Tag: multimodal
Multimodal learning is an approach in machine learning and artificial intelligence that involves processing and integrating information from multiple modes or sources, such as text, images, audio, or other types of data. The goal is to leverage the complementary nature of these different data types to improve understanding, reasoning, and decision-making. This can be particularly useful in tasks like sentiment analysis, where both text and image data can provide richer context and more accurate results when combined. Multimodal learning techniques typically involve specialized models and algorithms that can effectively fuse and learn from diverse data sources to enhance the performance of AI systems.- Inject Semantic Concepts into Image Tagging for Open-Set Recognition (16 Nov 2023)
This is my reading note for Inject Semantic Concepts into Image Tagging for Open-Set Recognition. This paper proposes an image tagging method based on CLIP. The major innovation is the introduction of image tag alignment loss which aligns image feature to the tag description feature. The tag descriptor is generated by LLM to describe the tog in a few sentences
- SAM-CLIP Merging Vision Foundation Models towards Semantic and Spatial Understanding (15 Nov 2023)
This is my reading note for SAM-CLIP: Merging Vision Foundation Models towards Semantic and Spatial Understanding. This paper proposes a method to combine clip and Sam to perform zero shot semantic segmentation. To combined model merges the vision encoder of Sam and clip, but freezes the other encoders and heads. To avoid catastrophe forgetting, The paper uses two stage method, in first stage, only CLIP’S head is fine tuned; in second stage, the shared vision encode and two heads are fine tuned in a multi task way.
- Florence-2 Advancing a Unified Representation for a Variety of Vision Tasks (14 Nov 2023)
This is my reading note for Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks. This paper proposes to unify different vision tasks by formulating them as visual grounded text generation problem where vision task is specified as input text prompt. To this end, it annotates a large image dataset with different annotations.
- Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V (13 Nov 2023)
This is my reading note for Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V. This paper demonstrates how to combine the Sam with gpt-4v to perform more fine grained visual understanding of visual data. To this end, the paper first uses Sam to annotate the image with region marks and number. GPT-4V is then promoted to understand the image with those annotations.
- Chatting Makes Perfect Chat-based Image Retrieval (12 Nov 2023)
This is my reading note for [Chatting Makes Perfect: Chat-based Image Retrieval]. This paper proposes a method on using dialog (questions and answer pairs) to improve text based image retrieval. It experimented with different questioners (human, chatGPT and other LLM) and different answers (human, BLIP2). It showed that, dialog could significantly improves the retrieval performance. However, only chatGPT and human questioners could improve performance with more rounds of conversation.
- mPLUG-Owl2 Revolutionizing Multi-modal Large Language Model with Modality Collaboration (11 Nov 2023)
This is my reading note for mPLUG-Owl2: Revolutionizing Multi-modal Large Language Model with Modality Collaboration. This paper proposes a method to unify visual and text data for multi modal model. To this end, it uses QFormer to extract visual information and concatenate to text and feed to LLM. However, it separates the projection layer and layer norm for visual and text. This paper is similar to COGVLM.
- CogVLM Visual Expert for Pretrained Language Models (10 Nov 2023)
This is my reading note for CogVLM: Visual Expert for Pretrained Language Models. This paper proposes a vision language model similarly to mPLUG-OWL2. To avoid impacting the performance of LLM, it proposes a visual adapter which adds visual specific projection layer to each attention and feed forward layer.
- CoVLM Composing Visual Entities and Relationships in Large Language Models Via Communicative Decoding (07 Nov 2023)
This is my reading note for CoVLM: Composing Visual Entities and Relationships in Large Language Models Via Communicative Decoding. This paper proposes a vision language model to improve the capabilities of modeling composition relationship of objects across visual and text. To do that, it interleaves between language model generating special tokens and vision object detector detecting objects from image.
- TEAL Tokenize and Embed ALL for Multi-modal Large Language Models (06 Nov 2023)
This is my reading note for TEAL: Tokenize and Embed ALL for Multi-modal Large Language Models. This paper proposes a method of adding multi modal input and output capabilities to the existing LLM. To this end, it utilizes VQVAE and whisper to tokenize the image and audio respectively. Only The embedded and projection layer is trained . The result is not SOTA.
- VAST A Vision-Audio-Subtitle-Text Omni-Modality Foundation Model and Dataset (03 Nov 2023)
This is my reading note for VAST: A Vision-Audio-Subtitle-Text Omni-Modality Foundation Model and Dataset. This paper proposes a method and a dataset for multimodal content understanding for video (vision, audio, subtitle and text). The major contribution is it proposes to use LLM to fuse different sources of text data (caption, subtitle, ASR text).
- TiC-CLIP Continual Training of CLIP Models (02 Nov 2023)
This is my reading note for TiC-CLIP: Continual Training of CLIP Models. This paper studies the problem of how a model performs as the dataset evolve over time. It then proposes the best solutions base on benchmark, which is fine tuned the existing model on the whole dataset, include both new and old data.
- CapsFusion Rethinking Image-Text Data at Scale (30 Oct 2023)
This is my reading note for CapsFusion: Rethinking Image-Text Data at Scale. The paper studies the quality of caption data in vision language dataset and shown the simple caption limits the performance of the trained model. The caption of those dataset is generated synthetic and filter out a lot of real would knowledge. As a result, the paper proposes to use chatGPT to combine the synthetic caption and raw caption to generates a better caption. It’ then results in a much
- Battle of the Backbones A Large-Scale Comparison of Pretrained Models across Computer Vision Tasks (29 Oct 2023)
This is my reading note for Battle of the Backbones: A Large-Scale Comparison of Pretrained Models across Computer Vision Tasks. This paper benchmarks different vision backbones and found that supervised ConvNext may show best performance. After it, supervised swin-transformer and clip based transformer is also very competitive. Different vision tasks shows highly correlated performance for different backbones.
- A Picture is Worth a Thousand Words Principled Recaptioning Improves Image Generation (28 Oct 2023)
This is my reading note for A Picture is Worth a Thousand Words: Principled Recaptioning Improves Image Generation. The papers found that the text data used to train text to image model is now quality, which is based alt text of images.it proposed to use an image caption model to generate high quality text for the images; then the diffusion model trained from this new text data show much better performance.
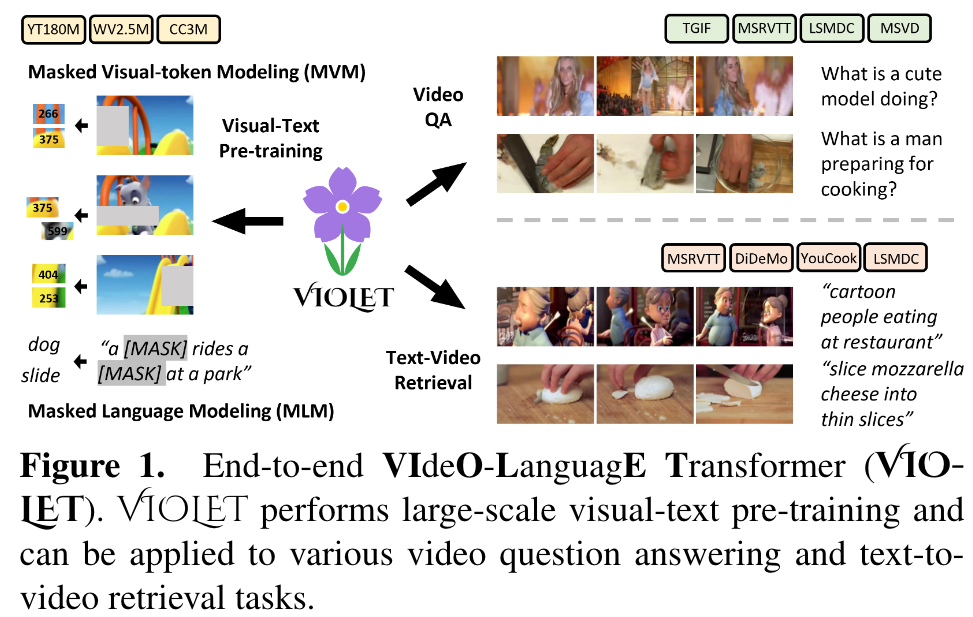
- VIOLET End-to-End Video-Language Transformers with Masked Visual-token Modeling (27 Oct 2023)
This is my reading note for VIOLET : End-to-End Video-Language Transformers with Masked Visual-token Modeling. This paper proposes a method to pre-train video-text model. The paper has two major innovations 1) use video SWIN transformer to extract the temporal features; 2) uses VQVAE to extract visual tokens and apply mask recovery on the tokens.
- Flamingo a Visual Language Model for Few-Shot Learning (26 Oct 2023)
This is my reading note for Flamingo: a Visual Language Model for Few-Shot Learning. This paper proposes to formulate vision language model vs text prediction task given existing text and visual. The model utilizes frozen visual encoder and LLM, and only fine tune the visual adapter (perceiver). The ablation study strongly against fine tune/retrain those components.
- MM-VID Advancing Video Understanding with GPT-4V(ision) (25 Oct 2023)
This is my reading note for MM-VID: Advancing Video Understanding with GPT-4V(ision). The paper proposes a system of understanding long video based on GPT 4V. To this end it first converts long video to short clips and pass every frames of clips to GPT 4V to generate text description. This description, together with audio transcription, is then ted to GPT 4U for final video understand. The analyst is based user ratings between normal vision subjects and vision impaired subjects.
- Florence A New Foundation Model for Computer Vision (24 Oct 2023)
This is my reading note for Florence: A New Foundation Model for Computer Vision. This paper proposes a foundation model for vision (image/video) and text based on UniCL loss. It uses Swin-transformer and Roberta for the encoder.
- Unified Contrastive Learning in Image-Text-Label Space (23 Oct 2023)
This is my reading note for Unified Contrastive Learning in Image-Text-Label Space. This paper proposes to combine label in image-text contrast loss. It treats the image or text from the same labels are from the same class and thus is required to have higher similarity; in contrast loss of CLIP, image/text is required to be similar if they are from the same pair.
- OmniVL One Foundation Model for Image-Language and Video-Language Tasks (22 Oct 2023)
This is my reading note for OmniVL:One Foundation Model for Image-Language and Video-Language Tasks. The paper proposes a vision language pre-training method optimized to linear probe for classification problem. To this end, it modifies the contrast loss by creating positive. samples from the images of same label class.
- VPA Fully Test-Time Visual Prompt Adaptation (21 Oct 2023)
This is my reading note for VPA: Fully Test-Time Visual Prompt Adaptation. VPA introduces a small number of learnable tokens, enabling fully test-time and storage-efficient adaptation without necessitating source-domain information.
- Video Language Planning (20 Oct 2023)
This is my reading note for Video Language Planning. This paper proposes to combine a video-language model and text to video generation model for visual planning: video-language models creates a execution plan given an image as current state and a text as the goal; text-to-video generation model generates a video given the plan; finally video-language models validated the plan via the generated videos.
- Filtering, Distillation, and Hard Negatives for Vision-Language Pre-Training (19 Oct 2023)
This is my reading note for Filtering, Distillation, and Hard Negatives for Vision-Language Pre-Training. This paper proposes several methods to improve image-text model pre-training: 1) filtering the dataset according complexity, action and text spotting (CAT); 2) concept distillation (object category and attributes); 3) hard negative mining for contrast pairs.
- InstructBLIP Towards General-purpose Vision-Language Models with Instruction Tuning (17 Oct 2023)
This is my reading note for InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning. The paper proposes an extension of blip 2 with institution tuning. This has dramatically improved the performance to unseen tasks. The method is based on query transformer, but adding the tokens from the instruction to guide the feature extraction.
- GIT A Generative Image-to-text Transformer for Vision and Language (16 Oct 2023)
This is my reading note for GIT: A Generative Image-to-text Transformer for Vision and Language. This paper proposes a image-text pre-training model. The model contains visual encoder and text decoder; the text decoder is based on self-attention, which takes concatenated text tokens and visual tokens as input.
- PaLI-3 Vision Language Models Smaller, Faster, Stronger (15 Oct 2023)
This is reading note for PaLI-3 Vision Language Models: Smaller, Faster, Stronger. This paper proposes to use image-text-matching to replace contrast loss. The experiment indicates this method is especially effective in relatively small models.
- Idea2Img Iterative Self-Refinement with GPT-4V(ision) for Automatic Image Design and Generation (14 Oct 2023)
This is my reading note for Idea2Img: Iterative Self-Refinement with GPT-4V(ision) for Automatic Image Design and Generation. This paper proposes a system on how to use GPT4V to generate images from idea by calling an image generation tool. Especially.it generates text prompt based on idea, given the images generated from the prompt, it ranks and selects the best image; it then generate a new promote to guide image generation process.
- Align before Fuse Vision and Language Representation Learning with Momentum Distillation (11 Oct 2023)
This is my reading note for Align before Fuse: Vision and Language Representation Learning with Momentum Distillation. The paper proposes a multi modality model which is trained base on contrast loss, mask language modeling and image-text match. To handle noisy pairs of text and image, it track moving average of model and distill to the final model.
- A Comprehensive Survey on Multimodal Recommender Systems Taxonomy, Evaluation, and Future Directions (08 Oct 2023)
This is my reading note for A Comprehensive Survey on Multimodal Recommender Systems: Taxonomy, Evaluation, and Future Directions. This paper provides a review for multimodality recommendation system. However, it doesn’t cover the method based on transformer. It still provides a good review on the metric of recommendation system.
- Leveraging Unpaired Data for Vision-Language Generative Models via Cycle Consistency (04 Oct 2023)
This is my reading note for Leveraging Unpaired Data for Vision-Language Generative Models via Cycle Consistency. The papers proposes a method to train a multi modality model between text and image. Especially, the paper propose cycle consistency loss to leverage unpaired text and image: use image to generate text and use text to recover image and vice verse. It reminds me cycle-GAN paper.
- An Early Evaluation of GPT-4V(ision) (03 Oct 2023)
This is my reading note for An Early Evaluation of GPT-4V(ision). The highlights of our findings are as follows:
- GPT-4V exhibits impressive performance on English visual-centric benchmarks but fails to recognize simple Chinese texts in the images;
- GPT-4V shows inconsistent refusal behavior when answering questions related to sensitive traits such as gender, race, and age;
- GPT-4V obtains worse results than GPT-4 (API) on language understanding tasks including general language understanding benchmarks and visual commonsense knowledge evaluation benchmarks;
- Few-shot prompting can improve GPT-4V’s performance on both visual understanding and language understanding;
- GPT-4V struggles to find the nuances between two similar images and solve the easy math picture puzzles;
- GPT-4V shows non-trivial performance on the tasks of similar modalities to image, such as video and thermal. O (p. 1)
- Aligning Large Multimodal Models with Factually Augmented RLHF (02 Oct 2023)
This is my reading note for Aligning Large Multimodal Models with Factually Augmented RLHF. This paper discusses how to mitigate hallucination for large multimodal model.it proposes two methods, 1) add additional human labeled data to train a reward model to guide the fine tune of the final model: 2) add additional factual data to the reward model besides model’s response.
- DeepSpeed-VisualChat Multi-Round Multi-Image Interleave Chat via Multi-Modal Causal Attention (01 Oct 2023)
This is my reading note for DeepSpeed-VisualChat: Multi-Round Multi-Image Interleave Chat via Multi-Modal Causal Attention. This paper proposes a method for multi round multi-image multi modality model. The paper utilizes a frozen LLM and visual encoder. The contribution of the paper includes: 1. Casual cross attention method to combine image and multiround text; 2. A new dataset.
- Demystifying CLIP Data (30 Sep 2023)
This is my reading note for Demystifying CLIP Data. This paper reverse engineered the data of CLIP and replicated even outperformed the CLIP.
- Video-ChatGPT Towards Detailed Video Understanding via Large Vision and Language Models (26 Sep 2023)
This is my reading note for ideo-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models. The paper extends chatGPT to understand the video. It’s based on LLAVA and CLIP. One of the key contribution is that is spatially and temporal pool the per frame visual feature from the clip visual encoder and finally concatenate them as features a video.
- VideoChat Chat-Centric Video Understanding (25 Sep 2023)
This is my reading note for VideoChat: Chat-Centric Video Understanding. The papers extends chatGPT to understand the video. To this end.it develops a video backbone based on BLIP2
- MaMMUT A Simple Architecture for Joint Learning for MultiModal Tasks (24 Sep 2023)
This is my reading note for MaMMUT: A Simple Architecture for Joint Learning for MultiModal Tasks. The paper proposes an efficient multi modality model. it proposes to unify generative loss (masked language modeling) and contrast loss via a two pass training process. One pass is for generate loss which utilizes casual attention model in text decoder and the other pass is bidirectional text decoding. The order of two passes are shuffled during the training.
- Scaling Vision Transformers (23 Sep 2023)
This is my reading note for Scaling Vision Transformers. This paper provides a detailed comparison and study of designing vision transformer.
- Coarse-to-Fine Vision-Language Pre-training with Fusion in the Backbone (22 Sep 2023)
This is my reading note for Coarse-to-Fine Vision-Language Pre-training with Fusion in the Backbone. This papers propose a two-stage pre-training strategy: (i) coarse-grained pre-training based on image-text data; followed by (ii) fine-grained pre-training based on image-text-box data.
- An Empirical Study of Training End-to-End Vision-and-Language Transformers (21 Sep 2023)
This is my reading note for An Empirical Study of Training End-to-End Vision-and-Language Transformers. This paper provides a good review and comparison of multi modality (video and text) model’s design choice.
- NExT-GPT Any-to-Any Multimodal LLM (16 Sep 2023)
This is my reading note for NExT-GPT: Any-to-Any Multimodal LLM. This paper proposes a multiple modality model which could takes multiple modalities as input and output in multiple modalities as well. The paper leverage existing large language model, multiple modality encoder image bind) and multiple modality diffusion model. To Amish the spice of those components, a simple linear projection is used for input and transformer to the output.
- Mobile V-MoEs Scaling Down Vision Transformers via Sparse Mixture-of-Experts (14 Sep 2023)
This is my reading note for Mobile V-MoEs Scaling Down Vision Transformers via Sparse Mixture-of-Experts. This paper proposes a new mixture of experts to reduce the cost of vision transformer. There are two contributions, I) use image level instead of patch level mixture to reduce cost; 2) use super class based router to select experts so each expert could focus on a few related class.
- InstructDiffusion A Generalist Modeling Interface for Vision Tasks (10 Sep 2023)
This is my reading note for InstructDiffusion: A Generalist Modeling Interface for Vision Tasks. This paper formulated many vision tasks like segmentation and key point detection as text guided image edit task, and thus can be modeled by diffusion based image edit model. To to that, this paper collects a dataset of different vision tasks, each item contains source image, vision task as text prompt and target image as vision results.
- SeamlessM4T-Massively Multilingual & Multimodal Machine Translation (05 Sep 2023)
This is my reading note 2/2 on SeamlessM4T-Massively Multilingual & Multimodal Machine Translation. It is end to end multi language translation system supports multimodality (text and audio). This paper also provides a good review on machine translation. This note focus on data preparation part of the paper and please read SeamlessM4T-data for the other part.
- SeamlessM4T-Massively Multilingual & Multimodal Machine Translation (04 Sep 2023)
This is my reading note 1/2 on SeamlessM4T-Massively Multilingual & Multimodal Machine Translation. It is end to end multi language translation system supports multimodality (text and audio). This paper also provides a good review on machine translation. This note focus on data preparation part of the paper and please read SeamlessM4T-model for the other part.
- Multimodal Learning with Transformers A Survey (02 Sep 2023)
This is my reading note on Multimodal Learning with Transformers A Survey. This a paper provides a very nice overview of the transformer based multimodality learning techniques.
- MovieChat From Dense Token to Sparse Memory for Long Video Understanding (30 Aug 2023)
This is my reading note on MovieChat: From Dense Token to Sparse Memory for Long Video Understanding. This paper proposes a method for long video understands it utilizes existing image encoder to extract tokens form the video via sliding window. A short term memory is a FIFO of those tokens, a long term memory is to merge the similar tokens. Those short term memory and long term memory are then appended after the question and feed to the LLM. The alignment of visual features to LLM purely depends on the existing image encoder.
- Unified Model for Image, Video, Audio and Language Tasks (16 Aug 2023)
This is my reading note on Unified Model for Image, Video, Audio and Language Tasks. This paper proposes a data and compute efficient method to train multi modality model. It’s based on multi-stage and multi task learning: in each stage new modality will be added and the model will be initialized from previous stage.
- Link-Context Learning for Multimodal LLMs (13 Aug 2023)
This is my meeting note for Link-Context Learning for Multimodal LLMs. It presents a demo of how to use positive and negative example to tell L L m to recognize novel concept.
- AVIS Autonomous Visual Information Seeking with Large Language Models (12 Aug 2023)
This is my reading note on AVIS Autonomous Visual Information Seeking with Large Language Models. The paper proposes a method on how to use L lm to use tools or APIs to solve different visual questions. The biggest contribution is this page collect how seal human uses the same set of tools and APIs to solve different visual question. The collected data generates a translation graph between states and action to take.
- MusicLM Generating Music From Text (09 Aug 2023)
This is my reading note on MusicLM: Generating Music From Text. The paper is mostly extended AudioLM to generate the music from text. To do this it utilizes two off shelf models to provide semantic information of audio and to project text to embed ding of the some space of audio
- SimVLM Simple Visual Language Model Pretraining with Weak Supervision (07 Aug 2023)
This is my reading note for SimVLM: Simple Visual Language Model Pretraining with Weak Supervision. SimVLM reduces the training complexity by exploiting large-scale weak supervision, and is trained end-to-end with a single prefix language modeling objective
- InternVideo General Video Foundation Models via Generative and Discriminative Learning (06 Aug 2023)
This is my reading note for InternVideo: General Video Foundation Models via Generative and Discriminative Learning. This paper propose to train a multi-modality model for video by utilizes both masked video prediction and contrast loss. However, this paper uses a encoder-decoder for masked video prediction and the other video encoder for contrast loss
- Image as a Foreign Language BEiT Pretraining for All Vision and Vision-Language Tasks (05 Aug 2023)
This is my reading note for Image as a Foreign Language BEiT Pretraining for All Vision and Vision-Language Tasks. The paper proposes a multi modality model which models image data as foreign language and propose only to use masked language models as the pre-train tasks.
- BLIP-2 Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models (04 Aug 2023)
This is my reading note for BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models. The paper propose Q former to align the visual feature to text feature. Both visual feature and text feature are extracted from fixed models. Q former learned query and output the visual embeds to the text space.
- DualToken-ViT Position-aware Efficient Vision Transformer with Dual Token Fusion (03 Aug 2023)
This is my reading note for DualToken-ViT Position-aware Efficient Vision Transformer with Dual Token Fusion. The paper discuss efficient transformer, which is based on combining convolution with attention: where convolution extracts local information and then fused with global information via attention.
- Visual Instruction Tuning (02 Aug 2023)
This is my reading note for Visual Instruction Tuning. The paper exposes a method to train a multi-modality model - that woks like chat GPT. This is achieved by building an instruction following dataset that’s paired with images. The model is then trained on this dataset.
- CoCa Contrastive Captioners are Image-Text Foundation Models (31 Jul 2023)
This is my reading note for CoCa: Contrastive Captioners are Image-Text Foundation Models. The paper proposes a multi modality model, especially it models the problem as image caption as well as text alignment problem. The model contains three component: a vision encoder, a text decoder (which generates text embedding ) and a multi modality decoder , which generate caption given image and text embedding.
- FLAVA A Foundational Language And Vision Alignment Model (30 Jul 2023)
This is my reading note for FLAVA: A Foundational Language And Vision Alignment Model. This paper proposes a multi modality model. Especially, the model not only work across modality, but also on each modality and joint modality. To do that, it contains loss functions for both within modality but also across modality. It also proposes to use the same architecture for vision encoder, Text encoder as well as multi -modality encoder.
- AutoCLIP Auto-tuning Zero-Shot Classifiers for Vision-Language Models (29 Jul 2023)
This is my reading note for AutoCLIP: Auto-tuning Zero-Shot Classifiers for Vision-Language Models. This paper proposes a method to use clip for zero shot image classification, to do that, it first generates several prompt to convert class label to text embedding by average. Then the image is processed by visual encoder. The label of image is the one has slowest distance between label embody and image embedding. This paper propose to use soft Max instead of average for label embedding.
- Jointly Training Large Autoregressive Multimodal Models (28 Jul 2023)
This is my reading note for Jointly Training Large Autoregressive Multimodal Models. This paper proposes a multimodality model for generating images. The paper is not just dilution based method but instead auto regressive method.it argues to initialize the model from the weight of frozen models.
- AudioGen Textually Guided Audio Generation (24 Jul 2023)
This is my reading note for AudioGen: Textually Guided Audio Generation. This paper propose to use auto regressive model to generate audio condition on text. The audio presentation is based on sound stream on neural sound.
- Make-An-Audio Text-To-Audio Generation with Prompt-Enhanced Diffusion Models (23 Jul 2023)
This is my reading note for Make-An-Audio: Text-To-Audio Generation with Prompt-Enhanced Diffusion Models. This paper proposes a diffusion model for audio, which uses an auto encoder to convert audio signal to a spectrum which could be natively handled by latent diffusion method.
- Improved Baselines with Visual Instruction Tuning (22 Jul 2023)
This is my reading note for Improved Baselines with Visual Instruction Tuning. This paper shows how to improve the performance of LLAVA with simple methods.
- Large-scale Multi-Modal Pre-trained Models A Comprehensive Survey (21 Jul 2023)
This is my reading note for Large-scale Multi-Modal Pre-trained Models: A Comprehensive Survey. It provides an OK review for multimodality pre-trained models without diving too much into details.
- Vision-Language Intelligence Tasks, Representation Learning, and Large Models (20 Jul 2023)
This is my reading note for Vision-Language Intelligence: Tasks, Representation Learning, and Large Models. It is yet another review paper for pre-trained vision-language model. Check my reading note for another review paper in Large-scale Multi-Modal Pre-trained Models A Comprehensive Survey
- MUGEN A Playground for Video-Audio-Text Multimodal Understanding and GENeration (16 Jul 2023)
This is my reading note for MUGEN: A Playground for Video-Audio-Text Multimodal Understanding and GENeration. In this paper, we introduce MUGEN, a large-scale controllable video-audio- text dataset with rich annotations for multimodal understanding and generation.
- MDETR -Modulated Detection for End-to-End Multi-Modal Understanding (16 Jul 2023)
This is my reading note for MDETR -Modulated Detection for End-to-End Multi-Modal Understanding. This paper proposes a method to learn object detection model from pairs of image and tree form text. The trained model is found to be capable of localizing unseen / long tail category.
- AnyMAL An Efficient and Scalable Any-Modality Augmented Language Model (15 Jul 2023)
This is my reading note for AnyMAL: An Efficient and Scalable Any-Modality Augmented Language Model. The papa proposes a multi modality model which uses a projection layer to align the features of frozen modality encoder to the space of frozen LLM
- BLIP Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation (12 Jul 2023)
This is my reading note for BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation. This paper proposed a multi model method. There are two contribution: 1) it utilizes a mixture of text encoder/decoder for different loss where most parameters are shared except self attention: 2) it proposes a caption-filtering process to clean the nous web data.
- Octopus Embodied Vision-Language Programmer from Environmental Feedback (11 Jul 2023)
This is my reading note for Octopus: Embodied Vision-Language Programmer from Environmental Feedback. The paper proposes a method on how to leverage large language model and vision encoder to perform action in game to complete varying tasks.
- Qwen-VL A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond (09 Jul 2023)
This is my reading note for Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond. This paper proposes a vision-language model capable of vision grounding and image text reading. To do that, it considers visual grounding and OCR tasks in pre-training. In architecture, the paper uses Qformer from BLIP2.
- PaLI A Jointly-Scaled Multilingual Language-Image Model (08 Jul 2023)
This is my reading note for PaLI: A Jointly-Scaled Multilingual Language-Image Model. This paper formulates all the image-text pretraining tasks as visual question answering. The major contributions of this paper includes 1) shows balanced size of vision model and language model improves performances; 2) training with mixture of 8 tasks is important.
- Otter A Multi-Modal Model with In-Context Instruction Tuning (05 Jul 2023)
This is my reading note for Otter: A Multi-Modal Model with In-Context Instruction Tuning. It is a replication of Flamingo model trained on MIMIC-IT: Multi-Modal In-Context Instruction Tuning.
- X-CLIP End-to-End Multi-grained Contrastive Learning for Video-Text Retrieval (04 Jul 2023)
This is my reading note for X-CLIP: End-to-End Multi-grained Contrastive Learning for Video-Text Retrieval. This paper proposes a method on extending clip to video data. it mostly studied how to aggregate the similarity score from the frame level to video level.
- Scaling Autoregressive Multi-Modal Models Pretraining and Instruction Tuning (01 Jul 2023)
This is my reading note for Scaling Autoregressive Multi-Modal Models: Pretraining and Instruction Tuning. This paper proposes a method for text to image generation which is NOT based on diffusion. It utilizes auto-regressive model on tokens.
- Grounding Visual Illusions in Language Do Vision-Language Models Perceive Illusions Like Humans? (29 Jun 2023)
This is my reading note for Grounding Visual Illusions in Language: Do Vision-Language Models Perceive Illusions Like Humans?. This paper shows that larger model though more powerful, also more vulnerable to vision illusion as human does.
- Language Is Not All You Need Aligning Perception with Language Models (25 Jun 2023)
This is my reading note for Language Is Not All You Need: Aligning Perception with Language Models. This paper proposes a multimodal LLM which feeds the visual signal as a sequence of embedding, then combines with text embedding and trains in a GPT like way.
- UNITER UNiversal Image-TExt Representation Learning (24 Jun 2023)
This is my reading note for UNITER: UNiversal Image-TExt Representation Learning. This paper proposes a vision language pre training model. The major innovation here is it studies the work region alignment loss as well as different mask region models task.
- SEED-Bench Benchmarking Multimodal LLMs with Generative Comprehension (23 Jun 2023)
This is my reading note for SEED-Bench: Benchmarking Multimodal LLMs with Generative Comprehension. This paper proposes a benchmark suite of modality LLM. It introduces how is the data created and how is the task derived. For evaluation, it utilizes the model’s output of likelihood of answers instead of directly on text answers.
- Scaling Laws for Generative Mixed-Modal Language Models (22 Jun 2023)
This is my reading note for Scaling Laws for Generative Mixed-Modal Language Models. This paper provides a study of scaling raw on dataset size and model size in multimodality settings.
- Tag2Text Guiding Vision-Language Model via Image Tagging (21 Jun 2023)
This is my reading note for Tag2Text: Guiding Vision-Language Model via Image Tagging. This paper proposes to add tag recognition to vision language model and shows improved performance.
- MEGAVERSE Benchmarking Large Language Models Across Languages, Modalities, Models and Tasks (20 Jun 2023)
This is my reading note for MEGAVERSE: Benchmarking Large Language Models Across Languages, Modalities, Models and Tasks. This paper proposes a new multilingual benchmark to test LLM and provides very limited dataset for multimodality. The language distribution is also strange which houses to much on south, Asia. Overall GPT and Palm get the best performance.