Visual-token Modeling (27 Oct 2023)
This is my reading note for VIOLET : End-to-End Video-Language Transformers with Masked Visual-token Modeling. This paper proposes a method to pre-train video-text model. The paper has two major innovations 1) use video SWIN transformer to extract the temporal features; 2) uses VQVAE to extract visual tokens and apply mask recovery on the tokens.
- Flamingo a Visual Language Model for Few-Shot Learning (26 Oct 2023)
This is my reading note for Flamingo: a Visual Language Model for Few-Shot Learning. This paper proposes to formulate vision language model vs text prediction task given existing text and visual. The model utilizes frozen visual encoder and LLM, and only fine tune the visual adapter (perceiver). The ablation study strongly against fine tune/retrain those components.
- Florence A New Foundation Model for Computer Vision (24 Oct 2023)
This is my reading note for Florence: A New Foundation Model for Computer Vision. This paper proposes a foundation model for vision (image/video) and text based on UniCL loss. It uses Swin-transformer and Roberta for the encoder.
- Unified Contrastive Learning in Image-Text-Label Space (23 Oct 2023)
This is my reading note for Unified Contrastive Learning in Image-Text-Label Space. This paper proposes to combine label in image-text contrast loss. It treats the image or text from the same labels are from the same class and thus is required to have higher similarity; in contrast loss of CLIP, image/text is required to be similar if they are from the same pair.
- OmniVL One Foundation Model for Image-Language and Video-Language Tasks (22 Oct 2023)
This is my reading note for OmniVL:One Foundation Model for Image-Language and Video-Language Tasks. The paper proposes a vision language pre-training method optimized to linear probe for classification problem. To this end, it modifies the contrast loss by creating positive. samples from the images of same label class.
- Filtering, Distillation, and Hard Negatives for Vision-Language Pre-Training (19 Oct 2023)
This is my reading note for Filtering, Distillation, and Hard Negatives for Vision-Language Pre-Training. This paper proposes several methods to improve image-text model pre-training: 1) filtering the dataset according complexity, action and text spotting (CAT); 2) concept distillation (object category and attributes); 3) hard negative mining for contrast pairs.
- GIT A Generative Image-to-text Transformer for Vision and Language (16 Oct 2023)
This is my reading note for GIT: A Generative Image-to-text Transformer for Vision and Language. This paper proposes a image-text pre-training model. The model contains visual encoder and text decoder; the text decoder is based on self-attention, which takes concatenated text tokens and visual tokens as input.
- Align before Fuse Vision and Language Representation Learning with Momentum Distillation (11 Oct 2023)
This is my reading note for Align before Fuse: Vision and Language Representation Learning with Momentum Distillation. The paper proposes a multi modality model which is trained base on contrast loss, mask language modeling and image-text match. To handle noisy pairs of text and image, it track moving average of model and distill to the final model.
- Leveraging Unpaired Data for Vision-Language Generative Models via Cycle Consistency (04 Oct 2023)
This is my reading note for Leveraging Unpaired Data for Vision-Language Generative Models via Cycle Consistency. The papers proposes a method to train a multi modality model between text and image. Especially, the paper propose cycle consistency loss to leverage unpaired text and image: use image to generate text and use text to recover image and vice verse. It reminds me cycle-GAN paper.
- DeepSpeed-VisualChat Multi-Round Multi-Image Interleave Chat via Multi-Modal Causal Attention (01 Oct 2023)
This is my reading note for DeepSpeed-VisualChat: Multi-Round Multi-Image Interleave Chat via Multi-Modal Causal Attention. This paper proposes a method for multi round multi-image multi modality model. The paper utilizes a frozen LLM and visual encoder. The contribution of the paper includes: 1. Casual cross attention method to combine image and multiround text; 2. A new dataset.
- Demystifying CLIP Data (30 Sep 2023)
This is my reading note for Demystifying CLIP Data. This paper reverse engineered the data of CLIP and replicated even outperformed the CLIP.
- Vision Transformers Need Registers (29 Sep 2023)
This is my reading note for Vision Transformers Need Registers. This paper analyzes the attention map of transformer and find too large scale transformer and trained after a long iteration, some token show exceptionally high norm. Those tokens usually correspond to patches in uniform background. Analysis indicates that those tokens are used to store global information. Thus at would heart dense prediction tasks like image segmentation. To tackle this, the paper proposes add additional tokens during trains and inference, but rejecting for outputs.
- Video-ChatGPT Towards Detailed Video Understanding via Large Vision and Language Models (26 Sep 2023)
This is my reading note for ideo-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models. The paper extends chatGPT to understand the video. It’s based on LLAVA and CLIP. One of the key contribution is that is spatially and temporal pool the per frame visual feature from the clip visual encoder and finally concatenate them as features a video.
- MaMMUT A Simple Architecture for Joint Learning for MultiModal Tasks (24 Sep 2023)
This is my reading note for MaMMUT: A Simple Architecture for Joint Learning for MultiModal Tasks. The paper proposes an efficient multi modality model. it proposes to unify generative loss (masked language modeling) and contrast loss via a two pass training process. One pass is for generate loss which utilizes casual attention model in text decoder and the other pass is bidirectional text decoding. The order of two passes are shuffled during the training.
- Coarse-to-Fine Vision-Language Pre-training with Fusion in the Backbone (22 Sep 2023)
This is my reading note for Coarse-to-Fine Vision-Language Pre-training with Fusion in the Backbone. This papers propose a two-stage pre-training strategy: (i) coarse-grained pre-training based on image-text data; followed by (ii) fine-grained pre-training based on image-text-box data.
- An Empirical Study of Training End-to-End Vision-and-Language Transformers (21 Sep 2023)
This is my reading note for An Empirical Study of Training End-to-End Vision-and-Language Transformers. This paper provides a good review and comparison of multi modality (video and text) model’s design choice.
- Multimodal Learning with Transformers A Survey (02 Sep 2023)
This is my reading note on Multimodal Learning with Transformers A Survey. This a paper provides a very nice overview of the transformer based multimodality learning techniques.
- BLIP-Diffusion Pre-trained Subject Representation for Controllable Text-to-Image Generation and Editing (21 Aug 2023)
This is my reading note for BLIP-Diffusion: Pre-trained Subject Representation for Controllable Text-to-Image Generation and Editing. The paper proposes a method for generating an image with text prompt and target visual concept. To do that the paper trained blip model to align visual features with text prompt and then concatenate the visual embedding to the text prompt to generate the need. Code and models will be released at https://github.com/salesforce/LAVIS/tree/main/projects/blip-diffusion. Project page at https://dxli94.github.io/BLIP-Diffusion-website/.
- Visual Instruction Tuning (02 Aug 2023)
This is my reading note for Visual Instruction Tuning. The paper exposes a method to train a multi-modality model - that woks like chat GPT. This is achieved by building an instruction following dataset that’s paired with images. The model is then trained on this dataset.
- CoCa Contrastive Captioners are Image-Text Foundation Models (31 Jul 2023)
This is my reading note for CoCa: Contrastive Captioners are Image-Text Foundation Models. The paper proposes a multi modality model, especially it models the problem as image caption as well as text alignment problem. The model contains three component: a vision encoder, a text decoder (which generates text embedding ) and a multi modality decoder , which generate caption given image and text embedding.
- FLAVA A Foundational Language And Vision Alignment Model (30 Jul 2023)
This is my reading note for FLAVA: A Foundational Language And Vision Alignment Model. This paper proposes a multi modality model. Especially, the model not only work across modality, but also on each modality and joint modality. To do that, it contains loss functions for both within modality but also across modality. It also proposes to use the same architecture for vision encoder, Text encoder as well as multi -modality encoder.
- AutoCLIP Auto-tuning Zero-Shot Classifiers for Vision-Language Models (29 Jul 2023)
This is my reading note for AutoCLIP: Auto-tuning Zero-Shot Classifiers for Vision-Language Models. This paper proposes a method to use clip for zero shot image classification, to do that, it first generates several prompt to convert class label to text embedding by average. Then the image is processed by visual encoder. The label of image is the one has slowest distance between label embody and image embedding. This paper propose to use soft Max instead of average for label embedding.
- Subject-Diffusion Open Domain Personalized Text-to-Image Generation without Test-time Fine-tuning (26 Jul 2023)
This is my reading note for Subject-Diffusion:Open Domain Personalized Text-to-Image Generation without Test-time Fine-tuning. This paper propose a diffusion method to generate images with given visual concepts and text prompt. Especially the paper is able to hand multiple visual concert jointly. To handle that, the paper detect the visual concepts from the input images, then the segmented images and bounding box are encoded feed into latent diffusion model. To enhance the consistency, the visual embedding is inserted into the text encode of the prompt.
- Make-An-Audio Text-To-Audio Generation with Prompt-Enhanced Diffusion Models (23 Jul 2023)
This is my reading note for Make-An-Audio: Text-To-Audio Generation with Prompt-Enhanced Diffusion Models. This paper proposes a diffusion model for audio, which uses an auto encoder to convert audio signal to a spectrum which could be natively handled by latent diffusion method.
- Qwen-VL A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond (09 Jul 2023)
This is my reading note for Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond. This paper proposes a vision-language model capable of vision grounding and image text reading. To do that, it considers visual grounding and OCR tasks in pre-training. In architecture, the paper uses Qformer from BLIP2.
- X-CLIP End-to-End Multi-grained Contrastive Learning for Video-Text Retrieval (04 Jul 2023)
This is my reading note for X-CLIP: End-to-End Multi-grained Contrastive Learning for Video-Text Retrieval. This paper proposes a method on extending clip to video data. it mostly studied how to aggregate the similarity score from the frame level to video level.
- DALL-E, DALL-E2 and StoryDALL-E (30 Sep 2022)
This my reading note on Zero-Shot Text-to-Image Generation (aka, DALL-E), its extension Hierarchical Text-Conditional Image Generation with CLIP Latents (aka, DALLE-2 or unCLIP) and StoryDALL-E: Adapting Pretrained Text-to-Image Transformers for Story Continuation. DALL-E is a transformer generating image given captions, by autoregressively modeling the text and image tokens as a single stream of data. StoryDALL-E extends DALL-E by generating a sequence of images for a sequence of caption to complete a story.
- CLIP Learning Transferable Visual Models From Natural Language Supervision (27 Sep 2022)
This my reading note on Learning Transferable Visual Models From Natural Language Supervision. The proposed method is called Contrastive Language-Image Pre-training or CLIP. State-of-the-art computer vision systems are trained to predict a fixed set of predetermined object categories. We demonstrate that the simple pre-training task of predicting which caption (freeform text instead of strict labeling) goes with which image is an efficient and scalable way to learn SOTA image representations from scratch on a dataset of 400 million (image, text) pairs collected from the internet. After pre-training, natural language is used to reference learned visual concepts (or describe new ones) enabling zero-shot transfer of the model to downstream tasks.
- Recent Adavances of Diffusion Models (24 Sep 2022)
This is my 4th note in Diffusion models. For the previous notes, please refer to diffusion and stable diffusion. My contents are based on paper listed in Diffusion Explained and Diffusion Models: A Comprehensive Survey of Methods and Applications.
- unCLIP-Hierarchical Text-Conditional Image Generation with CLIP Latents (23 Sep 2022)
This is my reading note on Hierarchical Text-Conditional Image Generation with CLIP Latents. This paper proposes a two-stage model (unCLIP): a prior that generates a CLIP image embedding given a text caption, and a decoder that generates an image conditioned on the image embedding, for generating images from text.